Язык программирования Rust
Авторы: Стив Клабник, Кэрол Николс и Крис Кричо, при участии сообщества Rust
Данная версия текста предполагает, что вы используете Rust 1.85.0 (выпущен 2025-02-17) или новее с edition = "2024" в файле Cargo.toml всех проектов для настройки их на использование идиом Rust 2024 Edition. Инструкции по установке или обновлению Rust см. в разделе «Установка» главы 1, а информацию о редакциях — в Приложении E.
Версия в формате HTML доступна онлайн по адресу https://doc.rust-lang.org/stable/book/ и офлайн при установке Rust с помощью rustup; выполните rustup doc --book, чтобы открыть.
Также доступны несколько переводов, выполненных сообществом.
Данный текст доступен в мягкой обложке и в электронном формате от No Starch Press.
🚨 Хотите более интерактивный опыт обучения? Попробуйте другую версию Книги по Rust, включающую: викторины, выделение, визуализации и многое другое: https://rust-book.cs.brown.edu
Предисловие
Язык программирования Rust прошёл долгий путь за несколько коротких лет: от создания и развития небольшой зарождающейся группой энтузиастов до становления одним из самых любимых и востребованных языков программирования в мире. Оглядываясь назад, можно сказать, что было неизбежным, что мощь и перспективность Rust привлекут внимание и закрепятся в системном программировании. Что не было неизбежным, так это глобальный рост интереса и инноваций, который проник через сообщества открытого исходного кода и catalyzed широкомасштабное внедрение across отраслей. На данном этапе легко указать на замечательные возможности, которые предлагает Rust, чтобы объяснить этот взрыв интереса и внедрения. Кто не хочет безопасность памяти, и высокую производительность, и дружелюбный компилятор, и отличные инструменты, среди множества других замечательных возможностей? Язык Rust, который вы видите сегодня, сочетает годы исследований в области системного программирования с практической мудростью яркого и страстного сообщества. Этот язык был разработан с целью и создан с заботой, предлагая разработчикам инструмент, который позволяет легче писать безопасный, быстрый и надёжный код.
Но что делает Rust по-настоящему особенным, так это его корни в расширении ваших возможностей, пользователь, для достижения ваших целей. Это язык, который хочет, чтобы вы преуспели, и принцип расширения возможностей проходит через ядро сообщества, которое создаёт, поддерживает и отстаивает этот язык. С момента выхода предыдущего издания этого авторитетного текста Rust еще больше эволюционировал и стал по-настоящему глобальным и надежным языком. Проект Rust теперь активно поддерживается Rust Foundation, которая также инвестирует в ключевые инициативы, направленные на обеспечение безопасности, стабильности и устойчивости Rust.
Это издание «Языка программирования Rust» представляет собой всестороннее обновление, отражающее эволюцию языка за годы и предоставляющее ценную новую информацию. Но это не просто руководство по синтаксису и библиотекам — это приглашение присоединиться к сообществу, которое ценит качество, производительность и продуманный дизайн. Независимо от того, являетесь ли вы опытным разработчиком, впервые исследующим Rust, или опытным Rustacean, желающим отточить свои навыки, это издание предлагает что-то для каждого.
Путь Rust был путём сотрудничества, обучения и итераций. Рост языка и его экосистемы является прямым отражением яркого, разнообразного сообщества, стоящего за ним. Вклад тысяч разработчиков, от основных дизайнеров языка до случайных участников, — это то, что делает Rust таким уникальным и мощным инструментом. Взяв эту книгу в руки, вы не просто изучаете новый язык программирования — вы присоединяетесь к движению, чтобы сделать программное обеспечение лучше, безопаснее и приятнее в работе.
Добро пожаловать в сообщество Rust!
Бек Рамбул, Исполнительный директор Фонда Rust
Введение
Примечание: данное издание книги соответствует книге «Язык программирования Rust», доступной в печатном и электронном формате от издательства No Starch Press.
Добро пожаловать в «Язык программирования Rust», вводную книгу о Rust. Язык программирования Rust помогает вам писать более быстрое и надежное программное обеспечение. Высокоуровневая эргономика и низкоуровневый контроль часто противоречат друг другу в дизайне языков программирования; Rust бросает вызов этому противоречию. Благодаря балансу между мощными техническими возможностями и отличным опытом разработчиков, Rust дает вам возможность контролировать низкоуровневые детали (такие как использование памяти) без всех сложностей, традиционно связанных с таким контролем.
Для кого предназначен Rust
Rust идеально подходит для многих людей по разным причинам. Давайте рассмотрим несколько наиболее важных групп.
Команды разработчиков
Rust доказал свою эффективность как инструмент для сотрудничества между большими командами разработчиков с разным уровнем знаний в области системного программирования. Низкоуровневый код подвержен различным тонким ошибкам, которые в большинстве других языков можно обнаружить только путем обширного тестирования и тщательной проверки кода опытными разработчиками. В Rust компилятор играет роль «стража», отказываясь компилировать код с этими неуловимыми ошибками, включая ошибки параллелизма. Работая вместе с компилятором, команда может сосредоточить свое время на логике программы, а не на поиске ошибок.
Rust также привносит современные инструменты разработчиков в мир системного программирования:
- Cargo, встроенный менеджер зависимостей и инструмент сборки, делает добавление, компиляцию и управление зависимостями простыми и последовательными во всей экосистеме Rust.
- Инструмент форматирования rustfmt обеспечивает единый стиль кодирования для всех разработчиков.
- Rust Language Server обеспечивает интеграцию с интегрированной средой разработки (IDE) для автодополнения кода и встроенных сообщений об ошибках.
Используя эти и другие инструменты в экосистеме Rust, разработчики могут быть продуктивными при написании кода системного уровня.
Студенты
Rust предназначен для студентов и тех, кто интересуется изучением системных концепций. Используя Rust, многие люди изучили такие темы, как разработка операционных систем. Сообщество очень гостеприимно и с удовольствием отвечает на вопросы студентов. Благодаря таким усилиям, как эта книга, команды Rust хотят сделать системные концепции более доступными для большего числа людей, особенно для тех, кто только начинает программировать.
Компании
Сотни компаний, больших и малых, используют Rust в производстве для различных задач, включая инструменты командной строки, веб-сервисы, инструменты DevOps, встроенные устройства, анализ и транскодирование аудио и видео, криптовалюты, биоинформатику, поисковые системы, приложения Интернета вещей, машинное обучение и даже основные части веб-браузера Firefox.
Разработчики открытого исходного кода
Rust предназначен для людей, которые хотят создавать язык программирования Rust, сообщество, инструменты для разработчиков и библиотеки. Мы будем рады, если вы внесете свой вклад в развитие языка Rust.
Люди, которые ценят скорость и стабильность
Rust предназначен для людей, которые ценят скорость и стабильность языка. Под скоростью мы подразумеваем как скорость выполнения кода Rust, так и скорость, с которой Rust позволяет писать программы. Проверки компилятора Rust обеспечивают стабильность за счет добавления новых функций и рефакторинга. Это контрастирует с хрупким устаревшим кодом в языках без таких проверок, который разработчики часто боятся изменять. Стремясь к абстракциям с нулевой стоимостью — функциям более высокого уровня, которые компилируются в код более низкого уровня так же быстро, как и код, написанный вручную, — Rust стремится сделать безопасный код также быстрым.
Язык Rust надеется поддержать и многих других пользователей; упомянутые здесь — лишь некоторые из самых крупных заинтересованных сторон. В целом, главная цель Rust — устранить компромиссы, с которыми программисты мирились десятилетиями, обеспечив безопасность и производительность, скорость и эргономику. Попробуйте Rust и посмотрите, подходят ли вам его решения.
Для кого предназначена эта книга
Эта книга предполагает, что вы писали код на другом языке программирования, но не делает никаких предположений о том, на каком именно. Мы постарались сделать материал широко доступным для людей с самым разным опытом программирования. Мы не тратим много времени на обсуждение того, что такое программирование и как к нему подходить. Если вы совсем новичок в программировании, вам лучше прочитать книгу, которая специально посвящена введению в программирование. Как использовать эту книгу
В целом, эта книга предполагает, что вы читаете ее последовательно от начала до конца. Поздние главы основываются на концепциях, изложенных в предыдущих главах, а в предыдущих главах может не уделяться особое внимание деталям конкретной темы, но она будет повторно рассмотрена в более поздней главе.
В главе 1 объясняется, как установить Rust, как написать программу «Hello, world!» и как использовать Cargo, менеджер пакетов и инструмент сборки Rust.
Глава 2 представляет собой практическое введение в написание программ на Rust, в котором вы создадите игру «Угадай число». Здесь мы рассмотрим концепции на высоком уровне, а в последующих главах будут представлены дополнительные подробности. Если вы хотите сразу приступить к практической работе, вам подойдет глава 2.
Если вы особенно тщательный ученик и предпочитаете изучить все детали, прежде чем переходить к следующим, вы можете пропустить главу 2 и перейти сразу к главе 3, в которой рассматриваются функции Rust, схожие с функциями других языков программирования. Затем вы можете вернуться к главе 2, когда захотите поработать над проектом, применяя полученные знания.
В главе 4 вы узнаете о системе владения Rust.
В главе 5 обсуждаются структуры и методы.
Глава 6 посвящена перечислениям, выражениям match и конструкциям управления потоком if let и let...else. Вы будете использовать структуры и перечисления для создания пользовательских типов.
В главе 7 вы узнаете о системе модулей Rust и о правилах конфиденциальности для организации вашего кода и его публичного интерфейса прикладного программирования (API).
В главе 8 обсуждаются некоторые распространенные структуры данных коллекций, предоставляемые стандартной библиотекой: векторы, строки и хеш-карты.
В главе 9 исследуются философия и методы обработки ошибок в Rust.
В главе 10 подробно рассматриваются генератики, черты и сроки жизни, которые дают вам возможность определять код, применимый к нескольким типам.
Глава 11 посвящена тестированию, которое даже при гарантиях безопасности Rust необходимо для обеспечения правильности логики вашей программы.
В главе 12 мы создадим собственную реализацию подмножества функциональности командной строки grep, которая ищет текст в файлах. Для этого мы будем использовать многие концепции, которые обсуждали в предыдущих главах.
В главе 13 рассматриваются замыкания и итераторы: особенности Rust, заимствованные из функциональных языков программирования.
В главе 14 мы более подробно рассмотрим Cargo и поговорим о лучших практиках обмена библиотеками с другими.
В главе 15 обсуждаются умные указатели, предоставляемые стандартной библиотекой, и черты, обеспечивающие их функциональность.
В главе 16 мы рассмотрим различные модели параллельного программирования и поговорим о том, как Rust помогает вам без опасений программировать в нескольких потоках.
В главе 17 мы разберем синтаксис async и await в Rust, а также задачи, фьючерсы и потоки и облегченную модель параллелизма, которую они обеспечивают.
В главе 18 мы рассмотрим, как идиомы Rust соотносятся с принципами объектно-ориентированного программирования, с которыми вы, возможно, знакомы.
Глава 19 — это справочник по паттернам и сопоставлению паттернов, которые являются мощными способами выражения идей в программах Rust.
Глава 20 содержит набор интересных продвинутых тем, включая небезопасный Rust, макросы и более подробную информацию о сроках жизни, чертах, типах, функциях и замыканиях.
В главе 21 мы завершим проект, в котором реализуем низкоуровневый многопоточный веб-сервер!
Наконец, некоторые приложения содержат полезную информацию о языке в формате, более похожем на справочник.
Приложение A посвящено ключевым словам Rust,
приложение B — операторам и символам Rust,
приложение C — производным чертам, предоставляемым стандартной библиотекой,
приложение D — некоторым полезным инструментам разработки,
приложение E — объяснению версий Rust.
В приложении F вы найдете переводы книги,
приложении G мы расскажем, как создается Rust и что такое nightly Rust.
Нет неправильного способа чтения этой книги: если вы хотите пропустить что-то, смело делайте это! Возможно, вам придется вернуться к предыдущим главам, если вы что-то не поняли. Но делайте то, что подходит вам.
Важной частью процесса изучения Rust является обучение чтению сообщений об ошибках, отображаемых компилятором: они помогут вам создать рабочий код. Поэтому мы приведем много примеров, которые не компилируются, вместе с сообщениями об ошибках, которые компилятор будет отображать в каждой ситуации. Имейте в виду, что если вы введете и запустите случайный пример, он может не скомпилироваться! Обязательно прочтите сопутствующий текст, чтобы понять, должен ли пример, который вы пытаетесь запустить, вызывать ошибку. В большинстве случаев мы подскажем вам правильную версию любого кода, который не компилируется. Феррис также поможет вам отличить код, который не должен работать.
В большинстве случаев мы подскажем вам правильную версию любого кода, который не компилируется.
Исходный код
Исходные файлы, на основе которых создана эта книга, можно найти на GitHub.
Начало работы
Давайте начнём ваше путешествие в мир Rust! Вам предстоит многое узнать, но каждое путешествие начинается с первого шага. В этой главе мы обсудим:
- Установку Rust на Linux, macOS и Windows
- Написание программы, которая выводит
Hello, world! - Использование
cargo— менеджера пакетов и системы сборки Rust
Структура проекта
Крейт
Крейт — это наименьший объем кода, который компилятор Rust рассматривает за раз. Даже если вы запустите rustc вместо cargo и передадите один файл с исходным кодом (как мы уже делали в разделе «Написание и запуск программы на Rust» Главы 1), компилятор считает этот файл крейтом. Крейты могут содержать модули, и модули могут быть определены в других файлах, которые компилируются вместе с крейтом, как мы увидим в следующих разделах.
Бинарные крейты — это программы, которые вы можете скомпилировать в исполняемые файлы, которые вы можете запускать, например программу командной строки или сервер.
Библиотечные крейты не имеют функции main и не компилируются в исполняемый файл. Вместо этого они определяют функциональность, предназначенную для совместного использования другими проектами.
Корневой модуль крейта — это исходный файл, из которого компилятор Rust начинает собирать корневой модуль вашего крейта
Пакет
Пакет — это набор из одного или нескольких крейтов, предоставляющий набор функциональности. Пакет содержит файл Cargo.toml, в котором описывается, как собирать эти крейты.
Пакет может содержать сколько угодно бинарных крейтов, но не более одного библиотечного крейта. Пакет должен содержать хотя бы один крейт, библиотечный или бинарный.
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Модули
- при компиляции компилятор сначала ищет корневой модуль крейта (обычно это src/lib.rs для библиотечного крейта или src/main.rs для бинарного крейта) для компиляции кода.
- В файле корневого модуля крейта вы можете объявить новые модули с помощью
mod <имя модуля>; - Компилятор будет искать код модуля в следующих местах:
- в этом же файле, между фигурных скобок, которые заменяют точку с запятой после
mod <имя модуля> - в файле
src/<имя модуля>.rs - в файле
src/<имя модуля>/mod.rs
- в этом же файле, между фигурных скобок, которые заменяют точку с запятой после
Подмодули
В любом файле, кроме корневого модуля крейта, вы можете объявить подмодули.
Компилятор будет искать код подмодуля в каталоге с именем родительского модуля в следующих местах:
- в этом же файле, сразу после
mod <имя подмодуля>, между фигурных скобок, которые заменяют точку с запятой - в файле
src/<имя модуля>/<имя подмодуля>.rs - в файле
src/<имя модуля>/<имя подмодуля>/mod.rs
Пути к коду в модулях
тип Asparagus, в подмодуле vegetables модуля garden, будет найден по пути crate::garden::vegetables::Asparagus.
Объявление модуля
#![allow(unused)] fn main() { mod name //объявление модуля pub mod name //объявление публичного модуля }
Ключевое слово use
использование ключевого слова use создаёт псевдонимы для элементов
use crate::garden::vegetables::Asparagus позволяет использовать в коде просто Asparagus
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
use crate::garden::vegetables::Asparagus; pub mod garden; fn main() { let plant = Asparagus {}; println!("I'm growing {plant:?}!"); }
Код внутри модуля по умолчанию закрытый и обеспечивает приватность
Создание библиотечного крейта
Последовательность шагов
- Создать проект
cargo new restaurant --lib
- Вставить код в файл
src/lib.rs
#![allow(unused)] fn main() { mod front_of_house { mod hosting { fn add_to_waitlist() {} fn seat_at_table() {} } mod serving { fn take_order() {} fn serve_order() {} fn take_payment() {} } } }
- Дерево модулей
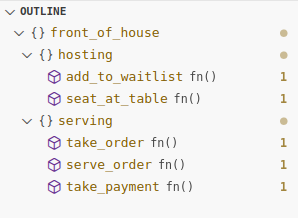
- Пути к элементам модулей
- абсолютный путь начинается с имени крейта
- абсолютный путь из текущего крейта начинается с
crate - относительный путь начинается с текущего модуля
selfиsuperили идентификатор
#![allow(unused)] fn main() { pub fn eat_at_restaurant() { // Absolute path crate::front_of_house::hosting::add_to_waitlist(); // Relative path front_of_house::hosting::add_to_waitlist(); } }
В Rust все элементы (функции, методы, структуры, перечисления, модули и константы) по умолчанию являются приватными для родительских модулей.
Элементы в родительском модуле не могут использовать приватные элементы внутри дочерних модулей, но элементы в дочерних модулях могут использовать элементы у своих модулях-предках.
- Добавим ключевое слово
pubдля модуля и функции, чтобы предоставить публичный доступ
Ключевое слово super
можно построить относительные пути, которые начинаются в родительском модуле, используя ключевое слово super в начале пути.
Использование super позволяет нам сослаться на элемент, который находится в родительском модуле.
#![allow(unused)] fn main() { fn deliver_order() {} mod back_of_house { fn fix_incorrect_order() { cook_order(); super::deliver_order(); } fn cook_order() {} } }
Общедоступные структуры и перечисления
использование
pubдля обозначения структур и перечислений как общедоступных
pub для структуры и элементов
Чтобы сделать публичными структуру, нужно объявить pub саму структуру и те элементы, которые выделяем в публичность1
#![allow(unused)] fn main() { mod back_of_house { pub struct Breakfast { pub toast: String, seasonal_fruit: String, } impl Breakfast { pub fn summer(toast: &str) -> Breakfast { Breakfast { toast: String::from(toast), seasonal_fruit: String::from("peaches"), } } } } pub fn eat_at_restaurant() { // Order a breakfast in the summer with Rye toast. let mut meal = back_of_house::Breakfast::summer("Rye"); // Change our mind about what bread we'd like. meal.toast = String::from("Wheat"); println!("I'd like {} toast please", meal.toast); // The next line won't compile if we uncomment it; we're not allowed // to see or modify the seasonal fruit that comes with the meal. // meal.seasonal_fruit = String::from("blueberries"); } }
Для enum
В отличии от структуры, если мы сделаем общедоступным перечисление, то все его варианты будут общедоступными. Нужно только указать pub перед ключевым словом enum
#![allow(unused)] fn main() { mod back_of_house { pub enum Appetizer { Soup, Salad, } } }
Note
Это пример сообщения
Example
This is a code example.
#![allow(unused)] fn main() { println!("hello world"); }
-
Нужно установить pub напротив каждого элемента структуры ↩
Создание псевдонимов use
#![allow(unused)] fn main() { use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); } }
useсоздаёт псевдоним только для той конкретной области, в которой это объявление use и находится
чтобы была видимость модуля можно переместить use в модуль видимости, или же можно сослаться на псевдоним в родительском модуле с помощью super::hosting из дочернего модулея customer.
Подключение одинаковых типов из разных модулей
#![allow(unused)] fn main() { use std::fmt; use std::io; fn function1() -> fmt::Result { // --snip-- Ok(()) } fn function2() -> io::Result<()> { // --snip-- Ok(()) } }
Ключевое слово as
Есть другое решение проблемы добавления двух типов с одинаковыми именами в одну и ту же область видимости используя use: после пути можно указать as и новое локальное имя (псевдоним) для типа
#![allow(unused)] fn main() { use std::fmt::Result; use std::io::Result as IoResult; fn function1() -> Result { // --snip-- Ok(()) } fn function2() -> IoResult<()> { // --snip-- Ok(()) } }
Реэкспорт имен pub use
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } pub use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); } }
делаем экспортируемый функционал видимым в других блоках
Использование внешних пакетов
- Добавить в зависимости имя и версию пакета в
Cargo.toml - Прописать
useимя пакета и функцию - Применить функцию в коде
Вложенные пути
#![allow(unused)] fn main() { use rand::Rng; // --snip-- use std::{cmp::Ordering, io}; // --snip-- }
или
#![allow(unused)] fn main() { use std::io::{self, Write}; }
Эта строка подключает std::io и std::io::Write в область видимости.
Оператор * (glob)
#![allow(unused)] fn main() { use std::collections::*; }
включает все элементы коллекции
Модули в разные файлы
- Перенос модуля
front_of_house
- Файл: src/lib.rs
#![allow(unused)] fn main() { mod front_of_house; pub use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); } }
- Файл: src/front_of_house.rs
#![allow(unused)] fn main() { pub mod hosting { pub fn add_to_waitlist() {} } }
- Перенос модуля
hosting
- Файл: src/front_of_house.rs
#![allow(unused)] fn main() { pub mod hosting; }
- Файл:
src/front_of_house/hosting.rs
#![allow(unused)] fn main() { pub fn add_to_waitlist() {} }
Общие коллекции
Эта тема требует отдельного изучения и как факт я намереваюсь сделать перевод reference и стандартной библиотеки rust
Это в общей коллекции представлено как доступные коллекции
- Sequences: Vec, VecDeque, LinkedList
- Maps: HashMap, BTreeMap
- Sets: HashSet, BTreeSet
- Misc: BinaryHeap
Вектор
Векторы позволяют хранить более одного значения в единой структуре данных, хранящей элементы в памяти один за другим. Векторы могут хранить данные только одного типа.
fn main() { let v: Vec<i32> = Vec::new(); } //или fn main() { let v = vec![1, 2, 3]; //это через макрос с инициализацией значений }
Векторы можно push
#![allow(unused)] fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
Чтение векторов
#![allow(unused)] fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
Перебор значений в вектора
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
Хранение в векторах своих типов Enum
#![allow(unused)] fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Хранение закодированного текста UTF-8 в строках
Строки String
В Rust есть только один строковый тип в ядре языка - срез строки
str, обычно используемый в заимствованном виде как&str.
String фактически реализован как обёртка вокруг вектора байтов с некоторыми дополнительными гарантиями, ограничениями и возможностями
#![allow(unused)] fn main() { let mut s = String::new(); }
to_string преобразует все к типажу Display
#![allow(unused)] fn main() { let data = "initial contents"; let s = data.to_string(); // The method also works on a literal directly: let s = "initial contents".to_string(); }
push_str добавляет строку
- переменная должна быть mut
- добавляет в конец строки строку
#![allow(unused)] fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
push добавляет в конец строки символ
#![allow(unused)] fn main() { let mut s = String::from("lo"); s.push('l'); }
+ и макрос format!
#![allow(unused)] fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
Работает по принципу макроса println!
#![allow(unused)] fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
Получение символов по индексу
существует три способа рассмотрения строк с точки зрения Rust: как байты, как скалярные значения и как кластеры графем
#![allow(unused)] fn main() { let hello = "Здравствуйте"; let s = &hello[0..4]; }
выведет 4 байта или 2 буквы
- Для перебора букв использовать метод
chars - Для перебора байт использовать метод
bytes
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } З д for b in "Зд".bytes() { println!("{b}"); } 208 151 208 180 }
HashMap
Тип
HashMap<K, V>хранит ключи типаKна значения типаV. Данная структура организует и хранит данные с помощью функции хеширования.
Создание новой хеш-карты
#![allow(unused)] fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); //создание новой карты scores.insert(String::from("Blue"), 10); //добавить элемент в карту scores.insert(String::from("Yellow"), 50); }
Доступ к hash по get
#![allow(unused)] fn main() { let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
перебор карт
#![allow(unused)] fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
Хэш карты забирают владение на себя. Нужно это учитывать.
Перезапись старых значений
#![allow(unused)] fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{scores:?}"); }
просто перезапишет новое значение. Новое значение будет вставлено, если нет такого ключа.
Добавить только новые значения и не перезаписывать старые
#![allow(unused)] fn main() { scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); }
метод entry позволяет добавить только не существующие значения вместе с or_insert
Считает количество повторений
#![allow(unused)] fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); //создали hash for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); // добавим новый если нет и присвоим 0 *count += 1; //разыменовали ссылку на ключ и увеличили на 1 } println!("{map:?}"); }
Хэширование
Hasher - это тип, реализующий трейт BuildHasher.
функция хеширования SipHash, может противостоять атакам класса: отказ в обслуживании, Denial of Service (DoS) с использованием хеш-таблиц siphash.
Обработка ошибок
В Rust ошибки группируются на две основные категории: исправимые (recoverable) и неисправимые (unrecoverable).
В Rust нет исключений. Вместо этого он имеет тип Result<T, E> для обрабатываемых (исправимых) ошибок и макрос panic!, который останавливает выполнение, когда программа встречает необрабатываемую (неисправимую) ошибку.
Когда происходит паника, программа начинает процесс раскрутки стека, означающий в Rust проход обратно по стеку вызовов и очистку данных для каждой обнаруженной функции.
Warning
Если в вашем проекте нужно насколько это возможно сделать маленьким исполняемый файл, вы можете переключиться с варианта раскрутки стека на вариант прерывания при панике, добавьте panic = 'abort' в раздел
[profile]вашего Cargo.toml файла.[profile.release] panic = 'abort'
При добавление в код макрос panic!
Программа прервется
Используем обратную трассировку
~/data/rs/panic [101] $ RUST_BACKTRACE=1 cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:5:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: __rustc::rust_begin_unwind
at /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/panicking.rs:697:5
1: core::panicking::panic_fmt
at /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/panicking.rs:280:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /home/edge/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /home/edge/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/slice/index.rs:18:15
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /home/edge/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3571:9
6: panic::main
at ./src/main.rs:5:6
7: core::ops::function::FnOnce::call_once
at /home/edge/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/ops/function.rs:253:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
~/data/rs/panic [101] $
Исправление ошибок с помощью Result
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Tпредставляет тип значения, которое будет возвращено в случае успеха внутри вариантаOk, аEпредставляет тип ошибки, которая будет возвращена при сбое внутри вариантаErr.
use std::{fs::File, io::ErrorKind}; fn main() { let greeting_file_result = File::open("hello.txt"); let _greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => match error.kind() { ErrorKind::NotFound => match File::create("hello.txt") { Ok(fc) => fc, Err(e) => panic!("Какая-то проблема: {e:?}"), }, _ => { panic!("Проблема открытия файла: {error:?}"); } }, }; }
Но есть еще вариант решить эту проблему через замыкания
use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {:?}", error); }) } else { panic!("Problem opening the file: {:?}", error); } }); }
Обработка ошибок с помощью unwrap и expect
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
unwrap выполняет туже работу что match:
- возвращает результат OK или
- вызывает panic! с описанием ошибки
expect позволяет указать сообщение для макроса panic!
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
Проброс ошибок
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } } }
Оператор ? для проброса ошибок
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
определим OurError. Если мы также определим
impl From<io::Error> for OurErrorдля создания экземпляра OurError из io::Error, то оператор ?, вызываемый в теле read_username_from_file, вызовет from и преобразует типы ошибок без необходимости добавления дополнительного кода в функцию.
Как итог:
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } }
Или записать весь файл в строку
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
?можно использовать и со значениямиOption<T>
#![allow(unused)] fn main() { fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } }
main тоже может возвращать Result
use std::error::Error; use std::fs::File; fn main() -> Result<(), Box<dyn Error>> { let greeting_file = File::open("hello.txt")?; Ok(()) }
panic! или не panic!
При панике код не имеет возможности восстановить своё выполнение.
В ситуациях как примеры, прототипы и тесты, более уместно писать код, который паникует вместо возвращения Result.
Когда код должен паниковать:
- Некорректное состояние — это что-то неожиданное, отличается от того, что может происходить время от времени, например, когда пользователь вводит данные в неправильном формате.
- Ваш код после этой точки должен полагаться на то, что он не находится в некорректном состоянии, вместо проверок наличия проблемы на каждом этапе.
- Нет хорошего способа закодировать данную информацию в типах, которые вы используете.
Создание своего типа
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {value}."); } Guess { value } } pub fn value(&self) -> i32 { self.value } } }
Обобщенные типы, типажи и время жизни
Каждый язык программирования имеет инструменты для эффективной работы с дублированием концепций. В Rust одним из таких инструментов являются обобщенные типы (generics): абстрактные заместители конкретных типов или других свойств. Мы можем выразить поведение обобщенных типов или их связь с другими обобщенными типами, не зная, что будет на их месте при компиляции и запуске кода.
Функции могут принимать параметры некоторого обобщенного типа, вместо конкретного типа, такого как i32 или String, аналогично тому, как они принимают параметры с неизвестными значениями для выполнения одного и того же кода с несколькими конкретными значениями. Фактически, мы уже использовали обобщенные типы в Главе 6 с Option<T>, в Главе 8 с Vec<T> и HashMap<K, V>, а в Главе 9 с Result<T, E>. В этой главе вы узнаете, как определять свои собственные типы, функции и методы с использованием обобщенных типов!
Сначала мы рассмотрим, как выделить функцию для уменьшения дублирования кода. Затем мы используем тот же метод, чтобы создать обобщенную функцию из двух функций, которые отличаются только типами своих параметров. Мы также объясним, как использовать обобщенные типы в определениях структур и перечислений.
Затем вы узнаете, как использовать типажи для определения поведения в обобщенном виде. Вы можете комбинировать типажи с обобщенными типами, чтобы ограничить обобщенный тип только теми типами, которые имеют определенное поведение, а не просто любым типом.
Наконец, мы обсудим время жизни (lifetimes): разновидность обобщенных типов, которая предоставляет компилятору информацию о том, как ссылки соотносятся друг с другом. Время жизни позволяет нам предоставить компилятору достаточно информации о заимствованных значениях, чтобы он мог гарантировать, что ссылки будут действительны в большем количестве ситуаций, чем без нашего вмешательства.
Устранение дублирования путем выделения функции
Обобщенные типы позволяют нам заменить конкретные типы заполнителем, который представляет множество типов, чтобы устранить дублирование кода. Прежде чем погрузиться в синтаксис обобщенных типов, давайте сначала посмотрим, как устранить дублирование способом, не связанным с обобщенными типами, путем выделения функции, которая заменяет конкретные значения заполнителем, представляющим множество значений. Затем мы применим тот же метод для выделения обобщенной функции! Научившись распознавать повторяющийся код, который можно выделить в функцию, вы начнете распознавать повторяющийся код, который можно использовать с обобщенными типами.
Мы начнем с короткой программы в Листинге 10-1, которая находит наибольшее число в списке.
<Листинг number="10-1" file-name="src/main.rs" caption="Поиск наибольшего числа в списке чисел">
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); assert_eq!(*largest, 100); }
</Листинг>
Мы сохраняем список целых чисел в переменной number_list и помещаем ссылку на первое число списка в переменную с именем largest. Затем мы перебираем все числа в списке, и если текущее число больше числа, хранящегося в largest, мы заменяем ссылку в этой переменной. Однако, если текущее число меньше или равно наибольшему числу, увиденному до сих пор, переменная не изменяется, и код переходит к следующему числу в списке. После рассмотрения всех чисел в списке largest должна ссылаться на наибольшее число, которое в данном случае равно 100.
Теперь нам поручили найти наибольшее число в двух разных списках чисел. Чтобы сделать это, мы можем продублировать код из Листинга 10-1 и использовать ту же логику в двух разных местах программы, как показано в Листинге 10-2.
<Листинг number="10-2" file-name="src/main.rs" caption="Код для поиска наибольшего числа в двух списках чисел">
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); }
</Листинг>
Хотя этот код работает, дублирование кода утомительно и чревато ошибками. Мы также должны помнить о необходимости обновлять код в нескольких местах, когда мы хотим его изменить.
Чтобы устранить это дублирование, мы создадим абстракцию, определив функцию, которая работает с любым списком целых чисел, переданным в качестве параметра. Это решение делает наш код более понятным и позволяет нам выразить концепцию поиска наибольшего числа в списке абстрактно.
В Листинге 10-3 мы выделяем код, который находит наибольшее число, в функцию с именем largest. Затем мы вызываем функцию, чтобы найти наибольшее число в двух списках из Листинга 10-2. Мы также могли бы использовать функцию на любом другом списке значений i32, который может у нас появиться в будущем.
<Листинг number="10-3" file-name="src/main.rs" caption="Абстрагированный код для поиска наибольшего числа в двух списках">
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 6000); }
</Листинг>
Функция largest имеет параметр с именем list, который представляет любой конкретный срез значений i32, который мы можем передать в функцию. В результате, когда мы вызываем функцию, код выполняется на конкретных значениях, которые мы передаем.
В итоге, вот шаги, которые мы предприняли, чтобы изменить код из Листинга 10-2 в Листинг 10-3:
- Определили дублирующийся код.
- Выделили дублирующийся код в тело функции и указали входные и возвращаемые значения этого кода в сигнатуре функции.
- Обновили два экземпляра дублированного кода, чтобы вместо них вызывалась функция.
Далее мы используем эти же шаги с обобщенными типами для сокращения дублирования кода. Точно так же, как тело функции может работать с абстрактным list вместо конкретных значений, обобщенные типы позволяют коду работать с абстрактными типами.
Например, предположим, что у нас есть две функции: одна, которая находит наибольший элемент в срезе значений i32, и другая, которая находит наибольший элемент в срезе значений char. Как мы можем устранить это дублирование? Давайте выясним!
Обобщенные типы данных (Generic)
Мы используем обобщенные типы для создания определений таких элементов, как сигнатуры функций или структуры, которые затем можем использовать со многими различными конкретными типами данных. Давайте сначала рассмотрим, как определять функции, структуры, перечисления и методы с использованием обобщенных типов. Затем мы обсудим, как обобщенные типы влияют на производительность кода.
В определениях функций
При определении функции, которая использует обобщенные типы, мы помещаем их в сигнатуру функции там, где обычно указываем типы данных параметров и возвращаемого значения. Это делает наш код более гибким и предоставляет больше функциональности вызывающим сторонам, предотвращая дублирование кода.
Продолжая с нашей функцией largest, в Листинге 10-4 показаны две функции, которые находят наибольшее значение в срезе. Затем мы объединим их в одну функцию, использующую обобщенные типы.
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {result}"); assert_eq!(*result, 'y'); }
Функция largest_i32 — это та, которую мы выделили в Листинге 10-3, она находит наибольший i32 в срезе. Функция largest_char находит наибольший char в срезе. Тела функций имеют одинаковый код, поэтому давайте устраним дублирование, введя параметр обобщенного типа в единой функции.
Чтобы параметризовать типы в новой единой функции, нам нужно назвать параметр типа, так же как мы делаем это для параметров значения функции. Вы можете использовать любой идентификатор в качестве имени параметра типа. Но мы будем использовать T, потому что по соглашению имена параметров типа в Rust короткие, часто состоящие из одной буквы, и соглашение об именовании типов в Rust — UpperCamelCase. Сокращение от type, T является выбором по умолчанию для большинства программистов на Rust.
Когда мы используем параметр в теле функции, мы должны объявить имя параметра в сигнатуре, чтобы компилятор знал, что означает это имя. Аналогично, когда мы используем имя параметра типа в сигнатуре функции, мы должны объявить имя параметра типа до его использования. Чтобы определить обобщенную функцию largest, мы помещаем объявления имен типов внутри угловых скобок, <>, между именем функции и списком параметров, вот так:
fn largest<T>(list: &[T]) -> &T {Мы читаем это определение как: «Функция largest является обобщенной относительно некоторого типа T». Эта функция имеет один параметр с именем list, который представляет собой срез значений типа T. Функция largest вернет ссылку на значение того же типа T.
В Листинге 10-5 показано объединенное определение функции largest, использующее обобщенный тип данных в своей сигнатуре. В листинге также показано, как мы можем вызвать функцию либо с срезом значений i32, либо char. Обратите внимание, что этот код пока не компилируется.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}Если мы скомпилируем этот код прямо сейчас, мы получим эту ошибку:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Текст справки упоминает std::cmp::PartialOrd, который является типажом, и мы поговорим о типажах в следующем разделе. Пока что знайте, что эта ошибка утверждает, что тело largest не будет работать для всех возможных типов, которыми может быть T. Поскольку мы хотим сравнивать значения типа T в теле, мы можем использовать только типы, значения которых можно упорядочить. Чтобы включить сравнения, стандартная библиотека имеет типаж std::cmp::PartialOrd, который вы можете реализовать для типов (см. Приложение C для получения дополнительной информации об этом типаже). Чтобы исправить Листинг 10-5, мы можем последовать предложению текста справки и ограничить типы, допустимые для T, только теми, которые реализуют PartialOrd. Тогда листинг скомпилируется, потому что стандартная библиотека реализует PartialOrd как для i32, так и для char.
В определениях структур
Мы также можем определять структуры, чтобы использовать параметр обобщенного типа в одном или нескольких полях, используя синтаксис <>. В Листинге 10-6 определяется структура Point<T> для хранения координатных значений x и y любого типа.
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Синтаксис использования обобщенных типов в определениях структур аналогичен синтаксису, используемому в определениях функций. Сначала мы объявляем имя параметра типа внутри угловых скобок сразу после имени структуры. Затем мы используем обобщенный тип в определении структуры там, где в противном случае указали бы конкретные типы данных.
Обратите внимание, что поскольку мы использовали только один обобщенный тип для определения Point<T>, это определение говорит, что структура Point<T> является обобщенной относительно некоторого типа T, и поля x и y оба имеют тот же тип, каким бы он ни был. Если мы создадим экземпляр Point<T>, который имеет значения разных типов, как в Листинге 10-7, наш код не скомпилируется.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}В этом примере, когда мы присваиваем целочисленное значение 5 для x, мы даем компилятору знать, что обобщенный тип T будет целым числом для этого экземпляра Point<T>. Затем, когда мы указываем 4.0 для y, который мы определили как имеющий тот же тип, что и x, мы получим ошибку несоответствия типов:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Чтобы определить структуру Point, в которой x и y являются обобщенными, но могут иметь разные типы, мы можем использовать несколько параметров обобщенного типа. Например, в Листинге 10-8 мы изменяем определение Point на обобщенное относительно типов T и U, где x имеет тип T, а y — тип U.
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Теперь все показанные экземпляры Point разрешены! Вы можете использовать столько параметров обобщенного типа в определении, сколько хотите, но использование более чем нескольких делает ваш код трудным для чтения. Если вы обнаруживаете, что вам нужно много обобщенных типов в вашем коде, это может указывать на то, что ваш код нужно реструктуризировать на более мелкие части.
В определениях перечислений
Как мы делали со структурами, мы можем определять перечисления, которые содержат обобщенные типы данных в своих вариантах. Давайте еще раз посмотрим на перечисление Option<T>, предоставляемое стандартной библиотекой, которое мы использовали в Главе 6:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Это определение теперь должно быть вам более понятным. Как вы можете видеть, перечисление Option<T> является обобщенным относительно типа T и имеет два варианта: Some, который содержит одно значение типа T, и вариант None, который не содержит никакого значения. Используя перечисление Option<T>, мы можем выразить абстрактную концепцию опционального значения, и поскольку Option<T> является обобщенным, мы можем использовать эту абстракцию независимо от типа опционального значения.
Перечисления также могут использовать несколько обобщенных типов. Определение перечисления Result, которое мы использовали в Главе 9, является одним из примеров:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Перечисление Result является обобщенным относительно двух типов, T и E, и имеет два варианта: Ok, который содержит значение типа T, и Err, который содержит значение типа E. Это определение позволяет удобно использовать перечисление Result везде, где у нас есть операция, которая может завершиться успешно (вернуть значение некоторого типа T) или неудачно (вернуть ошибку некоторого типа E). Фактически, это то, что мы использовали для открытия файла в Листинге 9-3, где T было заполнено типом std::fs::File при успешном открытии файла, а E было заполнено типом std::io::Error при возникновении проблем с открытием файла.
Когда вы распознаете ситуации в своем коде с несколькими определениями структур или перечислений, которые отличаются только типами значений, которые они содержат, вы можете избежать дублирования, используя обобщенные типы.
В определениях методов
Мы можем реализовывать методы для структур и перечислений (как мы делали в Главе 5) и также использовать обобщенные типы в их определениях. В Листинге 10-9 показана структура Point<T>, которую мы определили в Листинге 10-6, с реализованным для нее методом с именем x.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Здесь мы определили метод с именем x для Point<T>, который возвращает ссылку на данные в поле x.
Обратите внимание, что мы должны объявить T сразу после impl, чтобы мы могли использовать T для указания, что мы реализуем методы для типа Point<T>. Объявляя T как обобщенный тип после impl, Rust может определить, что тип в угловых скобках в Point является обобщенным типом, а не конкретным типом. Мы могли бы выбрать другое имя для этого обобщенного параметра, чем параметр, объявленный в определении структуры, но использование того же имени является общепринятым. Если вы напишете метод внутри impl, который объявляет обобщенный тип, этот метод будет определен для любого экземпляра типа, независимо от того, какой конкретный тип в конечном итоге подставится вместо обобщенного типа.
Мы также можем указывать ограничения на обобщенные типы при определении методов для типа. Мы могли бы, например, реализовать методы только для экземпляров Point<f32>, а не для экземпляров Point<T> с любым обобщенным типом. В Листинге 10-10 мы используем конкретный тип f32, что означает, что мы не объявляем никакие типы после impl.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Этот код означает, что тип Point<f32> будет иметь метод distance_from_origin; другие экземпляры Point<T>, где T не является типом f32, не будут иметь этот метод. Метод измеряет, как далеко наша точка находится от точки с координатами (0.0, 0.0) и использует математические операции, доступные только для типов с плавающей точкой.
Параметры обобщенного типа в определении структуры не всегда совпадают с теми, которые вы используете в сигнатурах методов той же структуры. В Листинге 10-11 используются обобщенные типы X1 и Y1 для структуры Point и X2 и Y2 для сигнатуры метода mixup, чтобы сделать пример более понятным. Метод создает новый экземпляр Point со значением x из self Point (типа X1) и значением y из переданного Point (типа Y2).
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
В main мы определили Point, у которой x имеет тип i32 (со значением 5), а y — тип f64 (со значением 10.4). Переменная p2 — это структура Point, у которой x является строковым срезом (со значением "Hello"), а y — char (со значением c). Вызов mixup для p1 с аргументом p2 дает нам p3, у которой x будет типа i32, потому что x пришел из p1. Переменная p3 будет иметь y типа char, потому что y пришел из p2. Макрос println! выведет p3.x = 5, p3.y = c.
Цель этого примера — продемонстрировать ситуацию, в которой некоторые обобщенные параметры объявляются с impl, а некоторые — с определением метода. Здесь обобщенные параметры X1 и Y1 объявлены после impl, потому что они связаны с определением структуры. Обобщенные параметры X2 и Y2 объявлены после fn mixup, потому что они относятся только к методу.
Производительность кода с использованием обобщенных типов
Вам может быть интересно, есть ли штраф за производительность во время выполнения при использовании параметров обобщенного типа. Хорошая новость заключается в том, что использование обобщенных типов не сделает вашу программу более медленной, чем если бы вы использовали конкретные типы.
Rust достигает этого путем выполнения мономорфизации кода, использующего обобщенные типы, во время компиляции. Мономорфизация — это процесс превращения обобщенного кода в конкретный код путем подстановки конкретных типов, которые используются при компиляции. В этом процессе компилятор выполняет действия, обратные тем, которые мы использовали для создания обобщенной функции в Листинге 10-5: компилятор смотрит на все места, где вызывается обобщенный код, и генерирует код для конкретных типов, с которыми вызывается обобщенный код.
Давайте посмотрим, как это работает, на примере обобщенного перечисления Option<T> из стандартной библиотеки:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
Когда Rust компилирует этот код, он выполняет мономорфизацию. В процессе этого компилятор читает значения, которые были использованы в экземплярах Option<T>, и идентифицирует два вида Option<T>: один для i32 и другой для f64. Таким образом, он расширяет обобщенное определение Option<T> в два определения, специализированные для i32 и f64, заменяя тем самым обобщенное определение конкретными.
Мономорфизированная версия кода выглядит примерно так (компилятор использует другие имена, чем те, которые мы используем здесь для иллюстрации):
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
Обобщенный Option<T> заменяется конкретными определениями, созданными компилятором. Поскольку Rust компилирует обобщенный код в код, который указывает тип в каждом экземпляре, мы не платим штраф за производительность во время выполнения за использование обобщенных типов. Когда код выполняется, он работает так же, как если бы мы вручную продублировали каждое определение. Процесс мономорфизации делает обобщенные типы Rust чрезвычайно эффективными во время выполнения.
Определение общего поведения с помощью типажей (Traits)
Типаж (trait) определяет функциональность, которой обладает определенный тип и может делиться ею с другими типами. Мы можем использовать типажи для определения общего поведения абстрактным способом. Мы можем использовать ограничения типажей (trait bounds), чтобы указать, что обобщенный тип может быть любым типом, обладающим определенным поведением.
Примечание: Типажи похожи на функцию, часто называемую интерфейсами в других языках, хотя и с некоторыми различиями.
Определение типажа
Поведение типа состоит из методов, которые мы можем вызывать для этого типа. Разные типы разделяют одинаковое поведение, если мы можем вызывать одни и те же методы для всех этих типов. Определения типажей — это способ сгруппировать сигнатуры методов вместе, чтобы определить набор поведений, необходимых для достижения некоторой цели.
Например, допустим, у нас есть несколько структур, которые содержат различные виды и объемы текста: структура NewsArticle, которая содержит новостную статью, поданную в определенном месте, и SocialPost, которая может содержать не более 280 символов вместе с метаданными, указывающими, была ли это новая запись, репост или ответ на другую запись.
Мы хотим создать библиотечный крейт агрегатора медиа с именем aggregator, который может отображать сводки данных, которые могут храниться в экземпляре NewsArticle или SocialPost. Для этого нам нужна сводка от каждого типа, и мы будем запрашивать эту сводку, вызывая метод summarize на экземпляре. В Листинге 10-12 показано определение публичного типажа Summary, который выражает это поведение.
pub trait Summary {
fn summarize(&self) -> String;
}Здесь мы объявляем типаж, используя ключевое слово trait, а затем имя типажа, в данном случае Summary. Мы также объявляем типаж как pub, чтобы крейты, зависящие от этого крейта, тоже могли использовать этот типаж, как мы увидим через несколько примеров. Внутри фигурных скобок мы объявляем сигнатуры методов, которые описывают поведения типов, реализующих этот типаж, в данном случае это fn summarize(&self) -> String.
После сигнатуры метода, вместо предоставления реализации в фигурных скобках, мы используем точку с запятой. Каждый тип, реализующий этот типаж, должен предоставить свое собственное поведение для тела метода. Компилятор обеспечит, чтобы любой тип, имеющий типаж Summary, имел метод summarize, определенный точно с этой сигнатурой.
Типаж может иметь несколько методов в своем теле: сигнатуры методов перечислены по одной на строку, и каждая строка заканчивается точкой с запятой.
Реализация типажа для типа
Теперь, когда мы определили желаемые сигнатуры методов типажа Summary, мы можем реализовать его для типов в нашем агрегаторе медиа. В Листинге 10-13 показана реализация типажа Summary для структуры NewsArticle, которая использует заголовок, автора и местоположение для создания возвращаемого значения summarize. Для структуры SocialPost мы определяем summarize как имя пользователя, за которым следует весь текст записи, предполагая, что содержимое записи уже ограничено 280 символами.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Реализация типажа для типа похожа на реализацию обычных методов. Разница в том, что после impl мы указываем имя типажа, который хотим реализовать, затем используем ключевое слово for, а затем указываем имя типа, для которого хотим реализовать типаж. Внутри блока impl мы помещаем сигнатуры методов, которые определены в определении типажа. Вместо добавления точки с запятой после каждой сигнатуры мы используем фигурные скобки и заполняем тело метода конкретным поведением, которое мы хотим, чтобы методы типажа имели для конкретного типа.
Теперь, когда библиотека реализовала типаж Summary для NewsArticle и SocialPost, пользователи крейта могут вызывать методы типажа на экземплярах NewsArticle и SocialPost так же, как мы вызываем обычные методы. Единственная разница в том, что пользователь должен ввести типаж в область видимости так же, как и типы. Вот пример того, как бинарный крейт может использовать наш библиотечный крейт aggregator:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Этот код выводит 1 new post: horse_ebooks: of course, as you probably already know, people.
Другие крейты, зависящие от крейта aggregator, также могут ввести типаж Summary в область видимости, чтобы реализовать Summary для своих собственных типов. Следует отметить одно ограничение: мы можем реализовать типаж для типа только в том случае, если либо типаж, либо тип, либо оба являются локальными для нашего крейта. Например, мы можем реализовать типажи стандартной библиотеки, такие как Display, для пользовательского типа, такого как SocialPost, как часть функциональности нашего крейта aggregator, потому что тип SocialPost является локальным для нашего крейта aggregator. Мы также можем реализовать Summary для Vec<T> в нашем крейте aggregator, потому что типаж Summary является локальным для нашего крейта aggregator.
Но мы не можем реализовать внешние типажи на внешних типах. Например, мы не можем реализовать типаж Display для Vec<T> внутри нашего крейта aggregator, потому что Display и Vec<T> определены в стандартной библиотеке и не являются локальными для нашего крейта aggregator. Это ограничение является частью свойства, называемого когерентностью (coherence), и, более конкретно, правилом сироты (orphan rule), названным так потому, что родительский тип отсутствует. Это правило гарантирует, что код других людей не может сломать ваш код, и наоборот. Без этого правила два крейта могли бы реализовать один и тот же типаж для одного и того же типа, и Rust не знал бы, какую реализацию использовать.
Использование реализаций по умолчанию
Иногда полезно иметь поведение по умолчанию для некоторых или всех методов в типаже вместо того, чтобы требовать реализации всех методов для каждого типа. Затем, когда мы реализуем типаж для конкретного типа, мы можем сохранить или переопределить поведение по умолчанию каждого метода.
В Листинге 10-14 мы указываем строку по умолчанию для метода summarize типажа Summary вместо того, чтобы только определять сигнатуру метода, как мы делали в Листинге 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Чтобы использовать реализацию по умолчанию для суммирования экземпляров NewsArticle, мы указываем пустой блок impl с impl Summary for NewsArticle {}.
Хотя мы больше не определяем метод summarize на NewsArticle напрямую, мы предоставили реализацию по умолчанию и указали, что NewsArticle реализует типаж Summary. В результате мы все еще можем вызывать метод summarize на экземпляре NewsArticle, вот так:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Этот код выводит New article available! (Read more...).
Создание реализации по умолчанию не требует от нас изменения чего-либо в реализации Summary для SocialPost в Листинге 10-13. Причина в том, что синтаксис переопределения реализации по умолчанию такой же, как синтаксис реализации метода типажа, который не имеет реализации по умолчанию.
Реализации по умолчанию могут вызывать другие методы в том же типаже, даже если эти другие методы не имеют реализации по умолчанию. Таким образом, типаж может предоставить много полезной функциональности и требовать от реализаторов указания только небольшой ее части. Например, мы могли бы определить типаж Summary так, чтобы он имел метод summarize_author, реализация которого требуется, а затем определить метод summarize, который имеет реализацию по умолчанию, вызывающую метод summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Чтобы использовать эту версию Summary, нам нужно только определить summarize_author при реализации типажа для типа:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}После того как мы определим summarize_author, мы можем вызвать summarize на экземплярах структуры SocialPost, и реализация по умолчанию summarize вызовет предоставленное нами определение summarize_author. Поскольку мы реализовали summarize_author, типаж Summary предоставил нам поведение метода summarize без необходимости писать какой-либо дополнительный код. Вот как это выглядит:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Этот код выводит 1 new post: (Read more from @horse_ebooks...).
Обратите внимание, что невозможно вызвать реализацию по умолчанию из переопределяющей реализации того же метода.
Использование типажей в качестве параметров
Теперь, когда вы знаете, как определять и реализовывать типажи, мы можем изучить, как использовать типажи для определения функций, которые принимают много разных типов. Мы будем использовать типаж Summary, который мы реализовали для типов NewsArticle и SocialPost в Листинге 10-13, чтобы определить функцию notify, которая вызывает метод summarize для своего параметра item, который имеет некоторый тип, реализующий типаж Summary. Для этого мы используем синтаксис impl Trait, вот так:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}Вместо конкретного типа для параметра item мы указываем ключевое слово impl и имя типажа. Этот параметр принимает любой тип, который реализует указанный типаж. В теле notify мы можем вызывать любые методы для item, которые происходят из типажа Summary, такие как summarize. Мы можем вызывать notify и передавать любой экземпляр NewsArticle или SocialPost. Код, который вызывает функцию с любым другим типом, таким как String или i32, не скомпилируется, потому что эти типы не реализуют Summary.
Синтаксис ограничений типажей
Синтаксис impl Trait работает для простых случаев, но на самом деле является синтаксическим сахаром для более длинной формы, известной как ограничение типажа (trait bound); это выглядит так:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Эта более длинная форма эквивалентна примеру в предыдущем разделе, но более многословна. Мы помещаем ограничения типажей с объявлением параметра обобщенного типа после двоеточия и внутри угловых скобок.
Синтаксис impl Trait удобен и делает код более лаконичным в простых случаях, в то время как полный синтаксис ограничений типажей может выражать более сложные случаи. Например, у нас может быть два параметра, которые реализуют Summary. Делать это с синтаксисом impl Trait выглядит так:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Использование impl Trait уместно, если мы хотим, чтобы эта функция позволяла item1 и item2 иметь разные типы (при условии, что оба типа реализуют Summary). Однако, если мы хотим принудительно сделать оба параметра одного типа, мы должны использовать ограничение типажа, вот так:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Указанный обобщенный тип T в качестве типа параметров item1 и item2 ограничивает функцию так, что конкретный тип значения, переданного в качестве аргумента для item1 и item2, должен быть одинаковым.
Множественные ограничения типажей с синтаксисом +
Мы также можем указать более одного ограничения типажа. Допустим, мы хотим, чтобы notify использовал форматирование отображения, а также summarize для item: мы указываем в определении notify, что item должен реализовывать и Display, и Summary. Мы можем сделать это, используя синтаксис +:
pub fn notify(item: &(impl Summary + Display)) {Синтаксис + также действителен для ограничений типажей на обобщенных типах:
pub fn notify<T: Summary + Display>(item: &T) {С указанными двумя ограничениями типажей, тело notify может вызывать summarize и использовать {} для форматирования item.
Более понятные ограничения типажей с помощью предложений where
Использование слишком большого количества ограничений типажей имеет свои недостатки. Каждый обобщенный тип имеет свои собственные ограничения типажей, поэтому функции с несколькими параметрами обобщенных типов могут содержать много информации об ограничениях типажей между именем функции и списком ее параметров, что затрудняет чтение сигнатуры функции. По этой причине Rust имеет альтернативный синтаксис для указания ограничений типажей внутри предложения where после сигнатуры функции. Так, вместо того чтобы писать это:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {мы можем использовать предложение where, вот так:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Сигнатура этой функции менее загромождена: имя функции, список параметров и возвращаемый тип находятся близко друг к другу, аналогично функции без большого количества ограничений типажей.
Возврат типов, реализующих типажи
Мы также можем использовать синтаксис impl Trait в позиции возврата, чтобы вернуть значение некоторого типа, который реализует типаж, как показано здесь:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}Используя impl Summary для возвращаемого типа, мы указываем, что функция returns_summarizable возвращает некоторый тип, который реализует типаж Summary, не называя конкретный тип. В данном случае returns_summarizable возвращает SocialPost, но коду, вызывающему эту функцию, не нужно это знать.
Возможность указать возвращаемый тип только по реализуемому им типажу особенно полезна в контексте замыканий и итераторов, которые мы рассмотрим в Главе 13. Замыкания и итераторы создают типы, которые известны только компилятору, или типы, которые очень длинно указывать. Синтаксис impl Trait позволяет вам кратко указать, что функция возвращает некоторый тип, реализующий типаж Iterator, без необходимости выписывать очень длинный тип.
Однако вы можете использовать impl Trait только если возвращаете один тип. Например, этот код, который возвращает либо NewsArticle, либо SocialPost, с указанием возвращаемого типа как impl Summary, не сработает:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}Возврат либо NewsArticle, либо SocialPost не разрешен из-за ограничений в том, как синтаксис impl Trait реализован в компиляторе. Мы рассмотрим, как написать функцию с таким поведением, в разделе «Использование типаж-объектов для абстрагирования над общим поведением» Главы 18.
Использование ограничений типажей для условной реализации методов
Используя ограничение типажа с блоком impl, который использует параметры обобщенного типа, мы можем условно реализовывать методы для типов, которые реализуют указанные типажи. Например, тип Pair<T> в Листинге 10-15 всегда реализует функцию new, чтобы возвращать новый экземпляр Pair<T> (напомним из раздела «Синтаксис методов» Главы 5, что Self является псевдонимом типа для типа блока impl, который в данном случае является Pair<T>). Но в следующем блоке impl, Pair<T> реализует метод cmp_display только если его внутренний тип T реализует типаж PartialOrd, который позволяет сравнивать, и типаж Display, который позволяет печатать.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Мы также можем условно реализовать типаж для любого типа, который реализует другой типаж. Реализации типажа для любого типа, который удовлетворяет ограничениям типажа, называются общими реализациями (blanket implementations) и широко используются в стандартной библиотеке Rust. Например, стандартная библиотека реализует типаж ToString для любого типа, который реализует типаж Display. Блок impl в стандартной библиотеке выглядит примерно так:
impl<T: Display> ToString for T {
// --snip--
}Поскольку стандартная библиотека имеет эту общую реализацию, мы можем вызывать метод to_string, определенный типажом ToString, для любого типа, который реализует типаж Display. Например, мы можем преобразовать целые числа в соответствующие им значения String вот так, потому что целые числа реализуют Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Общие реализации появляются в документации для типажа в разделе «Implementors».
Типажи и ограничения типажей позволяют нам писать код, который использует параметры обобщенного типа для уменьшения дублирования, но также указывает компилятору, что мы хотим, чтобы обобщенный тип имел определенное поведение. Затем компилятор может использовать информацию об ограничениях типажей для проверки того, что все конкретные типы, используемые с нашим кодом, предоставляют правильное поведение. В языках с динамической типизацией мы получили бы ошибку во время выполнения, если бы вызвали метод для типа, который не определяет этот метод. Но Rust перемещает эти ошибки на время компиляции, так что мы вынуждены исправлять проблемы еще до того, как наш код сможет запуститься. Кроме того, нам не нужно писать код, который проверяет поведение во время выполнения, потому что мы уже проверили во время компиляции. Это повышает производительность без необходимости жертвовать гибкостью обобщенных типов.
Проверка ссылок с помощью времен жизни (Lifitimes)
Время жизни (lifetimes) — это еще один вид обобщенных параметров, которые мы уже использовали. В отличие от обеспечения того, что тип имеет желаемое поведение, время жизни гарантирует, что ссылки остаются действительными так долго, как нам это нужно.
Одна деталь, которую мы не обсуждали в разделе «Ссылки и заимствование» Главы 4, заключается в том, что каждая ссылка в Rust имеет время жизни — это область видимости, в которой эта ссылка действительна. Большую часть времени время жизни неявно и выводится, так же как и типы выводятся большую часть времени. Мы должны аннотировать типы только когда возможны несколько типов. Подобным образом, мы должны аннотировать время жизни, когда время жизни ссылок может быть связано несколькими разными способами. Rust требует, чтобы мы аннотировали отношения, используя обобщенные параметры времени жизни, чтобы гарантировать, что фактические ссылки, используемые во время выполнения, определенно будут действительными.
Аннотирование времени жизни — это даже не концепция, которая есть в большинстве других языков программирования, поэтому она покажется непривычной. Хотя мы не охватим время жизни полностью в этой главе, мы обсудим распространенные способы, с которыми вы можете столкнуться в синтаксисе времени жизни, чтобы вы могли освоиться с этой концепцией.
Висячие ссылки
Основная цель времени жизни — предотвратить висячие ссылки (dangling references), которые, если бы им разрешили существовать, заставили бы программу ссылаться на данные, отличные от тех, на которые она предназначена. Рассмотрим программу в Листинге 10-16, которая имеет внешнюю область видимости и внутреннюю область видимости.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Примечание: Примеры в Листингах 10-16, 10-17 и 10-23 объявляют переменные без присвоения им начального значения, поэтому имя переменной существует во внешней области видимости. На первый взгляд, это может показаться противоречащим тому, что в Rust нет нулевых значений. Однако, если мы попытаемся использовать переменную до присвоения ей значения, мы получим ошибку компиляции, что показывает, что Rust действительно не позволяет нулевые значения.
Внешняя область видимости объявляет переменную с именем r без начального значения, а внутренняя область видимости объявляет переменную с именем x с начальным значением 5. Внутри внутренней области видимости мы пытаемся установить значение r как ссылку на x. Затем внутренняя область видимости заканчивается, и мы пытаемся напечатать значение в r. Этот код не скомпилируется, потому что значение, на которое ссылается r, вышло из области видимости до того, как мы попытались его использовать. Вот сообщение об ошибке:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Сообщение об ошибке говорит, что переменная x «не живет достаточно долго». Причина в том, что x выйдет из области видимости, когда внутренняя область видимости закончится на строке 7. Но r все еще действительна для внешней области видимости; потому что ее область видимости больше, мы говорим, что она «живет дольше». Если бы Rust позволил этому коду работать, r ссылалась бы на память, которая была освобождена, когда x вышел из области видимости, и все, что мы попытались бы сделать с r, не работало бы правильно. Итак, как Rust определяет, что этот код недействителен? Он использует проверку заимствований.
Проверка заимствований
Компилятор Rust имеет проверку заимствований (borrow checker), которая сравнивает области видимости, чтобы определить, все ли заимствования действительны. В Листинге 10-17 показан тот же код, что и в Листинге 10-16, но с аннотациями, показывающими время жизни переменных.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+Здесь мы аннотировали время жизни r как 'a и время жизни x как 'b. Как вы можете видеть, внутренний блок 'b намного меньше, чем внешний блок времени жизни 'a. Во время компиляции Rust сравнивает размер двух времен жизни и видит, что r имеет время жизни 'a, но ссылается на память с временем жизни 'b. Программа отвергается, потому что 'b короче, чем 'a: объект ссылки не живет так же долго, как ссылка.
В Листинге 10-18 исправлен код так, что в нем нет висячей ссылки, и он компилируется без ошибок.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {r}"); // | | // --+ | } // ----------+
Здесь x имеет время жизни 'b, которое в данном случае больше, чем 'a. Это означает, что r может ссылаться на x, потому что Rust знает, что ссылка в r всегда будет действительна, пока действителен x.
Теперь, когда вы знаете, где находится время жизни ссылок и как Rust анализирует время жизни, чтобы гарантировать, что ссылки всегда будут действительны, давайте рассмотрим обобщенное время жизни в параметрах функций и возвращаемых значениях.
Обобщенное время жизни в функциях
Мы напишем функцию, которая возвращает более длинный из двух строковых срезов. Эта функция будет принимать два строковых среза и возвращать один строковый срез. После того как мы реализуем функцию longest, код в Листинге 10-19 должен вывести The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}Обратите внимание, что мы хотим, чтобы функция принимала строковые срезы, которые являются ссылками, а не строки, потому что мы не хотим, чтобы функция longest забирала владение своими параметрами. Обратитесь к разделу «Строковые срезы как параметры» в Главе 4 для более подробного обсуждения, почему параметры, которые мы используем в Листинге 10-19, — это те, которые мы хотим.
Если мы попытаемся реализовать функцию longest, как показано в Листинге 10-20, она не скомпилируется.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}Вместо этого мы получаем следующую ошибку, которая говорит о времени жизни:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Текст справки показывает, что возвращаемый тип нуждается в обобщенном параметре времени жизни, потому что Rust не может определить, ссылается ли возвращаемая ссылка на x или y. На самом деле, мы тоже не знаем, потому что блок if в теле этой функции возвращает ссылку на x, а блок else возвращает ссылку на y!
Когда мы определяем эту функцию, мы не знаем конкретные значения, которые будут переданы в эту функцию, поэтому мы не знаем, выполнится ли случай if или случай else. Мы также не знаем конкретное время жизни ссылок, которые будут переданы, поэтому мы не можем посмотреть на области видимости, как мы делали в Листингах 10-17 и 10-18, чтобы определить, будет ли возвращаемая нами ссылка всегда действительна. Проверка заимствований тоже не может этого определить, потому что она не знает, как время жизни x и y связано со временем жизни возвращаемого значения. Чтобы исправить эту ошибку, мы добавим обобщенные параметры времени жизни, которые определяют отношение между ссылками, чтобы проверка заимствований могла выполнить свой анализ.
Синтаксис аннотации времени жизни
Аннотации времени жизни не меняют то, как долго живут какие-либо ссылки. Скорее, они описывают отношения времени жизни нескольких ссылок друг с другом, не влияя на время жизни. Так же, как функции могут принимать любой тип, когда сигнатура указывает параметр обобщенного типа, функции могут принимать ссылки с любым временем жизни, указывая параметр обобщенного времени жизни.
Аннотации времени жизни имеют немного необычный синтаксис: имена параметров времени жизни должны начинаться с апострофа (') и обычно все в нижнем регистре и очень короткие, как обобщенные типы. Большинство людей используют имя 'a для первой аннотации времени жизни. Мы помещаем аннотации параметров времени жизни после & ссылки, используя пробел для отделения аннотации от типа ссылки.
Вот несколько примеров: ссылка на i32 без параметра времени жизни, ссылка на i32 с параметром времени жизни с именем 'a и изменяемая ссылка на i32, которая также имеет время жизни 'a:
&i32 // ссылка
&'a i32 // ссылка с явным временем жизни
&'a mut i32 // изменяемая ссылка с явным временем жизниОдна аннотация времени жизни сама по себе не имеет особого смысла, потому что аннотации предназначены для того, чтобы сообщать Rust, как параметры обобщенного времени жизни нескольких ссылок связаны друг с другом. Давайте рассмотрим, как аннотации времени жизни связаны друг с другом в контексте функции longest.
В сигнатурах функций
Чтобы использовать аннотации времени жизни в сигнатурах функций, нам нужно объявить обобщенные параметры времени жизни внутри угловых скобок между именем функции и списком параметров, точно так же, как мы делали с параметрами обобщенного типа.
Мы хотим, чтобы сигнатура выражала следующее ограничение: возвращаемая ссылка будет действительна до тех пор, пока действительны оба параметра. Это отношение между временем жизни параметров и возвращаемого значения. Мы назовем время жизни 'a и затем добавим его к каждой ссылке, как показано в Листинге 10-21.
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Этот код должен скомпилироваться и дать желаемый результат, когда мы используем его с функцией main из Листинга 10-19.
Сигнатура функции теперь сообщает Rust, что для некоторого времени жизни 'a функция принимает два параметра, оба из которых являются строковыми срезами, которые живут по крайней мере так же долго, как время жизни 'a. Сигнатура функции также сообщает Rust, что строковый срез, возвращаемый из функции, будет жить по крайней мере так же долго, как время жизни 'a. На практике это означает, что время жизни ссылки, возвращаемой функцией longest, такое же, как меньшее из времен жизни значений, на которые ссылаются аргументы функции. Эти отношения — это то, что мы хотим, чтобы Rust использовал при анализе этого кода.
Помните, когда мы указываем параметры времени жизни в этой сигнатуре функции, мы не меняем время жизни любых переданных или возвращенных значений. Скорее, мы указываем, что проверка заимствований должна отвергать любые значения, которые не соответствуют этим ограничениям. Обратите внимание, что функции longest не нужно знать точно, как долго будут жить x и y, только то, что некоторая область видимости может быть заменена на 'a, которая удовлетворит эту сигнатуру.
При аннотировании времени жизни в функциях аннотации идут в сигнатуре функции, а не в теле функции. Аннотации времени жизни становятся частью контракта функции, так же как типы в сигнатуре. Наличие в сигнатурах функций контракта времени жизни означает, что анализ, который выполняет компилятор Rust, может быть проще. Если есть проблема с тем, как аннотирована функция или как она вызывается, ошибки компилятора могут указывать на часть нашего кода и ограничения более точно. Если бы вместо этого компилятор Rust делал больше выводов о том, какие отношения времени жизни мы предполагали, компилятор мог бы указать только на использование нашего кода за много шагов от причины проблемы.
Когда мы передаем конкретные ссылки в longest, конкретное время жизни, которое заменяет 'a, — это часть области видимости x, которая перекрывается с областью видимости y. Другими словами, обобщенное время жизни 'a получит конкретное время жизни, которое равно меньшему из времен жизни x и y. Поскольку мы аннотировали возвращаемую ссылку тем же параметром времени жизни 'a, возвращаемая ссылка также будет действительна на протяжении меньшего из времен жизни x и y.
Давайте посмотрим, как аннотации времени жизни ограничивают функцию longest, передавая ссылки, которые имеют разные конкретные времена жизни. Листинг 10-22 — это простой пример.
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {result}"); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
В этом примере string1 действительна до конца внешней области видимости, string2 действительна до конца внутренней области видимости, и result ссылается на что-то, что действительно до конца внутренней области видимости. Запустите этот код, и вы увидите, что проверка заимствований одобряет его; он скомпилируется и напечатает The longest string is long string is long.
Далее давайте попробуем пример, который показывает, что время жизни ссылки в result должно быть меньшим временем жизни двух аргументов. Мы переместим объявление переменной result за пределы внутренней области видимости, но оставим присваивание значения переменной result внутри области видимости с string2. Затем мы переместим println!, который использует result, за пределы внутренней области видимости, после того как внутренняя область видимости закончилась. Код в Листинге 10-23 не скомпилируется.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Когда мы пытаемся скомпилировать этот код, мы получаем эту ошибку:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Ошибка показывает, что для того, чтобы result был действителен для оператора println!, string2 должна быть действительна до конца внешней области видимости. Rust знает это, потому что мы аннотировали время жизни параметров функции и возвращаемых значений, используя тот же параметр времени жизни 'a.
Как люди, мы можем посмотреть на этот код и увидеть, что string1 длиннее, чем string2, и, следовательно, result будет содержать ссылку на string1. Поскольку string1 еще не вышла из области видимости, ссылка на string1 все еще будет действительна для оператора println!. Однако компилятор не может видеть, что ссылка действительна в этом случае. Мы сказали Rust, что время жизни ссылки, возвращаемой функцией longest, такое же, как меньшее из времен жизни переданных ссылок. Следовательно, проверка заимствований запрещает код в Листинге 10-23 как возможно имеющий недействительную ссылку.
Попробуйте провести больше экспериментов, изменяя значения и время жизни ссылок, передаваемых в функцию longest, и то, как используется возвращаемая ссылка. Выдвигайте гипотезы о том, пройдут ли ваши эксперименты проверку заимствований до компиляции; затем проверьте, правы ли вы!
Отношения
То, как вам нужно указывать параметры времени жизни, зависит от того, что делает ваша функция. Например, если бы мы изменили реализацию функции longest так, чтобы она всегда возвращала первый параметр, а не самый длинный строковый срез, нам не нужно было бы указывать время жизни для параметра y. Следующий код скомпилируется:
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
Мы указали параметр времени жизни 'a для параметра x и возвращаемого типа, но не для параметра y, потому что время жизни y не имеет никакого отношения ко времени жизни x или возвращаемому значению.
При возврате ссылки из функции параметр времени жизни для возвращаемого типа должен соответствовать параметру времени жизни одного из параметров. Если возвращаемая ссылка не ссылается на один из параметров, она должна ссылаться на значение, созданное внутри этой функции. Однако это была бы висячая ссылка, потому что значение выйдет из области видимости в конце функции. Рассмотрите эту попытку реализации функции longest, которая не скомпилируется:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Здесь, хотя мы указали параметр времени жизни 'a для возвращаемого типа, эта реализация не скомпилируется, потому что время жизни возвращаемого значения вообще не связано со временем жизни параметров. Вот сообщение об ошибке, которое мы получаем:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Проблема в том, что result выходит из области видимости и очищается в конце функции longest. Мы также пытаемся вернуть ссылку на result из функции. Нет способа указать параметры времени жизни, которые изменили бы висячую ссылку, и Rust не позволит нам создать висячую ссылку. В этом случае лучшим исправлением будет возврат владеемого типа данных, а не ссылки, чтобы вызывающая функция затем была ответственна за очистку значения.
В конечном счете, синтаксис времени жизни — это о соединении времени жизни различных параметров и возвращаемых значений функций. Как только они соединены, Rust имеет достаточно информации, чтобы разрешать безопасные операции с памятью и запрещать операции, которые создавали бы висячие указатели или иным образом нарушали бы безопасность памяти.
В определениях структур
До сих пор все структуры, которые мы определяли, содержали владеемые типы. Мы можем определять структуры для хранения ссылок, но в этом случае нам нужно добавить аннотацию времени жизни на каждую ссылку в определении структуры. В Листинге 10-24 есть структура с именем ImportantExcerpt, которая содержит строковый срез.
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Эта структура имеет единственное поле part, которое содержит строковый срез, который является ссылкой. Как и с обобщенными типами данных, мы объявляем имя параметра обобщенного времени жизни внутри угловых скобок после имени структуры, чтобы мы могли использовать параметр времени жизни в теле определения структуры. Эта аннотация означает, что экземпляр ImportantExcerpt не может пережить ссылку, которую он содержит в своем поле part.
Функция main здесь создает экземпляр структуры ImportantExcerpt, который содержит ссылку на первое предложение String, принадлежащее переменной novel. Данные в novel существуют до создания экземпляра ImportantExcerpt. Кроме того, novel не выходит из области видимости до того, как ImportantExcerpt выйдет из области видимости, поэтому ссылка в экземпляре ImportantExcerpt действительна.
Сокрытие времени жизни
Вы узнали, что каждая ссылка имеет время жизни и что вам нужно указывать параметры времени жизни для функций или структур, которые используют ссылки. Однако у нас была функция в Листинге 4-9, показанная снова в Листинге 10-25, которая компилировалась без аннотаций времени жизни.
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Причина, по которой эта функция компилируется без аннотаций времени жизни, историческая: в ранних версиях (до 1.0) Rust этот код не компилировался, потому что каждой ссылке нужна была явное время жизни. В то время сигнатура функции была бы написана так:
fn first_word<'a>(s: &'a str) -> &'a str {После написания большого количества кода на Rust команда Rust обнаружила, что программисты на Rust вводят одни и те же аннотации времени жизни снова и снова в определенных ситуациях. Эти ситуации были предсказуемы и следовали нескольким детерминированным шаблонам. Разработчики запрограммировали эти шаблоны в код компилятора, чтобы проверка заимствований могла выводить время жизни в этих ситуациях и не нуждалась в явных аннотациях.
Этот кусок истории Rust актуален, потому что возможно, что появятся более детерминированные шаблоны и будут добавлены в компилятор. В будущем может потребоваться еще меньше аннотаций времени жизни.
Шаблоны, запрограммированные в анализ ссылок Rust, называются правилами сокрытия времени жизни (lifetime elision rules). Это не правила, которым должны следовать программисты; это набор конкретных случаев, которые компилятор будет рассматривать, и если ваш код подходит под эти случаи, вам не нужно писать время жизни явно.
Правила сокрытия не обеспечивают полный вывод. Если после применения правил все еще остается неоднозначность в том, какое время жизни имеют ссылки, компилятор не будет угадывать, каким должно быть время жизни оставшихся ссылок. Вместо угадывания компилятор выдаст вам ошибку, которую вы можете разрешить, добавив аннотации времени жизни.
Время жизни для параметров функции или метода называются входными временами жизни (input lifetimes), а время жизни для возвращаемых значений называются выходными временами жизни (output lifetimes).
Компилятор использует три правила, чтобы выяснить время жизни ссылок, когда нет явных аннотаций. Первое правило применяется к входным временам жизни, а второе и третье правила применяются к выходным временам жизни. Если компилятор доходит до конца трех правил и все еще остаются ссылки, для которых он не может выяснить время жизни, компилятор остановится с ошибкой. Эти правила применяются к определениям fn, а также к блокам impl.
Первое правило заключается в том, что компилятор присваивает параметр времени жизни каждому параметру, который является ссылкой. Другими словами, функция с одним параметром получает один параметр времени жизни: fn foo<'a>(x: &'a i32); функция с двумя параметрами получает два отдельных параметра времени жизни: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); и так далее.
Второе правило заключается в том, что если есть ровно один входной параметр времени жизни, это время жизни присваивается всем выходным параметрам времени жизни: fn foo<'a>(x: &'a i32) -> &'a i32.
Третье правило заключается в том, что если есть несколько входных параметров времени жизни, но один из них — &self или &mut self, потому что это метод, время жизни self присваивается всем выходным параметрам времени жизни. Это третье правило делает методы намного приятнее для чтения и написания, потому что требуется меньше символов.
Давайте представим, что мы компилятор. Мы применим эти правила, чтобы выяснить время жизни ссылок в сигнатуре функции first_word в Листинге 10-25. Сигнатура начинается без каких-либо времен жизни, связанных со ссылками:
fn first_word(s: &str) -> &str {Затем компилятор применяет первое правило, которое указывает, что каждый параметр получает свое собственное время жизни. Мы назовем его 'a как обычно, так что теперь сигнатура такая:
fn first_word<'a>(s: &'a str) -> &str {Применяется второе правило, потому что есть ровно один входной параметр времени жизни. Второе правило указывает, что время жизни одного входного параметра присваивается выходному времени жизни, так что сигнатура теперь такая:
fn first_word<'a>(s: &'a str) -> &'a str {Теперь все ссылки в этой сигнатуре функции имеют время жизни, и компилятор может продолжить свой анализ без необходимости аннотировать время жизни в этой сигнатуре функции.
Давайте рассмотрим другой пример, на этот раз используя функцию longest, у которой не было параметров времени жизни, когда мы начали работать с ней в Листинге 10-20:
fn longest(x: &str, y: &str) -> &str {Применим первое правило: каждый параметр получает свое собственное время жизни. На этот раз у нас два параметра вместо одного, так что у нас два времени жизни:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Вы можете видеть, что второе правило не применяется, потому что есть более одного входного времени жизни. Третье правило тоже не применяется, потому что longest — это функция, а не метод, так что ни один из параметров не является self. Пройдя все три правила, мы все еще не выяснили, какое время жизни у возвращаемого типа. Вот почему мы получили ошибку при попытке скомпилировать код в Листинге 10-20: компилятор проработал правила сокрытия времени жизни, но все еще не смог выяснить все времени жизни ссылок в сигнатуре.
Поскольку третье правило действительно применяется только в сигнатурах методов, мы рассмотрим время жизни в этом контексте далее, чтобы понять, почему третье правило означает, что нам не нужно аннотировать время жизни в сигнатурах методов очень часто.
В определениях методов
Когда мы реализуем методы для структуры с временем жизни, мы используем тот же синтаксис, что и для параметров обобщенного типа, как показано в Листинге 10-11. Где мы объявляем и используем параметры времени жизни, зависит от того, связаны ли они с полями структуры или с параметрами методов и возвращаемыми значениями.
Имена времени жизни для полей структуры всегда нужно объявлять после ключевого слова impl и затем использовать после имени структуры, потому что эти времени жизни являются частью типа структуры.
В сигнатурах методов внутри блока impl ссылки могут быть привязаны ко времени жизни ссылок в полях структуры, или они могут быть независимыми. Кроме того, правила сокрытия времени жизни часто делают так, что аннотации времени жизни не нужны в сигнатурах методов. Давайте рассмотрим несколько примеров, используя структуру с именем ImportantExcerpt, которую мы определили в Листинге 10-24.
Сначала мы используем метод с именем level, единственный параметр которого — ссылка на self, и возвращаемое значение — i32, которое не является ссылкой на что-либо:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Объявление параметра времени жизни после impl и его использование после имени типа обязательны, но из-за первого правила сокрытия мы не обязаны аннотировать время жизни ссылки на self.
Вот пример, где применяется третье правило сокрытия времени жизни:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Есть два входных времени жизни, поэтому Rust применяет первое правило сокрытия времени жизни и дает и &self, и announcement свои собственные времени жизни. Затем, потому что один из параметров — &self, возвращаемый тип получает время жизни &self, и все времени жизни учтены.
Статическое время жизни
Одно специальное время жизни, которое нам нужно обсудить, — это 'static, которое обозначает, что затронутая ссылка может жить в течение всей продолжительности программы. Все строковые литералы имеют время жизни 'static, которое мы можем аннотировать следующим образом:
#![allow(unused)] fn main() { let s: &'static str = "I have a static lifetime."; }
Текст этой строки хранится непосредственно в бинарном файле программы, который всегда доступен. Следовательно, время жизни всех строковых литералов — 'static.
Вы можете видеть предложения в сообщениях об ошибках использовать время жизни 'static. Но прежде чем указывать 'static как время жизни для ссылки, подумайте, действительно ли ссылка, которую вы имеете, живет всю жизнь вашей программы, и хотите ли вы этого. Большую часть времени сообщение об ошибке, предлагающее время жизни 'static, является результатом попытки создать висячую ссылку или несоответствия доступных времен жизни. В таких случаях решение — исправить эти проблемы, а не указывать время жизни 'static.
Параметры обобщенного типа, ограничения типажей и время жизни
Давайте кратко рассмотрим синтаксис указания параметров обобщенного типа, ограничений типажей и времени жизни все в одной функции!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {result}"); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {ann}"); if x.len() > y.len() { x } else { y } }
Это функция longest из Листинга 10-21, которая возвращает более длинный из двух строковых срезов. Но теперь у нее есть дополнительный параметр с именем ann обобщенного типа T, который может быть заполнен любым типом, реализующим типаж Display, как указано в предложении where. Этот дополнительный параметр будет напечатан с использованием {}, поэтому ограничение типажа Display необходимо. Поскольку время жизни — это разновидность обобщенного параметра, объявления параметра времени жизни 'a и параметра обобщенного типа T идут в одном списке внутри угловых скобок после имени функции.
Итог
Мы охватили многое в этой главе! Теперь, когда вы знаете о параметрах обобщенного типа, типажах и ограничениях типажей, и параметрах обобщенного времени жизни, вы готовы писать код без повторений, который работает во многих разных ситуациях. Параметры обобщенного типа позволяют применять код к разным типам. Типажи и ограничения типажей гарантируют, что даже хотя типы обобщенные, они будут иметь поведение, необходимое коду. Вы узнали, как использовать аннотации времени жизни, чтобы гарантировать, что этот гибкий код не будет иметь висячих ссылок. И весь этот анализ происходит во время компиляции, что не влияет на производительность во время выполнения!
Верьте или нет, но есть еще много чего узнать по темам, которые мы обсудили в этой главе: Глава 18 обсуждает типаж-объекты, которые являются другим способом использования типажей. Также есть более сложные сценарии с аннотациями времени жизни, которые вам понадобятся только в очень продвинутых сценариях; для них вам следует прочитать . Но далее вы узнаете, как писать тесты в Rust, чтобы вы могли убедиться, что ваш код работает так, как должен.
Функциональные возможности языка: Итераторы и Замыкания
Дизайн Rust вдохновлен многими существующими языками и техниками, и одним значительным влиянием является функциональное программирование. Программирование в функциональном стиле часто включает использование функций в качестве значений путем передачи их в аргументы, возврата из других функций, присваивания переменным для последующего выполнения и так далее.
В этой главе мы не будем обсуждать вопрос о том, что такое функциональное программирование, а что нет, а вместо этого рассмотрим некоторые особенности Rust, которые похожи на features во многих языках, обычно называемых функциональными.
Если конкретнее, мы рассмотрим:
- Замыкания (closures) — конструкцию, похожую на функцию, которую можно сохранить в переменной
- Итераторы (iterators) — способ обработки последовательности элементов
- Как использовать замыкания и итераторы для улучшения проекта I/O из главы 12
- Производительность замыканий и итераторов (внимание, спойлер: они быстрее, чем вы могли подумать!)
Мы уже рассмотрели некоторые другие возможности Rust, такие как сопоставление с образцом (pattern matching) и перечисления (enums), которые также находятся под влиянием функционального стиля. Поскольку освоение замыканий и итераторов является важной частью написания быстрого, идиоматического кода на Rust, мы посвятим им всю эту главу.
Замыкания
Замыкания в Rust — это анонимные функции, которые можно сохранять в переменных или передавать в качестве аргументов другим функциям. Вы можете создать замыкание в одном месте, а затем вызвать его в другом месте для вычисления в другом контексте. В отличие от функций, замыкания могут захватывать значения из области видимости, в которой они определены. Мы продемонстрируем, как эти возможности замыканий позволяют повторно использовать код и настраивать поведение.
Захват окружения
Сначала мы рассмотрим, как можно использовать замыкания для захвата значений из окружения, в котором они определены, для последующего использования. Вот сценарий: Время от времени наша компания по производству футболок раздает эксклюзивные футболки ограниченного выпуска кому-то из нашего списка рассылки в качестве акции. Люди в списке рассылки могут по желанию добавить свой любимый цвет в свой профиль. Если выбранный для бесплатной футболки человек указал свой любимый цвет, он получает футболку этого цвета. Если человек не указал любимый цвет, он получает тот цвет, которого у компании в настоящее время больше всего.
Есть много способов реализовать это. Для этого примера мы будем использовать перечисление ShirtColor с вариантами Red и Blue (ограничивая количество доступных цветов для простоты). Мы представляем инвентарь компании с помощью структуры Inventory, которая имеет поле shirts, содержащее Vec<ShirtColor>, представляющее цвета футболок, currently имеющиеся в наличии. Метод giveaway, определенный для Inventory, получает необязательное предпочтение по цвету футболки для победителя раздачи и возвращает цвет футболки, который получит человек. Эта настройка показана в листинге 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}store, определенный в main, имеет две синие футболки и одну красную, оставшиеся для распределения в этой акции ограниченного выпуска. Мы вызываем метод giveaway для пользователя с предпочтением красной футболки и пользователя без каких-либо предпочтений.
Повторюсь, этот код можно реализовать разными способами, и здесь, чтобы сосредоточиться на замыканиях, мы придерживались концепций, которые вы уже изучили, за исключением тела метода giveaway, которое использует замыкание. В методе giveaway мы получаем предпочтение пользователя в качестве параметра типа Option<ShirtColor> и вызываем метод unwrap_or_else для user_preference. Метод unwrap_or_else для Option<T> определен в стандартной библиотеке. Он принимает один аргумент: замыкание без каких-либо аргументов, которое возвращает значение T (тот же тип, что хранится в варианте Some из Option<T>, в данном случае ShirtColor). Если Option<T> является вариантом Some, unwrap_or_else возвращает значение из Some. Если Option<T> является вариантом None, unwrap_or_else вызывает замыкание и возвращает значение, возвращенное замыканием.
Мы указываем выражение замыкания || self.most_stocked() в качестве аргумента для unwrap_or_else. Это замыкание, которое само не принимает параметров (если бы у замыкания были параметры, они бы появились между двумя вертикальными чертами). Тело замыкания вызывает self.most_stocked(). Мы определяем замыкание здесь, а реализация unwrap_or_else вычислит замыкание позже, если результат будет нужен.
Запуск этого кода выводит следующее:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Один интересный аспект здесь заключается в том, что мы передали замыкание, которое вызывает self.most_stocked() для текущего экземпляра Inventory. Стандартной библиотеке не нужно было знать ничего о типах Inventory или ShirtColor, которые мы определили, или о логике, которую мы хотим использовать в этом сценарии. Замыкание захватывает неизменяемую ссылку на экземпляр self Inventory и передает ее с указанным нами кодом в метод unwrap_or_else. Функции, с другой стороны, не могут захватывать свое окружение таким образом.
Вывод и аннотирование типов замыканий
Между функциями и замыканиями есть больше различий. Замыкания обычно не требуют от вас аннотирования типов параметров или возвращаемого значения, как это делают функции fn. Аннотации типов требуются для функций, потому что типы являются частью явного интерфейса, предоставляемого вашим пользователям. Жесткое определение этого интерфейса важно для обеспечения того, чтобы все соглашались с тем, какие типы значений использует и возвращает функция. Замыкания, с другой стороны, не используются в открытом интерфейсе подобным образом: они хранятся в переменных и используются без их именования и предоставления пользователям нашей библиотеки.
Замыкания обычно короткие и актуальны только в узком контексте, а не в любом произвольном сценарии. В этих ограниченных контекстах компилятор может вывести типы параметров и тип возвращаемого значения, подобно тому, как он может выводить типы большинства переменных (бывают редкие случаи, когда компилятору также нужны аннотации типов замыканий).
Как и с переменными, мы можем добавлять аннотации типов, если хотим повысить явность и ясность за счет большей многословности, чем это strictly необходимо. Аннотирование типов для замыкания будет выглядеть как определение, показанное в листинге 13-2. В этом примере мы определяем замыкание и сохраняем его в переменной, а не определяем замыкание в том месте, где мы передаем его в качестве аргумента, как мы делали в листинге 13-1.
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
С добавленными аннотациями типов синтаксис замыканий выглядит более похожим на синтаксис функций. Здесь мы определяем функцию, которая добавляет 1 к своему параметру, и замыкание, которое имеет такое же поведение, для сравнения. Мы добавили некоторые пробелы, чтобы выровнять соответствующие части. Это иллюстрирует, как синтаксис замыканий похож на синтаксис функций, за исключением использования вертикальных черт и количества синтаксиса, который является необязательным:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Первая строка показывает определение функции, а вторая строка показывает полностью аннотированное определение замыкания. В третьей строке мы удаляем аннотации типов из определения замыкания. В четвертой строке мы удаляем фигурные скобки, которые являются необязательными, потому что тело замыкания имеет только одно выражение. Все это допустимые определения, которые будут производить одинаковое поведение при вызове. Строки add_one_v3 и add_one_v4 требуют, чтобы замыкания были вычислены, чтобы иметь возможность скомпилироваться, потому что типы будут выведены из их использования. Это похоже на let v = Vec::new();, которой нужны либо аннотации типов, либо значения некоторого типа, вставленные в Vec, чтобы Rust мог вывести тип.
Для определений замыканий компилятор будет выводить один конкретный тип для каждого из их параметров и для их возвращаемого значения. Например, листинг 13-3 показывает определение короткого замыкания, которое просто возвращает значение, которое оно получает в качестве параметра. Это замыкание не очень полезно, за исключением целей этого примера. Обратите внимание, что мы не добавили никаких аннотаций типов к определению. Поскольку нет аннотаций типов, мы можем вызвать замыкание с любым типом, что мы и сделали здесь с String в первый раз. Если мы затем попытаемся вызвать example_closure с целым числом, мы получим ошибку.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Компилятор выдает нам эту ошибку:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
Когда мы в первый раз вызываем example_closure со значением String, компилятор выводит тип x и тип возвращаемого значения замыкания как String. Эти типы затем блокируются в замыкании в example_closure, и мы получаем ошибку типа, когда в следующий раз пытаемся использовать другой тип с тем же замыканием.
Захват ссылок или перенос владения
Замыкания могут захватывать значения из своего окружения тремя способами, которые напрямую соответствуют трем способам, которыми функция может принимать параметр: заимствование неизменяемо, заимствование изменяемо и взятие владения. Замыкание решит, какой из них использовать, на основе того, что тело функции делает с захваченными значениями.
В листинге 13-4 мы определяем замыкание, которое захватывает неизменяемую ссылку на вектор с именем list, потому что ему нужна только неизменяемая ссылка для вывода значения.
fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let only_borrows = || println!("From closure: {list:?}"); println!("Before calling closure: {list:?}"); only_borrows(); println!("After calling closure: {list:?}"); }
Этот пример также иллюстрирует, что переменная может быть привязана к определению замыкания, и мы можем позже вызвать замыкание, используя имя переменной и круглые скобки, как если бы имя переменной было именем функции.
Поскольку у нас может быть несколько неизменяемых ссылок на list одновременно, list все еще доступен из кода до определения замыкания, после определения замыкания, но до вызова замыкания, и после вызова замыкания. Этот код компилируется, запускается и выводит:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Далее, в листинге 13-5, мы изменяем тело замыкания так, чтобы оно добавляло элемент в вектор list. Замыкание теперь захватывает изменяемую ссылку.
fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let mut borrows_mutably = || list.push(7); borrows_mutably(); println!("After calling closure: {list:?}"); }
Этот код компилируется, запускается и выводит:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Обратите внимание, что больше нет println! между определением и вызовом замыкания borrows_mutably: Когда borrows_mutably определяется, оно захватывает изменяемую ссылку на list. Мы не используем замыкание снова после вызова замыкания, поэтому изменяемое заимствование заканчивается. Между определением замыкания и вызовом замыкания неизменяемое заимствование для вывода не допускается, потому что никакие другие заимствования не разрешены, когда есть изменяемое заимствование. Попробуйте добавить println! там, чтобы увидеть, какое сообщение об ошибке вы получите!
Если вы хотите заставить замыкание взять владение значениями, которые оно использует в окружении, даже если тело замыкания strictly не нуждается во владении, вы можете использовать ключевое слово move перед списком параметров.
Эта техника в основном полезна при передаче замыкания в новый поток для перемещения данных, чтобы они принадлежали новому потоку. Мы подробно обсудим потоки и то, зачем вам их использовать, в главе 16, когда будем говорить о параллелизме, а сейчас давайте кратко рассмотрим порождение нового потока с использованием замыкания, которому нужно ключевое слово move. Листинг 13-6 показывает листинг 13-4, измененный для вывода вектора в новом потоке, а не в основном потоке.
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); thread::spawn(move || println!("From thread: {list:?}")) .join() .unwrap(); }
Мы порождаем новый поток, передавая потоку замыкание для запуска в качестве аргумента. Тело замыкания выводит список. В листинге 13-4 замыкание захватывало list только с помощью неизменяемой ссылки, потому что это минимальный доступ к list, необходимый для его вывода. В этом примере, даже though тело замыкания все еще нуждается только в неизменяемой ссылке, нам нужно указать, что list должен быть перемещен в замыкание, поместив ключевое слово move в начало определения замыкания. Если бы основной поток выполнял больше операций перед вызовом join для нового потока, новый поток мог бы завершиться до завершения остальной части основного потока, или основной поток мог бы завершиться первым. Если бы основной поток сохранял владение list, но завершался до нового потока и удалял list, неизменяемая ссылка в потоке была бы недействительной. Поэтому компилятор требует, чтобы list был перемещен в замыкание, переданное новому потоку, чтобы ссылка была действительной. Попробуйте удалить ключевое слово move или использовать list в основном потоке после определения замыкания, чтобы увидеть, какие ошибки компилятора вы получите!
Перемещение захваченных значений из замыканий
После того как замыкание захватило ссылку или владение значением из окружения, где замыкание определено (таким образом влияя на то, что, если вообще что-либо, перемещается в замыкание), код в теле замыкания определяет, что происходит со ссылками или значениями, когда замыкание вычисляется позже (таким образом влияя на то, что, если вообще что-либо, перемещается из замыкания).
Тело замыкания может делать любое из следующего: перемещать захваченное значение из замыкания, изменять захваченное значение, ни перемещать, ни изменять значение или изначально ничего не захватывать из окружения.
То, как замыкание захватывает и обрабатывает значения из окружения, влияет на то, какие трейты реализует замыкание, а трейты — это то, как функции и структуры могут указывать, какие виды замыканий они могут использовать. Замыкания будут автоматически реализовывать один, два или все три из этих трейтов Fn, аддитивно, в зависимости от того, как тело замыкания обрабатывает значения:
FnOnceприменяется к замыканиям, которые могут быть вызваны один раз. Все замыкания реализуют по крайней мере этот трейт, потому что все замыкания могут быть вызваны. Замыкание, которое перемещает захваченные значения из своего тела, будет реализовывать толькоFnOnceи никакие другие трейтыFn, потому что оно может быть вызвано только один раз.FnMutприменяется к замыканиям, которые не перемещают захваченные значения из своего тела, но могут изменять захваченные значения. Эти замыкания могут быть вызваны более одного раза.Fnприменяется к замыканиям, которые не перемещают захваченные значения из своего тела и не изменяют захваченные значения, а также к замыканиям, которые ничего не захватывают из своего окружения. Эти замыкания могут быть вызваны более одного раза без изменения их окружения, что важно в таких случаях, как многократный вызов замыкания concurrently.
Давайте посмотрим на определение метода unwrap_or_else для Option<T>, который мы использовали в листинге 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Напомним, что T — это обобщенный тип, представляющий тип значения в варианте Some из Option. Этот тип T также является типом возвращаемого значения функции unwrap_or_else: код, который вызывает unwrap_or_else для Option<String>, например, получит String.
Далее, обратите внимание, что функция unwrap_or_else имеет дополнительный параметр обобщенного типа F. Тип F — это тип параметра с именем f, который является замыканием, которое мы предоставляем при вызове unwrap_or_else.
Ограничение трейта, указанное для обобщенного типа F, — FnOnce() -> T, что означает, что F должен быть способен быть вызванным один раз, не принимать аргументов и возвращать T. Использование FnOnce в ограничении трейта выражает ограничение, что unwrap_or_else не будет вызывать f более одного раза. В теле unwrap_or_else мы можем видеть, что если Option — Some, f не будет вызвано. Если Option — None, f будет вызвано один раз. Поскольку все замыкания реализуют FnOnce, unwrap_or_else принимает все три вида замыканий и является настолько гибким, насколько это возможно.
Примечание: Если то, что мы хотим сделать, не требует захвата значения из окружения, мы можем использовать имя функции вместо замыкания, когда нам нужно что-то, что реализует один из трейтов
Fn. Например, для значенияOption<Vec<T>>мы могли бы вызватьunwrap_or_else(Vec::new), чтобы получить новый пустой вектор, если значение равноNone. Компилятор автоматически реализует любой из трейтовFn, который применим для определения функции.
Теперь давайте посмотрим на метод стандартной библиотеки sort_by_key, определенный для срезов, чтобы увидеть, чем он отличается от unwrap_or_else и почему sort_by_key использует FnMut вместо FnOnce для ограничения трейта. Замыкание получает один аргумент в виде ссылки на текущий элемент в рассматриваемом срезе и возвращает значение типа K, которое можно упорядочить. Эта функция полезна, когда вы хотите отсортировать срез по определенному атрибуту каждого элемента. В листинге 13-7 у нас есть список экземпляров Rectangle, и мы используем sort_by_key для упорядочивания их по атрибуту width от низкого к высокому.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; list.sort_by_key(|r| r.width); println!("{list:#?}"); }
Этот код выводит:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Причина, по которой sort_by_key определен для приема замыкания FnMut, заключается в том, что он вызывает замыкание несколько раз: один раз для каждого элемента в срезе. Замыкание |r| r.width не захватывает, не изменяет и не перемещает ничего из своего окружения, поэтому оно соответствует требованиям ограничения трейта.
В contrast, листинг 13-8 показывает пример замыкания, которое реализует только трейт FnOnce, потому что оно перемещает значение из окружения. Компилятор не позволит нам использовать это замыкание с sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}Это надуманный, запутанный способ (который не работает) попытаться подсчитать, сколько раз sort_by_key вызывает замыкание при сортировке list. Этот код пытается сделать это, помещая value — String из окружения замыкания — в вектор sort_operations. Замыкание захватывает value, а затем перемещает value из замыкания, передавая владение value вектору sort_operations. Это замыкание может быть вызвано один раз; попытка вызвать его второй раз не сработает, потому что value больше не будет в окружении, чтобы его снова поместить в sort_operations! Следовательно, это замыкание реализует только FnOnce. Когда мы пытаемся скомпилировать этот код, мы получаем эту ошибку, что value не может быть перемещено из замыкания, потому что замыкание должно реализовывать FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Ошибка указывает на строку в теле замыкания, которая перемещает value из окружения. Чтобы исправить это, нам нужно изменить тело замыкания так, чтобы оно не перемещало значения из окружения. Сохранение счетчика в окружении и увеличение его значения в теле замыкания — более straightforward способ подсчитать количество вызовов замыкания. Замыкание в листинге 13-9 работает с sort_by_key, потому что оно только захватывает изменяемую ссылку на счетчик num_sort_operations и, следовательно, может быть вызвано более одного раза.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; let mut num_sort_operations = 0; list.sort_by_key(|r| { num_sort_operations += 1; r.width }); println!("{list:#?}, sorted in {num_sort_operations} operations"); }
Трейты Fn важны при определении или использовании функций или типов, которые используют замыкания. В следующем разделе мы обсудим итераторы. Многие методы итераторов принимают аргументы-замыкания, так что помните об этих деталях замыканий, пока мы продолжаем!
Обработка последовательности элементов с помощью итераторов
Шаблон итератора позволяет вам выполнять некоторую задачу над последовательностью элементов по очереди. Итератор отвечает за логику перебора каждого элемента и определения того, когда последовательность завершилась. Когда вы используете итераторы, вам не нужно самостоятельно заново реализовывать эту логику.
В Rust итераторы ленивые (lazy), что означает, что они не оказывают никакого эффекта, пока вы не вызовете методы, которые потребляют итератор, чтобы использовать его. Например, код в листинге 13-10 создает итератор над элементами вектора v1, вызывая метод iter, определенный для Vec<T>. Сам по себе этот код ничего полезного не делает.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Итератор сохраняется в переменной v1_iter. После создания итератора мы можем использовать его различными способами. В листинге 3-5 мы перебирали массив с помощью цикла for, чтобы выполнить некоторый код для каждого из его элементов. Под капотом это неявно создавало и затем потребляло итератор, но мы упускали из виду, как именно это работает, до сих пор.
В примере в листинге 13-11 мы разделяем создание итератора от использования итератора в цикле for. Когда цикл for вызывается с использованием итератора в v1_iter, каждый элемент в итераторе используется в одной итерации цикла, которая выводит каждое значение.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {val}"); } }
В языках, где итераторы не предоставляются их стандартными библиотеками, вы, вероятно, написали бы эту же функциональность, начав с переменной с индексом 0, используя эту переменную для индексации в вектор, чтобы получить значение, и увеличивая значение переменной в цикле, пока оно не достигнет общего количества элементов в векторе.
Итераторы обрабатывают всю эту логику за вас, сокращая повторяющийся код, который вы потенциально могли бы испортить. Итераторы дают вам больше гибкости для использования той же логики со многими различными видами последовательностей, а не только со структурами данных, в которые можно индексировать, такие как векторы. Давайте рассмотрим, как итераторы это делают.
Трейт Iterator и метод next
Все итераторы реализуют трейт с именем Iterator, который определен в стандартной библиотеке. Определение трейта выглядит так:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // методы с реализациями по умолчанию опущены } }
Обратите внимание, что это определение использует новый синтаксис: type Item и Self::Item, которые определяют ассоциированный тип с этим трейтом. Мы поговорим об ассоциированных типах подробно в главе 20. Пока все, что вам нужно знать, это то, что этот код говорит, что реализация трейта Iterator требует, чтобы вы также определили тип Item, и этот тип Item используется в возвращаемом типе метода next. Другими словами, тип Item будет типом, возвращаемым из итератора.
Трейт Iterator требует от реализаторов определения только одного метода: метода next, который возвращает один элемент итератора за раз, завернутый в Some, и, когда перебор завершен, возвращает None.
Мы можем вызывать метод next на итераторах напрямую; листинг 13-12 демонстрирует, какие значения возвращаются из повторных вызовов next на итераторе, созданном из вектора.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Обратите внимание, что нам нужно было сделать v1_iter изменяемым: вызов метода next на итераторе изменяет внутреннее состояние, которое итератор использует для отслеживания своего места в последовательности. Другими словами, этот код потребляет (consumes) или использует итератор. Каждый вызов next "съедает" элемент из итератора. Нам не нужно было делать v1_iter изменяемым, когда мы использовали цикл for, потому что цикл взял владение v1_iter и сделал его изменяемым за кулисами.
Также обратите внимание, что значения, которые мы получаем из вызовов next, являются неизменяемыми ссылками на значения в векторе. Метод iter создает итератор по неизменяемым ссылкам. Если мы хотим создать итератор, который берет владение v1 и возвращает принадлежащие значения, мы можем вызвать into_iter вместо iter. Аналогично, если мы хотим перебирать изменяемые ссылки, мы можем вызвать iter_mut вместо iter.
Методы, которые потребляют итератор
Трейт Iterator имеет ряд различных методов с реализациями по умолчанию, предоставляемыми стандартной библиотекой; вы можете узнать об этих методах, посмотрев в документации API стандартной библиотеки для трейта Iterator. Некоторые из этих методов вызывают метод next в своем определении, поэтому при реализации трейта Iterator от вас требуется реализовать метод next.
Методы, которые вызывают next, называются потребляющими адаптерами (consuming adapters), потому что их вызов использует итератор. Один пример — метод sum, который берет владение итератором и перебирает элементы, повторно вызывая next, таким образом потребляя итератор. Во время перебора он добавляет каждый элемент к текущей сумме и возвращает сумму, когда перебор завершен. В листинге 13-13 есть тест, иллюстрирующий использование метода sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Нам не разрешено использовать v1_iter после вызова sum, потому что sum берет владение итератором, у которого мы его вызываем.
Методы, которые производят другие итераторы
Адаптеры итераторов (Iterator adapters) — это методы, определенные в трейте Iterator, которые не потребляют итератор. Вместо этого они производят разные итераторы, изменяя некоторый аспект исходного итератора.
Листинг 13-14 показывает пример вызова метода адаптера итератора map, который принимает замыкание для вызова на каждом элементе во время перебора. Метод map возвращает новый итератор, который производит измененные элементы. Замыкание здесь создает новый итератор, в котором каждый элемент из вектора будет увеличен на 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
Однако этот код выдает предупреждение:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Код в листинге 13-14 ничего не делает; указанное нами замыкание никогда не вызывается. Предупреждение напоминает нам, почему: адаптеры итераторов ленивы, и нам нужно потребить итератор здесь.
Чтобы исправить это предупреждение и потребить итератор, мы используем метод collect, который мы использовали с env::args в листинге 12-1. Этот метод потребляет итератор и собирает результирующие значения в тип коллекции.
В листинге 13-15 мы собираем результаты перебора по итератору, который возвращается из вызова map, в вектор. Этот вектор в конечном итоге будет содержать каждый элемент из исходного вектора, увеличенный на 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
Поскольку map принимает замыкание, мы можем указать любую операцию, которую хотим выполнить над каждым элементом. Это отличный пример того, как замыкания позволяют вам настраивать некоторое поведение, повторно используя поведение итерации, которое предоставляет трейт Iterator.
Вы можете объединять несколько вызовов адаптеров итераторов для выполнения сложных действий в удобочитаемом виде. Но поскольку все итераторы ленивы, вы должны вызвать один из методов потребляющих адаптеров, чтобы получить результаты от вызовов адаптеров итераторов.
Замыкания, которые захватывают свое окружение
Многие адаптеры итераторов принимают замыкания в качестве аргументов, и обычно замыкания, которые мы будем указывать в качестве аргументов для адаптеров итераторов, будут замыканиями, которые захватывают свое окружение.
Для этого примера мы будем использовать метод filter, который принимает замыкание. Замыкание получает элемент из итератора и возвращает bool. Если замыкание возвращает true, значение будет включено в итерацию, производимую filter. Если замыкание возвращает false, значение не будет включено.
В листинге 13-16 мы используем filter с замыканием, которое захватывает переменную shoe_size из своего окружения, чтобы перебирать коллекцию экземпляров структуры Shoe. Он вернет только туфли указанного размера.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Функция shoes_in_size принимает владение вектором туфель и размер обуви в качестве параметров. Она возвращает вектор, содержащий только туфли указанного размера.
В теле shoes_in_size мы вызываем into_iter, чтобы создать итератор, который берет владение вектором. Затем мы вызываем filter, чтобы адаптировать этот итератор в новый итератор, который содержит только элементы, для которых замыкание возвращает true.
Замыкание захватывает параметр shoe_size из окружения и сравнивает значение с размером каждой туфли, оставляя только туфли указанного размера. Наконец, вызов collect собирает значения, возвращаемые адаптированным итератором, в вектор, который возвращается функцией.
Тест показывает, что когда мы вызываем shoes_in_size, мы получаем обратно только туфли, которые имеют тот же размер, что и значение, которое мы указали.
Улучшение нашего I/O проекта
С этими новыми знаниями об итераторах мы можем улучшить I/O проект из главы 12, используя итераторы, чтобы сделать места в коде более понятными и краткими. Давайте посмотрим, как итераторы могут улучшить нашу реализацию функции Config::build и функции search.
Удаление clone с помощью итератора
В листинге 12-6 мы добавили код, который брал срез значений String и создавал экземпляр структуры Config путем индексации в срез и клонирования значений, позволяя структуре Config владеть этими значениями. В листинге 13-17 мы воспроизвели реализацию функции Config::build такой, какой она была в листинге 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}В то время мы сказали не беспокоиться о неэффективных вызовах clone, потому что мы удалим их в будущем. Что ж, это время настало!
Нам нужен был clone здесь, потому что у нас есть срез с элементами String в параметре args, но функция build не владеет args. Чтобы вернуть владение экземпляром Config, мы должны были клонировать значения из полей query и file_path структуры Config, чтобы экземпляр Config мог владеть своими значениями.
С нашими новыми знаниями об итераторах мы можем изменить функцию build, чтобы она принимала владение итератором в качестве своего аргумента вместо заимствования среза. Мы будем использовать функциональность итератора вместо кода, который проверяет длину среза и индексируется в определенные места. Это прояснит, что делает функция Config::build, потому что итератор будет обращаться к значениям.
Как только Config::build возьмет владение итератором и перестанет использовать операции индексирования, которые заимствуют, мы сможем переместить значения String из итератора в Config, вместо вызова clone и создания нового выделения памяти.
Использование возвращенного итератора напрямую
Откройте файл src/main.rs вашего I/O проекта, который должен выглядеть так:
Файл: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Сначала мы изменим начало функции main, которая у нас была в листинге 12-24, на код в листинге 13-18, который на этот раз использует итератор. Это не скомпилируется, пока мы не обновим Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Функция env::args возвращает итератор! Вместо сбора значений итератора в вектор и затем передачи среза в Config::build, теперь мы передаем владение итератором, возвращенным из env::args, непосредственно в Config::build.
Далее нам нужно обновить определение Config::build. Давайте изменим сигнатуру Config::build, чтобы она выглядела как в листинге 13-19. Это все еще не скомпилируется, потому что нам нужно обновить тело функции.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Документация стандартной библиотеки для функции env::args показывает, что тип возвращаемого итератора — std::env::Args, и этот тип реализует трейт Iterator и возвращает значения String.
Мы обновили сигнатуру функции Config::build так, что параметр args имеет обобщенный тип с ограничениями трейта impl Iterator<Item = String> вместо &[String]. Это использование синтаксиса impl Trait, который мы обсуждали в разделе «Использование трейтов в качестве параметров» главы 10, означает, что args может быть любым типом, который реализует трейт Iterator и возвращает элементы String.
Поскольку мы берем владение args и будем изменять args, итерируясь по нему, мы можем добавить ключевое слово mut в спецификацию параметра args, чтобы сделать его изменяемым.
Использование методов трейта Iterator
Далее мы исправим тело Config::build. Поскольку args реализует трейт Iterator, мы знаем, что можем вызвать на нем метод next! Listing 13-20 обновляет код из листинга 12-23 для использования метода next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Помните, что первое значение в возвращаемом значении env::args — это имя программы. Мы хотим проигнорировать его и перейти к следующему значению, поэтому сначала мы вызываем next и ничего не делаем с возвращаемым значением. Затем мы вызываем next, чтобы получить значение, которое мы хотим поместить в поле query структуры Config. Если next возвращает Some, мы используем match для извлечения значения. Если он возвращает None, это означает, что было предоставлено недостаточно аргументов, и мы досрочно возвращаем значение Err. Мы делаем то же самое для значения file_path.
Упрощение кода с помощью адаптеров итераторов
Мы также можем воспользоваться итераторами в функции search нашего I/O проекта, которая воспроизведена здесь в листинге 13-21 такой, какой она была в листинге 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Мы можем написать этот код более кратко, используя методы адаптеров итераторов. Это также позволяет нам избежать наличия изменяемого промежуточного вектора results. Функциональный стиль программирования предпочитает минимизировать количество изменяемого состояния, чтобы сделать код более понятным. Удаление изменяемого состояния может позволить в будущем улучшить возможность параллельного поиска, потому что нам не придется управлять параллельным доступом к вектору results. Листинг 13-22 показывает это изменение.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Напомним, что цель функции search — вернуть все строки в contents, которые содержат query. Подобно примеру с filter в листинге 13-16, этот код использует адаптер filter, чтобы сохранить только те строки, для которых line.contains(query) возвращает true. Затем мы собираем соответствующие строки в другой вектор с помощью collect. Намного проще! Не стесняйтесь сделать такое же изменение, чтобы использовать методы итераторов в функции search_case_insensitive.
Для дальнейшего улучшения верните итератор из функции search, удалив вызов collect и изменив тип возвращаемого значения на impl Iterator<Item = &'a str>, чтобы функция стала адаптером итератора. Обратите внимание, что вам также нужно будет обновить тесты! Поищите в большом файле с помощью вашего инструмента minigrep до и после внесения этого изменения, чтобы наблюдать разницу в поведении. До этого изменения программа не будет печатать никаких результатов, пока не соберет все результаты, но после изменения результаты будут печататься по мере нахождения каждой соответствующей строки, потому что цикл for в функции run сможет воспользоваться ленивостью итератора.
Выбор между циклами и итераторами
Следующий логический вопрос — какой стиль вы должны выбрать в своем собственном коде и почему: исходную реализацию из листинга 13-21 или версию с использованием итераторов из листинга 13-22 (предполагая, что мы собираем все результаты перед возвратом, а не возвращаем итератор). Большинство программистов на Rust предпочитают использовать стиль итераторов. Сначала к нему немного сложнее привыкнуть, но как только вы почувствуете различные адаптеры итераторов и то, что они делают, итераторы могут стать легче для понимания. Вместо возни с различными частями циклов и построения новых векторов код сосредотачивается на высокоуровневой цели цикла. Это абстрагирует некоторую стандартную часть кода, чтобы было легче увидеть концепции, уникальные для этого кода, такие как условие фильтрации, которое каждый элемент в итераторе должен пройти.
Но действительно ли две реализации эквивалентны? Интуитивное предположение может заключаться в том, что низкоуровневый цикл будет быстрее. Давайте поговорим о производительности.
Производительность циклов против итераторов
Чтобы определить, использовать ли циклы или итераторы, вам нужно знать, какая реализация быстрее: версия функции search с явным циклом for или версия с итераторами.
Мы провели бенчмарк, загрузив полное содержание «Приключений Шерлока Холмса» сэра Артура Конан Дойла в String и выполнив поиск слова the в содержимом. Вот результаты бенчмарка для версии search с использованием цикла for и версии с использованием итераторов:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Две реализации имеют схожую производительность! Мы не будем объяснять здесь код бенчмарка, потому что суть не в том, чтобы доказать, что две версии эквивалентны, а в том, чтобы получить общее представление о том, как эти две реализации сравниваются по производительности.
Для более комплексного бенчмарка вам следует проверить использование различных текстов разных размеров в качестве contents, разных слов и слов разной длины в качестве query и всевозможных других вариаций. Суть в следующем: итераторы, хотя и являются абстракцией высокого уровня, компилируются примерно в тот же код, как если бы вы написали низкоуровневый код самостоятельно. Итераторы — это одна из абстракций с нулевой стоимостью (zero-cost abstractions) в Rust, под которой мы подразумеваем, что использование абстракции не накладывает дополнительных накладных расходов во время выполнения. Это аналогично тому, как Бьёрн Страуструп, оригинальный дизайнер и реализатор C++, определяет нулевую стоимость в своей ключевой презентации 2012 года ETAPS «Основы C++»:
В общем случае реализации C++ подчиняются принципу нулевой стоимости: за то, что вы не используете, вы не платите. И далее: то, что вы используете, вы не смогли бы написать вручную лучше.
Во многих случаях Rust-код, использующий итераторы, компилируется в тот же ассемблерный код, который вы написали бы вручную. Оптимизации, такие как развертывание циклов (loop unrolling) и устранение проверок границ при доступе к массиву, применяются и делают результирующий код чрезвычайно эффективным. Теперь, когда вы это знаете, вы можете использовать итераторы и замыкания без страха! Они делают код более высокоуровневым, но не накладывают штрафа за производительность во время выполнения за это.
Итоги
Замыкания и итераторы — это возможности Rust, вдохновленные идеями функционального программирования. Они способствуют возможности Rust четко выражать высокоуровневые идеи при низкоуровневой производительности. Реализации замыканий и итераторов таковы, что производительность во время выполнения не страдает. Это часть цели Rust — стремиться предоставлять абстракции с нулевой стоимостью.
Теперь, когда мы улучшили выразительность нашего I/O проекта, давайте рассмотрим некоторые другие возможности cargo, которые помогут нам поделиться проектом с миром.
Дополнительная информация о Cargo и Crates.io
До сих пор мы использовали только самые базовые возможности Cargo для сборки, запуска и тестирования нашего кода, но он умеет гораздо больше. В этой главе мы обсудим некоторые другие, более продвинутые его функции, чтобы показать вам, как делать следующее:
- Настраивать сборку с помощью профилей выпуска.
- Публиковать библиотеки на crates.io.
- Организовывать крупные проекты с помощью рабочих пространств (workspaces).
- Устанавливать исполняемые файлы (бинарные crates) с crates.io.
- Расширять Cargo с помощью пользовательских команд.
Cargo может делать даже больше, чем функциональность, рассмотренная в этой главе, поэтому для полного объяснения всех его функций см. его документацию.
Настройка сборки с помощью профилей выпуска
В Rust профили выпуска (release profiles) — это предопределённые, настраиваемые профили с различными конфигурациями, которые позволяют программисту более тонко контролировать различные параметры компиляции кода. Каждый профиль настраивается независимо от других.
В Cargo есть два основных профиля: профиль dev, который Cargo использует, когда вы выполняете cargo build, и профиль release, который Cargo использует при выполнении cargo build --release. Профиль dev настроен с хорошими значениями по умолчанию для разработки, а профиль release имеет хорошие значения по умолчанию для сборок выпуска.
Эти названия профилей могут быть знакомы вам по выводу ваших сборок:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev и release — это и есть те самые разные профили, используемые компилятором.
Cargo имеет настройки по умолчанию для каждого из профилей, которые применяются, если вы не добавили явно никаких секций [profile.*] в файле Cargo.toml проекта. Добавляя секции [profile.*] для любого профиля, который вы хотите настроить, вы переопределяете любое подмножество настроек по умолчанию. Например, вот значения по умолчанию для настройки opt-level для профилей dev и release:
Файл: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Настройка opt-level управляет количеством оптимизаций, которые Rust применит к вашему коду, в диапазоне от 0 до 3. Применение большего количества оптимизаций увеличивает время компиляции, поэтому если вы находитесь в стадии разработки и часто компилируете код, вам нужно меньше оптимизаций для более быстрой компиляции, даже если итоговый код будет выполняться медленнее. Поэтому значение opt-level по умолчанию для dev равно 0. Когда вы готовы выпустить код, лучше потратить больше времени на компиляцию. Вы будете компилировать в режиме выпуска только один раз, но скомпилированную программу будете запускать много раз, поэтому режим выпуска (release) жертвует временем компиляции ради более быстрого выполнения кода. Вот почему значение opt-level по умолчанию для профиля release равно 3.
Вы можете переопределить настройку по умолчанию, добавив для неё другое значение в Cargo.toml. Например, если мы хотим использовать уровень оптимизации 1 в профиле разработки, мы можем добавить следующие две строки в файл Cargo.toml нашего проекта:
Файл: Cargo.toml
[profile.dev]
opt-level = 1
Этот код переопределяет значение по умолчанию 0. Теперь, когда мы запустим cargo build, Cargo будет использовать настройки по умолчанию для профиля dev плюс нашу пользовательскую настройку opt-level. Поскольку мы установили opt-level в 1, Cargo применит больше оптимизаций, чем по умолчанию, но не так много, как в сборке выпуска.
Для получения полного списка параметров конфигурации и их значений по умолчанию для каждого профиля см. документацию Cargo.
Публикация крейта на Crates.io
Мы использовали пакеты с crates.io как зависимости для нашего проекта, но вы также можете поделиться своим кодом с другими людьми, опубликовав собственные пакеты. Реестр крейтов на crates.io распространяет исходный код ваших пакетов, поэтому он в основном размещает код с открытым исходным кодом.
Rust и Cargo имеют функции, которые облегчают другим людям поиск и использование вашего опубликованного пакета. Далее мы поговорим о некоторых из этих функций, а затем объясним, как опубликовать пакет.
Создание полезных комментариев документации
Качественная документация ваших пакетов поможет другим пользователям понять, как и когда их использовать, поэтому стоит потратить время на написание документации. В главе 3 мы обсуждали, как комментировать код на Rust с помощью двух слешей, //. В Rust также есть особый вид комментариев для документации, известный как комментарии документации, который генерирует HTML-документацию. HTML отображает содержимое комментариев документации для элементов публичного API, предназначенных для программистов, которые хотят знать, как использовать ваш крейт, а не то, как он реализован.
Комментарии документации используют три слеша, ///, вместо двух и поддерживают нотацию Markdown для форматирования текста. Размещайте комментарии документации непосредственно перед элементом, который они документируют. В листинге 14-1 показаны комментарии документации для функции add_one в крейте с именем my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Здесь мы даем описание того, что делает функция add_one, начинаем раздел с заголовком Examples и затем предоставляем код, демонстрирующий использование функции add_one. Мы можем сгенерировать HTML-документацию из этого комментария документации, выполнив cargo doc. Эта команда запускает инструмент rustdoc, поставляемый с Rust, и помещает сгенерированную HTML-документацию в каталог target/doc.
Для удобства выполнение cargo doc --open соберет HTML для документации текущего крейта (а также документации для всех зависимостей вашего крейта) и откроет результат в веб-браузере. Перейдите к функции add_one, и вы увидите, как отображается текст в комментариях документации, как показано на рисунке 14-1.

Рисунок 14-1: HTML-документация для функции add_one
Часто используемые разделы
Мы использовали заголовок Markdown # Examples в листинге 14-1, чтобы создать раздел в HTML с заголовком "Examples". Вот другие разделы, которые авторы крейтов часто используют в своей документации:
- Panics: Сценарии, в которых документируемая функция может вызвать панику (panic). Вызывающие функцию, которые не хотят, чтобы их программы паниковали, должны убедиться, что они не вызывают функцию в этих ситуациях.
- Errors: Если функция возвращает
Result, описание типов ошибок, которые могут возникнуть, и условий, которые могут вызвать эти ошибки, может быть полезно для вызывающих, чтобы они могли написать код для обработки различных типов ошибок разными способами. - Safety: Если функция является
unsafe(небезопасной) для вызова (мы обсуждаем небезопасность в главе 20), должен быть раздел, объясняющий, почему функция небезопасна, и описывающий инварианты, которые функция ожидает от вызывающих сторон.
Большинству комментариев документации не нужны все эти разделы, но это хороший контрольный список, который напоминает о аспектах вашего кода, которые будут интересны пользователям.
Комментарии документации как тесты
Добавление блоков примеров кода в ваши комментарии документации может помочь продемонстрировать, как использовать вашу библиотеку, и имеет дополнительное преимущество: выполнение cargo test будет запускать примеры кода в вашей документации как тесты! Нет ничего лучше документации с примерами. Но нет ничего хуже примеров, которые не работают, потому что код изменился с момента написания документации. Если мы запустим cargo test с документацией для функции add_one из листинга 14-1, мы увидим раздел в результатах тестов, который выглядит так:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Теперь, если мы изменим либо функцию, либо пример так, что макрос assert_eq! в примере вызовет панику, и снова запустим cargo test, мы увидим, что тесты документации обнаруживают, что пример и код не синхронизированы друг с другом!
Комментарии для содержащих элементов
Стиль комментария документации //! добавляет документацию к элементу, который содержит комментарии, а не к элементам, следующим за комментариями. Мы обычно используем эти комментарии документации внутри корневого файла крейта (src/lib.rs по соглашению) или внутри модуля, чтобы документировать крейт или модуль в целом.
Например, чтобы добавить документацию, описывающую назначение крейта my_crate, который содержит функцию add_one, мы добавляем комментарии документации, начинающиеся с //!, в начало файла src/lib.rs, как показано в листинге 14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Обратите внимание, что после последней строки, начинающейся с //!, нет никакого кода. Поскольку мы начали комментарии с //! вместо ///, мы документируем элемент, содержащий этот комментарий, а не элемент, следующий за этим комментарием. В этом случае этим элементом является файл src/lib.rs, который является корнем крейта. Эти комментарии описывают весь крейт.
Когда мы запускаем cargo doc --open, эти комментарии отображаются на главной странице документации для my_crate над списком публичных элементов крейта, как показано на рисунке 14-2.
Комментарии документации внутри элементов полезны для описания крейтов и модулей, в особенности. Используйте их, чтобы объяснить общее назначение контейнера, чтобы помочь вашим пользователям понять организацию крейта.

Рисунок 14-2: Сгенерированная документация для my_crate, включая комментарий, описывающий крейт в целом
Экспорт удобного публичного API
Структура вашего публичного API является важным соображением при публикации крейта. Люди, которые используют ваш крейт, менее знакомы со структурой, чем вы, и могут испытывать трудности с поиском частей, которые они хотят использовать, если ваш крейт имеет большую иерархию модулей.
В главе 7 мы рассмотрели, как сделать элементы публичными с помощью ключевого слова pub и как поместить элементы в область видимости с помощью ключевого слова use. Однако структура, которая имеет смысл для вас во время разработки крейта, может быть не очень удобной для ваших пользователей. Вы можете организовать свои структуры в иерархии, содержащей несколько уровней, но тогда люди, которые хотят использовать тип, определенный глубоко в иерархии, могут не знать о его существовании. Их также может раздражать необходимость писать use my_crate::some_module::another_module::UsefulType; вместо use my_crate::UsefulType;.
Хорошая новость заключается в том, что если структура не удобна для использования из другой библиотеки, вам не нужно перестраивать свою внутреннюю организацию: вместо этого вы можете повторно экспортировать элементы, чтобы создать публичную структуру, отличную от вашей приватной структуры, с помощью pub use. Повторный экспорт (Re-exporting) берет публичный элемент в одном месте и делает его публичным в другом месте, как если бы он был определен в этом другом месте.
Например, допустим, мы создали библиотеку с именем art для моделирования художественных концепций. В этой библиотеке есть два модуля: модуль kinds, содержащий два перечисления PrimaryColor и SecondaryColor, и модуль utils, содержащий функцию mix, как показано в листинге 14-3.
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}На рисунке 14-3 показано, как будет выглядеть главная страница документации для этого крейта, сгенерированная cargo doc.

Рисунок 14-3: Главная страница документации для art, которая перечисляет модули kinds и utils
Обратите внимание, что типы PrimaryColor и SecondaryColor не перечислены на главной странице, как и функция mix. Мы должны нажать kinds и utils, чтобы увидеть их.
Другой крейт, который зависит от этой библиотеки, будет нуждаться в операторах use, которые помещают элементы из art в область видимости, указывая currently определенную структуру модуля. В листинге 14-4 показан пример крейта, который использует элементы PrimaryColor и mix из крейта art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Автор кода в листинге 14-4, который использует крейт art, должен был выяснить, что PrimaryColor находится в модуле kinds, а mix — в модуле utils. Структура модулей крейта art более актуальна для разработчиков, работающих над крейтом art, чем для тех, кто его использует. Внутренняя структура не содержит никакой полезной информации для кого-то, пытающегося понять, как использовать крейт art, а скорее вызывает путаницу, потому что разработчики, которые его используют, должны выяснить, где искать, и должны указывать имена модулей в операторах use.
Чтобы убрать внутреннюю организацию из публичного API, мы можем изменить код крейта art из листинга 14-3, добавив операторы pub use для повторного экспорта элементов на верхний уровень, как показано в листинге 14-5.
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}API-документация, которую cargo doc генерирует для этого крейта, теперь будет перечислять и ссылаться на повторно экспортируемые элементы на главной странице, как показано на рисунке 14-4, что облегчает поиск типов PrimaryColor и SecondaryColor и функции mix.

Рисунок 14-4: Главная страница документации для art, которая перечисляет повторно экспортированные элементы
Пользователи крейта art все еще могут видеть и использовать внутреннюю структуру из листинга 14-3, как показано в листинге 14-4, или они могут использовать более удобную структуру из листинга 14-5, как показано в листинге 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}В случаях, когда есть много вложенных модулей, повторный экспорт типов на верхний уровень с помощью pub use может существенно повлиять на опыт людей, которые используют крейт. Другое распространенное использование pub use — это повторный экспорт определений зависимости в текущем крейте, чтобы сделать определения этого крейта частью публичного API вашего крейта.
Создание полезной структуры публичного API — это больше искусство, чем наука, и вы можете итеративно находить API, который лучше всего подходит для ваших пользователей. Выбор pub use дает вам гибкость в том, как вы структурируете ваш крейт внутренне, и отделяет эту внутреннюю структуру от того, что вы представляете вашим пользователям. Посмотрите на код некоторых крейтов, которые вы установили, чтобы увидеть, отличается ли их внутренняя структура от их публичного API.
Настройка учетной записи на Crates.io
Прежде чем вы сможете опубликовать какие-либо крейты, вам нужно создать учетную запись на crates.io и получить API-токен. Для этого посетите домашнюю страницу crates.io и войдите через учетную запись GitHub. (Учетная запись GitHub в настоящее время является обязательным требованием, но сайт может поддерживать другие способы создания учетной записи в будущем.) После входа в систему посетите настройки вашей учетной записи по адресу https://crates.io/me/ и получите ваш API-ключ. Затем выполните команду cargo login и вставьте ваш API-ключ, когда будет предложено, например:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Эта команда сообщит Cargo о вашем API-токене и сохранит его локально в файле ~/.cargo/credentials.toml. Обратите внимание, что этот токен является секретным: не делитесь им с кем-либо еще. Если вы по какой-либо причине поделились им с кем-то, вы должны отозвать его и сгенерировать новый токен на crates.io.
Добавление метаданных в новый крейт
Предположим, у вас есть крейт, который вы хотите опубликовать. Перед публикацией вам нужно добавить некоторые метаданные в раздел [package] файла Cargo.toml крейта.
Вашему крейту потребуется уникальное имя. Пока вы работаете с крейтом локально, вы можете называть его как угодно. Однако имена крейтов на crates.io распределяются по принципу "кто первый пришел, того и тапки". Как только имя крейта занято, никто другой не может опубликовать крейт с таким именем. Прежде чем пытаться опубликовать крейт, поищите имя, которое вы хотите использовать. Если имя уже занято, вам нужно найти другое имя и отредактировать поле name в файле Cargo.toml в разделе [package], чтобы использовать новое имя для публикации, например:
Файл: Cargo.toml
[package]
name = "guessing_game"
Даже если вы выбрали уникальное имя, когда вы запустите cargo publish для публикации крейта на этом этапе, вы получите предупреждение, а затем ошибку:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Это приводит к ошибке, потому что вам не хватает некоторой важной информации: описание и лицензия обязательны, чтобы люди знали, что делает ваш крейт и на каких условиях они могут его использовать. В Cargo.toml добавьте описание, состоящее всего из одного или двух предложений, потому что оно будет появляться вместе с вашим крейтом в результатах поиска. Для поля license вам нужно указать значение идентификатора лицензии. На Сайте обмена данными о программных пакетах (SPDX) Фонда Линукса перечислены идентификаторы, которые вы можете использовать для этого значения. Например, чтобы указать, что вы лицензировали свой крейт с помощью лицензии MIT, добавьте идентификатор MIT:
Файл: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Если вы хотите использовать лицензию, которой нет в SPDX, вам нужно поместить текст этой лицензии в файл, включить этот файл в ваш проект, а затем использовать license-file для указания имени этого файла вместо использования ключа license.
Руководство о том, какая лицензия подходит для вашего проекта, выходит за рамки этой книги. Многие люди в сообществе Rust лицензируют свои проекты так же, как Rust, используя двойную лицензию MIT OR Apache-2.0. Эта практика демонстрирует, что вы также можете указать несколько идентификаторов лицензий, разделенных OR, чтобы иметь несколько лицензий для вашего проекта.
С уникальным именем, версией, вашим описанием и добавленной лицензией файл Cargo.toml для проекта, готового к публикации, может выглядеть так:
Файл: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
Документация Cargo описывает другие метаданные, которые вы можете указать, чтобы обеспечить возможность другим обнаруживать и использовать ваш крейт более легко.
Публикация на Crates.io
Теперь, когда вы создали учетную запись, сохранили свой API-токен, выбрали имя для своего крейта и указали необходимые метаданные, вы готовы к публикации! Публикация крейта загружает конкретную версию на crates.io для использования другими.
Будьте осторожны, потому что публикация является постоянной. Версию никогда нельзя перезаписать, и код нельзя удалить, за исключением определенных обстоятельств. Одна из основных целей Crates.io — действовать как постоянный архив кода, чтобы сборки всех проектов, зависящих от крейтов с crates.io, продолжали работать. Разрешение удаления версий сделало бы выполнение этой цели невозможным. Однако нет ограничений на количество версий крейта, которые вы можете опубликовать.
Снова выполните команду cargo publish. Теперь она должна завершиться успешно:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
Поздравляем! Теперь вы поделились своим кодом с сообществом Rust, и любой может легко добавить ваш крейт в качестве зависимости своего проекта.
Публикация новой версии существующего крейта
Когда вы внесли изменения в свой крейт и готовы выпустить новую версию, вы изменяете значение version, указанное в вашем файле Cargo.toml, и публикуете заново. Используйте правила Семантического Версионирования (Semantic Versioning), чтобы решить, какой следующий номер версии является подходящим, основываясь на типах внесенных вами изменений. Затем запустите cargo publish, чтобы загрузить новую версию.
Устаревание версий на Crates.io
Хотя вы не можете удалить предыдущие версии крейта, вы можете предотвратить добавление их в качестве новых зависимостей любыми будущими проектами. Это полезно, когда версия крейта по той или иной причине сломана. В таких ситуациях Cargo поддерживает отзыв (yanking) версии крейта.
Отзыв версии предотвращает зависимость новых проектов от этой версии, позволяя при этом всем существующим проектам, которые зависят от нее, продолжать работу. По сути, отзыв означает, что все проекты с файлом Cargo.lock не сломаются, и любые будущие сгенерированные файлы Cargo.lock не будут использовать отозванную версию.
Чтобы отозвать версию крейта, в каталоге крейта, который вы ранее опубликовали, выполните cargo yank и укажите, какую версию вы хотите отозвать. Например, если мы опубликовали крейт с именем guessing_game версии 1.0.1 и хотим его отозвать, то мы выполним следующее в каталоге проекта для guessing_game:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
Добавив --undo к команде, вы также можете отменить отзыв и разрешить проектам снова начинать зависеть от версии:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
Отзыв не удаляет никакой код. Он не может, например, удалить случайно загруженные секреты. Если это произойдет, вы должны немедленно сбросить эти секреты.
Рабочие пространства Cargo
В главе 12 мы создали пакет, который включал бинарный крейт и библиотечный крейт. По мере развития вашего проекта вы можете обнаружить, что библиотечный крейт продолжает увеличиваться, и вы хотите разделить ваш пакет дальше на несколько библиотечных крейтов. Cargo предлагает функцию под названием рабочие пространства (workspaces), которая может помочь управлять несколькими связанными пакетами, разрабатываемыми совместно.
Создание рабочего пространства
Рабочее пространство — это набор пакетов, которые используют один и тот же файл Cargo.lock и выходной каталог. Давайте создадим проект, используя рабочее пространство — мы будем использовать тривиальный код, чтобы сосредоточиться на структуре рабочего пространства. Существует несколько способов структурировать рабочее пространство, поэтому мы просто покажем один распространенный способ. У нас будет рабочее пространство, содержащее бинарный крейт и две библиотеки. Бинарный крейт, который будет предоставлять основную функциональность, будет зависеть от двух библиотек. Одна библиотека будет предоставлять функцию add_one, а другая библиотека — функцию add_two. Эти три крейта будут частью одного рабочего пространства. Мы начнем с создания нового каталога для рабочего пространства:
$ mkdir add
$ cd add
Затем в каталоге add мы создаем файл Cargo.toml, который будет настраивать все рабочее пространство. Этот файл не будет иметь раздела [package]. Вместо этого он начнется с раздела [workspace], который позволит нам добавлять участников в рабочее пространство. Мы также обязательно используем новейшую и лучшую версию алгоритма резолвера Cargo в нашем рабочем пространстве, установив значение resolver в "3":
Файл: Cargo.toml
[workspace]
resolver = "3"
Далее мы создадим бинарный крейт adder, выполнив cargo new внутри каталога add:
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
Выполнение cargo new внутри рабочего пространства также автоматически добавляет вновь созданный пакет в ключ members в определении [workspace] в Cargo.toml рабочего пространства, вот так:
[workspace]
resolver = "3"
members = ["adder"]
На этом этапе мы можем собрать рабочее пространство, выполнив cargo build. Файлы в вашем каталоге add должны выглядеть так:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Рабочее пространство имеет один каталог target на верхнем уровне, в который будут помещены скомпилированные артефакты; пакет adder не имеет своего собственного каталога target. Даже если бы мы запустили cargo build из каталога adder, скомпилированные артефакты все равно оказались бы в add/target, а не в add/adder/target. Cargo структурирует каталог target в рабочем пространстве таким образом, потому что крейты в рабочем пространстве предназначены для зависимости друг от друга. Если бы каждый крейт имел свой собственный каталог target, каждый крейт должен был бы перекомпилировать каждый из других крейтов в рабочем пространстве, чтобы поместить артефакты в свой собственный каталог target. Совместно используя один каталог target, крейты могут избежать ненужной пересборки.
Создание второго пакета в рабочем пространстве
Далее давайте создадим еще один пакет-участник в рабочем пространстве и назовем его add_one. Сгенерируем новый библиотечный крейт с именем add_one:
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
Верхнеуровневый Cargo.toml теперь будет включать путь add_one в списке members:
Файл: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Теперь ваш каталог add должен иметь эти каталоги и файлы:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
В файле add_one/src/lib.rs давайте добавим функцию add_one:
Файл: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Теперь мы можем сделать так, чтобы пакет adder с нашим бинарным крейтом зависел от пакета add_one, в котором находится наша библиотека. Сначала нам нужно добавить зависимость по пути на add_one в adder/Cargo.toml.
Файл: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo не предполагает, что крейты в рабочем пространстве будут зависеть друг от друга, поэтому нам нужно явно указать отношения зависимостей.
Далее давайте используем функцию add_one (из крейта add_one) в крейте adder. Откройте файл adder/src/main.rs и измените функцию main, чтобы вызвать функцию add_one, как в листинге 14-7.
<Листинг number="14-7" file-name="adder/src/main.rs" caption="Использование библиотечного крейта add_one из крейта adder">
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}</Листинг>
Давайте соберем рабочее пространство, выполнив cargo build в верхнеуровневом каталоге add!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Чтобы запустить бинарный крейт из каталога add, мы можем указать, какой пакет в рабочем пространстве мы хотим запустить, используя аргумент -p и имя пакета с cargo run:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Это запускает код в adder/src/main.rs, который зависит от крейта add_one.
Зависимость от внешнего пакета
Обратите внимание, что рабочее пространство имеет только один файл Cargo.lock на верхнем уровне, а не отдельный Cargo.lock в каталоге каждого крейта. Это гарантирует, что все крейты используют одну и ту же версию всех зависимостей. Если мы добавим пакет rand в файлы adder/Cargo.toml и add_one/Cargo.toml, Cargo разрешит обе эти зависимости до одной версии rand и запишет это в единственный Cargo.lock. Использование одних и тех же зависимостей всеми крейтами в рабочем пространстве означает, что крейты всегда будут совместимы друг с другом. Давайте добавим крейт rand в раздел [dependencies] в файле add_one/Cargo.toml, чтобы мы могли использовать крейт rand в крейте add_one:
Файл: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Теперь мы можем добавить use rand; в файл add_one/src/lib.rs, и сборка всего рабочего пространства путем выполнения cargo build в каталоге add загрузит и скомпилирует крейт rand. Мы получим одно предупреждение, потому что мы не ссылаемся на rand, который мы добавили в область видимости:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Верхнеуровневый Cargo.lock теперь содержит информацию о зависимости add_one от rand. Однако, даже though rand используется где-то в рабочем пространстве, мы не можем использовать его в других крейтах в рабочем пространстве, если мы не добавим rand в их файлы Cargo.toml. Например, если мы добавим use rand; в файл adder/src/main.rs для пакета adder, мы получим ошибку:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Чтобы исправить это, отредактируйте файл Cargo.toml для пакета adder и укажите, что rand также является зависимостью для него. Сборка пакета adder добавит rand в список зависимостей для adder в Cargo.lock, но дополнительные копии rand загружаться не будут. Cargo гарантирует, что каждый крейт в каждом пакете рабочего пространства, использующий пакет rand, будет использовать ту же версию, пока они указывают совместимые версии rand, экономя нам место и обеспечивая совместимость крейтов в рабочем пространстве друг с другом.
Если крейты в рабочем пространстве указывают несовместимые версии одной и той же зависимости, Cargo разрешит каждую из них, но все равно попытается разрешить как можно меньше версий.
Добавление теста в рабочее пространство
Для другого улучшения давайте добавим тест функции add_one::add_one внутри крейта add_one:
Файл: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Теперь запустите cargo test в верхнеуровневом каталоге add. Запуск cargo test в рабочем пространстве, структурированном подобным образом, запустит тесты для всех крейтов в рабочем пространстве:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Первый раздел вывода показывает, что тест it_works в крейте add_one прошел. Следующий раздел показывает, что в крейте adder не найдено тестов, а затем последний раздел показывает, что в крейте add_one не найдено тестов документации.
Мы также можем запустить тесты для одного конкретного крейта в рабочем пространстве из верхнеуровневого каталога, используя флаг -p и указав имя крейта, который мы хотим протестировать:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Этот вывод показывает, что cargo test запустил только тесты для крейта add_one и не запустил тесты крейта adder.
Если вы публикуете крейты в рабочем пространстве на crates.io, каждый крейт в рабочем пространстве должен быть опубликован отдельно. Как и cargo test, мы можем опубликовать определенный крейт в нашем рабочем пространстве, используя флаг -p и указав имя крейта, который мы хотим опубликовать.
Для дополнительной практики добавьте крейт add_two в это рабочее пространство аналогично крейту add_one!
По мере роста вашего проекта рассмотрите возможность использования рабочего пространства: оно позволяет вам работать с меньшими, более понятными компонентами, чем один большой блок кода. Кроме того, хранение крейтов в рабочем пространстве может облегчить координацию между крейтами, если они часто изменяются одновременно.
Установка бинарных файлов с помощью cargo install
Команда cargo install позволяет вам локально устанавливать и использовать бинарные крейты. Это не предназначено для замены системных пакетов; это удобный способ для Rust-разработчиков устанавливать инструменты, которые другие разместили на crates.io. Обратите внимание, что вы можете устанавливать только пакеты, которые имеют бинарные цели. Бинарная цель — это запускаемая программа, которая создается, если крейт имеет файл src/main.rs или другой файл, указанный как бинарный, в отличие от библиотечной цели, которая не является запускаемой сама по себе, но подходит для включения в другие программы. Обычно крейты содержат информацию в файле README о том, является ли крейт библиотекой, имеет бинарную цель или и то, и другое.
Все бинарные файлы, установленные с помощью cargo install, сохраняются в папке bin корневой директории установки. Если вы установили Rust с помощью rustup.rs и не имеете пользовательских конфигураций, этой директорией будет $HOME/.cargo/bin. Убедитесь, что эта директория находится в вашем $PATH, чтобы иметь возможность запускать программы, установленные с помощью cargo install.
Например, в главе 12 мы упоминали, что существует реализация инструмента grep на Rust под названием ripgrep для поиска по файлам. Чтобы установить ripgrep, мы можем выполнить следующее:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
Предпоследняя строка вывода показывает местоположение и имя установленного бинарного файла, который в случае с ripgrep называется rg. При условии, что директория установки находится в вашем $PATH, как упоминалось ранее, вы можете затем запустить rg --help и начать использовать более быстрый и "растовский" инструмент для поиска по файлам!
Расширение Cargo с помощью пользовательских команд
Cargo разработан таким образом, что вы можете расширять его новыми подкомандами без необходимости его модификации. Если бинарный файл в вашем $PATH называется cargo-что-то, вы можете запустить его как подкоманду Cargo, выполнив cargo что-то. Пользовательские команды подобного типа также отображаются при выполнении cargo --list. Возможность использовать cargo install для установки расширений и затем запускать их точно так же, как встроенные инструменты Cargo, является чрезвычайно удобным преимуществом дизайна Cargo!
Итоги
Возможность делиться кодом с помощью Cargo и crates.io является частью того, что делает экосистему Rust полезной для множества различных задач. Стандартная библиотека Rust небольшая и стабильная, но крейты легко распространять, использовать и улучшать по временной шкале, отличной от временной шкалы языка. Не стесняйтесь делиться кодом, который полезен вам, на crates.io; вполне вероятно, что он окажется полезным и для кого-то другого!
Умные указатели
Note
Указатель — это общее понятие для переменной, которая содержит адрес в памяти. Этот адрес ссылается или "указывает на" некоторые другие данные. Наиболее распространенным видом указателя в Rust является ссылка, с которой вы познакомились в Главе 4. Ссылки обозначаются символом
&и заимствуют значение, на которое они указывают. У них нет никаких особых возможностей, кроме ссылки на данные, и они не несут накладных расходов.
Умные указатели, с другой стороны, это структуры данных, которые ведут себя как указатель, но также имеют дополнительные метаданные и возможности. Концепция умных указателей не уникальна для Rust: умные указатели возникли в C++ и существуют в других языках. Rust имеет множество умных указателей, определенных в стандартной библиотеке, которые предоставляют функциональность beyond ту, что предоставляется ссылками. Чтобы исследовать общую концепцию, мы рассмотрим несколько разных примеров умных указателей, включая тип умного указателя с подсчётом ссылок. Этот указатель позволяет данным иметь нескольких владельцев, отслеживая их количество и очищая данные, когда владельцев не остаётся.
В Rust, с его концепцией владения и заимствования, есть дополнительное различие между ссылками и умными указателями: в то время как ссылки только заимствуют данные, во многих случаях умные указатели владеют данными, на которые они указывают.
Умные указатели обычно реализуются с использованием структур. В отличие от обычной структуры, умные указатели реализуют трейты Deref и Drop. Трейт Deref позволяет экземпляру структуры умного указателя вести себя как ссылка, чтобы вы могли писать код, работающий как со ссылками, так и с умными указателями. Трейт Drop позволяет вам настроить код, который выполняется, когда экземпляр умного указателя выходит из области видимости. В этой главе мы обсудим оба этих трейта и продемонстрируем, почему они важны для умных указателей.
Учитывая, что шаблон умных указателей — это общий шаблон проектирования, часто используемый в Rust, эта глава не будет охватывать все существующие умные указатели. Многие библиотеки имеют свои собственные умные указатели, и вы даже можете написать свои собственные. Мы рассмотрим наиболее распространенные умные указатели в стандартной библиотеке:
Box<T>для выделения значений в кучеRc<T>, тип с подсчётом ссылок, который обеспечивает множественное владениеRef<T>иRefMut<T>, доступные черезRefCell<T>, тип, который обеспечивает соблюдение правил заимствования во время выполнения вместо времени компиляции
Кроме того, мы рассмотрим шаблон внутренней изменяемости (interior mutability), где неизменяемый тип предоставляет API для изменения внутреннего значения. Мы также обсудим циклы ссылок: как они могут приводить к утечкам памяти и как их предотвратить.
Давайте начнём!
Использование Box<T> для указания на данные в куче
Наиболее простым умным указателем является box (бокс), тип которого записывается как Box<T>. Боксы позволяют хранить данные в куче, а не в стеке. То, что остаётся в стеке — это указатель на данные в куче. Обратитесь к Главе 4, чтобы повторить разницу между стеком и кучей.
Боксы не несут накладных расходов на производительность, кроме хранения своих данных в куче вместо стека. Но у них также нет много дополнительных возможностей. Вы будете использовать их чаще всего в следующих ситуациях:
- Когда у вас есть тип, размер которого не может быть известен во время компиляции, и вы хотите использовать значение этого типа в контексте, который требует точный размер
- Когда у вас есть большой объём данных, и вы хотите передать владение, но обеспечить, чтобы данные не копировались при этом
- Когда вы хотите владеть значением, и вас волнует только то, что это тип, реализующий определённый трейт, а не то, что он относится к конкретному типу
Мы продемонстрируем первую ситуацию в разделе «Включение рекурсивных типов с помощью боксов». Во втором случае передача владения большим объёмом данных может занять много времени, потому что данные копируются в стеке. Чтобы повысить производительность в этой ситуации, мы можем хранить большой объём данных в куче в боксе. Тогда только небольшой объём данных указателя копируется в стеке, в то время как данные, на которые он ссылается, остаются в одном месте в куче. Третий случай известен как объект трейта (trait object), и разделу «Использование объектов трейтов для абстракции над общим поведением» в Главе 18 посвящена эта тема. Так что то, что вы узнаете здесь, вы примените снова в том разделе!
Хранение данных в куче
Прежде чем мы обсудим случай использования Box<T> для хранения в куче, мы рассмотрим синтаксис и то, как взаимодействовать со значениями, хранящимися внутри Box<T>.
Listing 15-1 показывает, как использовать бокс для хранения значения i32 в куче.
fn main() { let b = Box::new(5); println!("b = {b}"); }
Мы определяем переменную b со значением Box, который указывает на значение 5, размещённое в куче. Эта программа напечатает b = 5; в этом случае мы можем получить доступ к данным в боксе аналогично тому, как если бы эти данные были в стеке. Так же, как и любое владеемое значение, когда бокс выходит из области видимости, как b делает это в конце main, он будет освобождён. Освобождение происходит как для бокса (хранящегося в стеке), так и для данных, на которые он указывает (хранящихся в куче).
Помещение единственного значения в кучу не очень полезно, поэтому вы не будете часто использовать боксы сами по себе таким образом. Наличие значений, таких как одиночный i32, в стеке, где они хранятся по умолчанию, более уместно в большинстве ситуаций. Давайте рассмотрим случай, когда боксы позволяют нам определять типы, которые мы не смогли бы определить, если бы у нас не было боксов.
Включение рекурсивных типов с помощью боксов
Значение рекурсивного типа может иметь другое значение того же типа как часть себя. Рекурсивные типы представляют проблему, потому что Rust необходимо знать во время компиляции, сколько места занимает тип. Однако вложение значений рекурсивных типов теоретически может продолжаться бесконечно, поэтому Rust не может знать, сколько места нужно значению. Поскольку боксы имеют известный размер, мы можем включить рекурсивные типы, вставив бокс в определение рекурсивного типа.
В качестве примера рекурсивного типа давайте исследуем cons list (список-конструктор). Это тип данных, часто встречающийся в функциональных языках программирования. Тип cons list, который мы определим, прост, за исключением рекурсии; поэтому концепции в примере, с которым мы будем работать, будут полезны всякий раз, когда вы столкнётесь с более сложными ситуациями, связанными с рекурсивными типами.
Понимание Cons List
Cons list — это структура данных, которая пришла из языка программирования Lisp и его диалектов, состоит из вложенных пар и является версией связного списка в Lisp. Его название происходит от функции cons (сокращение от construct function — функция конструктора) в Lisp, которая создаёт новую пару из двух своих аргументов. Вызывая cons для пары, состоящей из значения и другой пары, мы можем строить cons lists, состоящие из рекурсивных пар.
Например, вот псевдокод, представляющий cons list, содержащий список 1, 2, 3, где каждая пара заключена в круглые скобки:
(1, (2, (3, Nil)))
Каждый элемент в cons list содержит два элемента: значение текущего элемента и значение следующего элемента. Последний элемент в списке содержит только значение с именем Nil без следующего элемента. Cons list создаётся путём рекурсивного вызова функции cons. Каноническое имя для обозначения базового случая рекурсии — Nil. Обратите внимание, что это не то же самое, что концепция «null» или «nil», обсуждавшаяся в Главе 6, которая представляет недопустимое или отсутствующее значение.
Cons list не является часто используемой структурой данных в Rust. В большинстве случаев, когда у вас есть список элементов в Rust, Vec<T> — лучший выбор для использования. Другие, более сложные рекурсивные типы данных полезны в различных ситуациях, но начав с cons list в этой главе, мы можем исследовать, как боксы позволяют нам определить рекурсивный тип данных без лишних сложностей.
Листинг 15-2 содержит определение перечисления для cons list. Обратите внимание, что этот код пока не скомпилируется, потому что тип List не имеет известного размера, что мы и продемонстрируем.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}Примечание: Мы реализуем cons list, который хранит только значения
i32для целей этого примера. Мы могли бы реализовать его, используя обобщённые типы, как мы обсуждали в Главе 10, чтобы определить тип cons list, который может хранить значения любого типа.
Использование типа List для хранения списка 1, 2, 3 будет выглядеть как код в Листинге 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}Первое значение Cons содержит 1 и другое значение List. Это значение List — это другое значение Cons, которое содержит 2 и другое значение List. Это значение List — это ещё одно значение Cons, которое содержит 3 и значение List, которое, наконец, является Nil — нерекурсивным вариантом, который сигнализирует о конце списка.
Если мы попытаемся скомпилировать код из Листинга 15-3, мы получим ошибку, показанную в Листинге 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
Ошибка показывает, что этот тип «имеет бесконечный размер». Причина в том, что мы определили List с вариантом, который является рекурсивным: он напрямую содержит другое значение самого себя. В результате Rust не может выяснить, сколько места ему нужно для хранения значения List. Давайте разберём, почему мы получаем эту ошибку. Сначала мы посмотрим, как Rust решает, сколько места ему нужно для хранения значения нерекурсивного типа.
Вычисление размера нерекурсивного типа
Вспомните перечисление Message, которое мы определили в Листинге 6-2, когда обсуждали определения перечислений в Главе 6:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Чтобы определить, сколько места выделить для значения Message, Rust просматривает каждый из вариантов, чтобы увидеть, какой вариант требует больше всего места. Rust видит, что Message::Quit не требует никакого места, Message::Move требует достаточно места для хранения двух значений i32 и так далее. Поскольку будет использоваться только один вариант, максимальное пространство, которое потребуется значению Message, — это пространство, необходимое для хранения наибольшего из его вариантов.
Сравните это с тем, что происходит, когда Rust пытается определить, сколько места нужно рекурсивному типу, такому как перечисление List из Листинга 15-2. Компилятор начинает с просмотра варианта Cons, который содержит значение типа i32 и значение типа List. Следовательно, Cons требует объёма пространства, равного размеру i32 плюс размер List. Чтобы выяснить, сколько памяти нужно типу List, компилятор смотрит на варианты, начиная с варианта Cons. Вариант Cons содержит значение типа i32 и значение типа List, и этот процесс продолжается бесконечно, как показано на Рисунке 15-1.

Рисунок 15-1: Бесконечный List, состоящий из бесконечных вариантов Cons
Получение рекурсивного типа с известным размером
Поскольку Rust не может выяснить, сколько места выделить для рекурсивно определённых типов, компилятор выдаёт ошибку с этим полезным предложением:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
В этом предложении indirection (косвенность) означает, что вместо хранения значения напрямую мы должны изменить структуру данных, чтобы хранить значение косвенно, сохраняя указатель на значение.
Поскольку Box<T> является указателем, Rust всегда знает, сколько места нужно Box<T>: размер указателя не меняется в зависимости от объёма данных, на которые он указывает. Это означает, что мы можем поместить Box<T> внутрь варианта Cons вместо другого значения List напрямую. Box<T> будет указывать на следующее значение List, которое будет в куче, а не внутри варианта Cons. Концептуально у нас всё ещё есть список, созданный списками, содержащими другие списки, но эта реализация теперь больше похожа на размещение элементов рядом друг с другом, а не внутри друг друга.
Мы можем изменить определение перечисления List в Листинге 15-2 и использование List в Листинге 15-3 на код в Листинге 15-5, который скомпилируется.
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Вариант Cons требует размера i32 плюс пространство для хранения данных указателя бокса. Вариант Nil не хранит значений, поэтому ему нужно меньше места в стеке, чем варианту Cons. Теперь мы знаем, что любое значение List займёт размер i32 плюс размер данных указателя бокса. Используя бокс, мы разорвали бесконечную рекурсивную цепь, поэтому компилятор может вычислить размер, необходимый для хранения значения List. Рисунок 15-2 показывает, как теперь выглядит вариант Cons.

Рисунок 15-2: List, который не бесконечно sized, потому что Cons содержит Box
Боксы предоставляют только косвенность и выделение в куче; у них нет других специальных возможностей, подобных тем, что мы увидим у других типов умных указателей. Они также не несут накладных расходов на производительность, которые влекут эти специальные возможности, поэтому они могут быть полезны в таких случаях, как cons list, где косвенность — это единственная функция, которая нам нужна. Мы рассмотрим больше случаев использования боксов в Главе 18.
Тип Box<T> является умным указателем, потому что он реализует трейт Deref, который позволяет обращаться со значениями Box<T> как со ссылками. Когда значение Box<T> выходит из области видимости, данные в куче, на которые указывает бокс, также очищаются благодаря реализации трейта Drop. Эти два трейта будут ещё более важны для функциональности, предоставляемой другими типами умных указателей, которые мы обсудим в оставшейся части этой главы. Давайте исследуем эти два трейта более подробно.
Deref
Обращение с умными указателями как с обычными ссылками
Реализация трейта Deref позволяет вам настроить поведение оператора разыменования * (не путать с оператором умножения или glob). Реализуя Deref таким образом, что с умным указателем можно обращаться как с обычной ссылкой, вы можете писать код, который работает со ссылками, и использовать этот код также с умными указателями.
Давайте сначала посмотрим, как оператор разыменования работает с обычными ссылками. Затем мы попытаемся определить пользовательский тип, который ведёт себя как Box<T>, и посмотрим, почему оператор разыменования не работает как ссылка на нашем newly определённом типе. Мы исследуем, как реализация трейта Deref делает возможным для умных указателей работать способами, similar ссылкам. Затем мы посмотрим на функцию приведения разыменования (deref coercion) в Rust и как она позволяет нам работать как со ссылками, так и с умными указателями.
Следование по ссылке к значению
Обычная ссылка — это тип указателя, и один из способов думать об указателе — как о стрелке, указывающей на значение, хранящееся где-то ещё. В Листинге 15-6 мы создаём ссылку на значение i32, а затем используем оператор разыменования, чтобы следовать по ссылке к значению.
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
Переменная x содержит значение i32, равное 5. Мы устанавливаем y равной ссылке на x. Мы можем утверждать, что x равно 5. Однако, если мы хотим сделать утверждение о значении в y, мы должны использовать *y, чтобы следовать по ссылке к значению, на которое она указывает (следовательно, разыменовать), чтобы компилятор мог сравнить фактическое значение. Как только мы разыменуем y, мы получим доступ к целочисленному значению, на которое указывает y, которое мы можем сравнить с 5.
Если бы мы попытались написать assert_eq!(5, y); вместо этого, мы получили бы ошибку компиляции:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Сравнение числа и ссылки на число не allowed, потому что они different типы. Мы должны использовать оператор разыменования, чтобы следовать по ссылке к значению, на которое она указывает.
Использование Box<T> как ссылки
Мы можем переписать код из Листинга 15-6, чтобы использовать Box<T> вместо ссылки; оператор разыменования, использованный на Box<T> в Листинге 15-7, функционирует так же, как оператор разыменования, использованный на ссылке в Листинге 15-6.
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Основное различие между Листингом 15-7 и Листингом 15-6 заключается в том, что здесь мы устанавливаем y как экземпляр бокса, указывающего на скопированное значение x, а не как ссылку, указывающую на значение x. В последнем утверждении мы можем использовать оператор разыменования, чтобы следовать по указателю бокса так же, как мы делали, когда y была ссылкой. Далее мы исследуем, что особенного в Box<T>, что позволяет нам использовать оператор разыменования, определив наш собственный тип бокса.
Определение нашего собственного умного указателя
Давайте создадим тип-обёртку, similar типу Box<T>, предоставляемому стандартной библиотекой, чтобы испытать, как типы умных указателей ведут себя иначе, чем ссылки, по умолчанию. Затем мы посмотрим, как добавить возможность использовать оператор разыменования.
Примечание: Есть одно большое различие между типом
MyBox<T>, который мы собираемся построить, и настоящимBox<T>: наша версия не будет хранить свои данные в куче. Мы сосредотачиваем этот пример наDeref, поэтому то, где данные фактически хранятся, менее важно, чем pointer-like поведение.
Тип Box<T> в конечном счёте определён как кортежная структура с одним элементом, поэтому Листинг 15-8 определяет тип MyBox<T> таким же образом. Мы также определим функцию new, чтобы соответствовать функции new, определённой на Box<T>.
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() {}
Мы определяем структуру с именем MyBox и объявляем обобщённый параметр T, потому что хотим, чтобы наш тип хранил значения любого типа. Тип MyBox является кортежной структурой с одним элементом типа T. Функция MyBox::new принимает один параметр типа T и возвращает экземпляр MyBox, который содержит переданное значение.
Давайте попробуем добавить функцию main из Листинга 15-7 в Листинг 15-8 и изменить её, чтобы использовать определённый нами тип MyBox<T> вместо Box<T>. Код в Листинге 15-9 не скомпилируется, потому что Rust не знает, как разыменовать MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Вот результирующая ошибка компиляции:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Наш тип MyBox<T> не может быть разыменован, потому что мы не реализовали эту возможность для нашего типа. Чтобы включить разыменование с помощью оператора *, мы реализуем трейт Deref.
Реализация трейта Deref
Как обсуждалось в разделе «Реализация трейта на типе» в Главе 10, чтобы реализовать трейт, нам нужно предоставить реализации для требуемых методов трейта. Трейт Deref, предоставляемый стандартной библиотекой, требует от нас реализовать один метод с именем deref, который заимствует self и возвращает ссылку на внутренние данные. Листинг 15-10 содержит реализацию Deref для добавления к определению MyBox<T>.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Синтаксис type Target = T; определяет ассоциированный тип для использования трейтом Deref. Ассоциированные типы — это slightly different способ объявления обобщённого параметра, но вам не нужно беспокоиться о них сейчас; мы рассмотрим их более подробно в Главе 20.
Мы заполняем тело метода deref значением &self.0, чтобы deref возвращал ссылку на значение, к которому мы хотим получить доступ с помощью оператора *; вспомните из раздела «Создание разных типов с помощью кортежных структур» в Главе 5, что .0 обращается к первому значению в кортежной структуре. Функция main из Листинга 15-9, которая вызывает * для значения MyBox<T>, теперь компилируется, и утверждения проходят!
Без трейта Deref компилятор может разыменовывать только & ссылки. Метод deref даёт компилятору возможность взять значение любого типа, который реализует Deref, и вызвать метод deref, чтобы получить ссылку, которую он знает, как разыменовать.
Когда мы ввели *y в Листинге 15-9, за кулисами Rust фактически выполнил этот код:
*(y.deref())Rust заменяет оператор * вызовом метода deref, а затем простым разыменованием, чтобы нам не приходилось думать о том, нужно ли нам вызывать метод deref. Эта функция Rust позволяет нам писать код, который функционирует идентично, независимо от того, имеем ли мы обычную ссылку или тип, реализующий Deref.
Причина, по которой метод deref возвращает ссылку на значение, и причина, по которой простое разыменование за скобками в *(y.deref()) всё ещё необходимо, связана с системой владения. Если бы метод deref возвращал значение directly вместо ссылки на значение, значение было бы перемещено из self. Мы не хотим забирать владение внутренним значением внутри MyBox<T> в этом случае или в большинстве случаев, когда мы используем оператор разыменования.
Обратите внимание, что оператор * заменяется вызовом метода deref, а затем вызовом оператора * только один раз, каждый раз, когда мы используем * в нашем коде. Поскольку замена оператора * не повторяется бесконечно, мы получаем данные типа i32, которые соответствуют 5 в assert_eq! в Листинге 15-9.
Использование приведения разыменования в функциях и методах
Приведение разыменования (Deref coercion) преобразует ссылку на тип, который реализует трейт Deref, в ссылку на другой тип. Например, приведение разыменования может преобразовать &String в &str, потому что String реализует трейт Deref таким образом, что возвращает &str. Приведение разыменования — это удобство, которое Rust выполняет для аргументов функций и методов, и оно работает только для типов, которые реализуют трейт Deref. Это происходит automatically, когда мы передаём ссылку на значение определённого типа в качестве аргумента функции или метода, который не соответствует типу параметра в определении функции или метода. Последовательность вызовов метода deref преобразует предоставленный нами тип в тип, необходимый параметру.
Приведение разыменования было добавлено в Rust, чтобы программистам, пишущим вызовы функций и методов, не нужно было добавлять столько явных ссылок и разыменований с помощью & и *. Функция приведения разыменования также позволяет нам писать больше кода, который может работать как для ссылок, так и для умных указателей.
Чтобы увидеть приведение разыменования в действии, давайте используем тип MyBox<T>, который мы определили в Листинге 15-8, а также реализацию Deref, которую мы добавили в Листинге 15-10. Листинг 15-11 показывает определение функции, которая имеет параметр среза строки.
fn hello(name: &str) { println!("Hello, {name}!"); } fn main() {}
Мы можем вызвать функцию hello со срезом строки в качестве аргумента, например, hello("Rust");. Приведение разыменования делает возможным вызов hello со ссылкой на значение типа MyBox<String>, как показано в Листинге 15-12.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&m); }
Здесь мы вызываем функцию hello с аргументом &m, который является ссылкой на значение MyBox<String>. Поскольку мы реализовали трейт Deref для MyBox<T> в Листинге 15-10, Rust может превратить &MyBox<String> в &String, вызвав deref. Стандартная библиотека предоставляет реализацию Deref для String, которая возвращает срез строки, и это есть в документации API для Deref. Rust снова вызывает deref, чтобы превратить &String в &str, что соответствует определению функции hello.
Если бы Rust не реализовал приведение разыменования, нам пришлось бы написать код в Листинге 15-13 вместо кода в Листинге 15-12, чтобы вызвать hello со значением типа &MyBox<String>.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&(*m)[..]); }
(*m) разыменовывает MyBox<String> в String. Затем & и [..] берут срез строки из String, который равен всей строке, чтобы соответствовать сигнатуре hello. Этот код без приведений разыменования сложнее читать, писать и понимать со всеми этими символами. Приведение разыменования позволяет Rust обрабатывать эти преобразования для нас automatically.
Когда трейт Deref определён для involved типов, Rust будет анализировать типы и использовать Deref::deref столько раз, сколько необходимо, чтобы получить ссылку, соответствующую типу параметра. Количество раз, которое Deref::deref нужно вставить, разрешается во время компиляции, поэтому нет штрафа за производительность во время выполнения за использование приведения разыменования!
Обработка приведения разыменования с изменяемыми ссылками
Подобно тому, как вы используете трейт Deref для переопределения оператора * на неизменяемых ссылках, вы можете использовать трейт DerefMut для переопределения оператора * на изменяемых ссылках.
Rust выполняет приведение разыменования, когда находит типы и реализации трейтов в трёх случаях:
- Из
&Tв&U, когдаT: Deref<Target=U> - Из
&mut Tв&mut U, когдаT: DerefMut<Target=U> - Из
&mut Tв&U, когдаT: Deref<Target=U>
Первые два случая одинаковы, за исключением того, что второй реализует изменяемость. Первый случай утверждает, что если у вас есть &T, и T реализует Deref для некоторого типа U, вы можете transparently получить &U. Второй случай утверждает, что то же самое приведение разыменования происходит для изменяемых ссылок.
Третий случай более сложный: Rust также будет приводить изменяемую ссылку к неизменяемой. Но обратное не возможно: неизменяемые ссылки никогда не будут приводиться к изменяемым ссылкам. Из-за правил заимствования, если у вас есть изменяемая ссылка, эта изменяемая ссылка должна быть единственной ссылкой на эти данные (иначе программа не скомпилируется). Преобразование одной изменяемой ссылки в одну неизменяемую ссылку никогда не нарушит правила заимствования. Преобразование неизменяемой ссылки в изменяемую потребовало бы, чтобы initial неизменяемая ссылка была единственной неизменяемой ссылкой на эти данные, но правила заимствования не гарантируют этого. Следовательно, Rust не может сделать предположение, что преобразование неизменяемой ссылки в изменяемую возможно.
Выполнение кода при очистке с помощью трейта Drop
Вторым трейтом, важным для шаблона умных указателей, является Drop, который позволяет вам настраивать то, что происходит, когда значение вот-вот выйдет из области видимости. Вы можете предоставить реализацию трейта Drop для любого типа, и этот код может использоваться для освобождения ресурсов, таких как файлы или сетевые соединения.
Мы представляем Drop в контексте умных указателей, потому что функциональность трейта Drop почти всегда используется при реализации умного указателя. Например, когда Box<T> удаляется, он освобождает пространство в куче, на которое указывает бокс.
В некоторых языках для некоторых типов программист должен вызывать код для освобождения памяти или ресурсов каждый раз, когда он заканчивает использование экземпляра этих типов. Примеры включают файловые дескрипторы, сокеты и блокировки. Если программист забудет, система может перегрузиться и аварийно завершиться. В Rust вы можете указать, что определённый код должен выполняться всякий раз, когда значение выходит из области видимости, и компилятор вставит этот код автоматически. В результате вам не нужно быть осторожным с размещением кода очистки везде в программе, где завершается использование экземпляра определённого типа — вы всё равно не будете течь ресурсами!
Вы указываете код для выполнения при выходе значения из области видимости, реализуя трейт Drop. Трейт Drop требует, чтобы вы реализовали один метод с именем drop, который принимает изменяемую ссылку на self. Чтобы увидеть, когда Rust вызывает drop, давайте пока реализуем drop с операторами println!.
Листинг 15-14 показывает структуру CustomSmartPointer, чья единственная пользовательская функциональность заключается в том, что она будет печатать Dropping CustomSmartPointer!, когда экземпляр выходит из области видимости, чтобы показать, когда Rust выполняет метод drop.
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("my stuff"), }; let d = CustomSmartPointer { data: String::from("other stuff"), }; println!("CustomSmartPointers created"); }
Трейт Drop включён в прелюдию (prelude), поэтому нам не нужно вносить его в область видимости. Мы реализуем трейт Drop для CustomSmartPointer и предоставляем реализацию метода drop, которая вызывает println!. Тело метода drop — это место, куда вы поместили бы любую логику, которую хотите выполнить, когда экземпляр вашего типа выходит из области видимости. Мы печатаем здесь некоторый текст, чтобы визуально продемонстрировать, когда Rust вызовет drop.
В main мы создаём два экземпляра CustomSmartPointer, а затем печатаем CustomSmartPointers created. В конце main наши экземпляры CustomSmartPointer выйдут из области видимости, и Rust вызовет код, который мы поместили в метод drop, напечатав наше финальное сообщение. Обратите внимание, что нам не нужно было явно вызывать метод drop.
Когда мы запустим эту программу, мы увидим следующий вывод:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust автоматически вызвал drop для нас, когда наши экземпляры вышли из области видимости, вызывая указанный нами код. Переменные удаляются в обратном порядке их создания, поэтому d был удалён до c. Цель этого примера — дать вам визуальное руководство по работе метода drop; обычно вы указывали бы код очистки, который ваш тип должен выполнить, а не сообщение для печати.
К сожалению, отключить автоматическую функциональность drop непросто. Отключение drop обычно не требуется; вся суть трейта Drop в том, что он обрабатывается автоматически. Однако иногда вы можете захотеть очистить значение раньше времени. Один пример — при использовании умных указателей, управляющих блокировками: вы можете захотеть принудительно вызвать метод drop, который освобождает блокировку, чтобы другой код в той же области видимости мог получить блокировку. Rust не позволяет вам вручную вызывать метод drop трейта Drop; вместо этого, если вы хотите принудительно удалить значение до конца его области видимости, вы должны вызвать функцию std::mem::drop, предоставляемую стандартной библиотекой.
Попытка вручную вызвать метод drop трейта Drop путём изменения функции main из Листинга 15-14 не сработает, как показано в Листинге 15-15.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}Когда мы попытаемся скомпилировать этот код, мы получим эту ошибку:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Это сообщение об ошибке гласит, что нам не разрешено явно вызывать drop. В сообщении об ошибке используется термин деструктор (destructor), который является общим программистским термином для функции, которая очищает экземпляр. Деструктор аналогичен конструктору, который создаёт экземпляр. Функция drop в Rust — это один конкретный деструктор.
Rust не позволяет нам явно вызывать drop, потому что Rust всё равно автоматически вызовет drop для значения в конце main. Это вызвало бы ошибку двойного освобождения (double free error), потому что Rust пытался бы очистить одно и то же значение дважды.
Мы не можем отключить автоматическую вставку drop, когда значение выходит из области видимости, и мы не можем явно вызвать метод drop. Поэтому, если нам нужно принудительно очистить значение раньше времени, мы используем функцию std::mem::drop.
Функция std::mem::drop отличается от метода drop в трейте Drop. Мы вызываем её, передавая в качестве аргумента значение, которое хотим принудительно удалить. Функция находится в прелюдии, поэтому мы можем изменить main в Листинге 15-15, чтобы вызвать функцию drop, как показано в Листинге 15-16.
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created"); drop(c); println!("CustomSmartPointer dropped before the end of main"); }
Запуск этого кода напечатает следующее:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Текст Dropping CustomSmartPointer with data `some data`! печатается между текстом CustomSmartPointer created и CustomSmartPointer dropped before the end of main, показывая, что код метода drop вызывается для удаления c в этот момент.
Вы можете использовать код, указанный в реализации трейта Drop, многими способами, чтобы сделать очистку удобной и безопасной: например, вы могли бы использовать его для создания собственного аллокатора памяти! С трейтом Drop и системой владения Rust вам не нужно помнить об очистке, потому что Rust делает это автоматически.
Вам также не нужно беспокоиться о проблемах, возникающих из-за случайной очистки значений, всё ещё используемых: система владения, которая гарантирует, что ссылки всегда действительны, также обеспечивает, чтобы drop вызывался только один раз, когда значение больше не используется.
Теперь, когда мы изучили Box<T> и некоторые характеристики умных указателей, давайте посмотрим на несколько других умных указателей, определённых в стандартной библиотеке.
Rc<T> — умный указатель с подсчётом ссылок
В большинстве случаев владение понятно: вы точно знаете, какая переменная владеет данным значением. Однако бывают случаи, когда одно значение может иметь нескольких владельцев. Например, в структурах данных графа несколько рёбер могут указывать на один и тот же узел, и этот узел концептуально принадлежит всем рёбрам, которые на него указывают. Узел не должен очищаться, пока на него не останется указывающих рёбер и, следовательно, не останется владельцев.
Вам нужно явно включить множественное владение, используя тип Rust Rc<T>, что является сокращением от reference counting (подсчёт ссылок). Тип Rc<T> отслеживает количество ссылок на значение, чтобы определить, используется ли значение ещё. Если ссылок на значение ноль, значение может быть очищено без того, чтобы какие-либо ссылки стали недействительными.
Представьте Rc<T> как телевизор в гостиной. Когда один человек входит, чтобы посмотреть телевизор, он включает его. Другие могут зайти в комнату и смотреть телевизор. Когда последний человек выходит из комнаты, он выключает телевизор, потому что он больше не используется. Если кто-то выключит телевизор, пока другие ещё смотрят его, среди оставшихся зрителей поднимется возмущение!
Мы используем тип Rc<T>, когда хотим разместить некоторые данные в куче для чтения несколькими частями нашей программы и не можем определить во время компиляции, какая часть закончит использование данных последней. Если бы мы знали, какая часть закончит последней, мы могли бы просто сделать эту часть владельцем данных, и обычные правила владения, применяемые во время компиляции, вступили бы в силу.
Обратите внимание, что Rc<T> предназначен только для использования в однопоточных сценариях. Когда мы обсудим конкурентность в Главе 16, мы рассмотрим, как делать подсчёт ссылок в многопоточных программах.
Разделение данных
Давайте вернёмся к нашему примеру с cons list из Листинга 15-5. Напомним, что мы определили его с помощью Box<T>. На этот раз мы создадим два списка, которые оба разделяют владение третьим списком. Концептуально это выглядит подобно Рисунку 15-3.

Рисунок 15-3: Два списка, b и c, разделяющие владение третьим списком, a
Мы создадим список a, содержащий 5, а затем 10. Затем мы создадим ещё два списка: b, который начинается с 3, и c, который начинается с 4. Затем оба списка b и c продолжат первый список a, содержащий 5 и 10. Другими словами, оба списка будут разделять первый список, содержащий 5 и 10.
Попытка реализовать этот сценарий с использованием нашего определения List с Box<T> не сработает, как показано в Листинге 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Когда мы компилируем этот код, мы получаем эту ошибку:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Варианты Cons владеют данными, которые они содержат, поэтому, когда мы создаём список b, a перемещается в b, и b владеет a. Затем, когда мы пытаемся использовать a снова при создании c, это не разрешено, потому что a был перемещён.
Мы могли бы изменить определение Cons, чтобы оно содержало ссылки вместо этого, но тогда нам пришлось бы указывать параметры времени жизни. Указывая параметры времени жизни, мы указывали бы, что каждый элемент в списке будет жить по крайней мере так же долго, как весь список. Это так для элементов и списков в Листинге 15-17, но не в каждом сценарии.
Вместо этого мы изменим наше определение List, чтобы использовать Rc<T> вместо Box<T>, как показано в Листинге 15-18. Каждый вариант Cons теперь будет содержать значение и Rc<T>, указывающий на List. Когда мы создаём b, вместо того чтобы забирать владение a, мы клонируем Rc<List>, который удерживает a, тем самым увеличивая количество ссылок с одного до двух и позволяя a и b разделять владение данными в этом Rc<List>. Мы также клонируем a при создании c, увеличивая количество ссылок с двух до трёх. Каждый раз, когда мы вызываем Rc::clone, счётчик ссылок на данные внутри Rc<List> будет увеличиваться, и данные не будут очищены, пока на них не останется нуль ссылок.
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Нам нужно добавить оператор use, чтобы внести Rc<T> в область видимости, потому что он не в прелюдии. В main мы создаём список, содержащий 5 и 10, и сохраняем его в новом Rc<List> в a. Затем, когда мы создаём b и c, мы вызываем функцию Rc::clone и передаём ссылку на Rc<List> в a в качестве аргумента.
Мы могли бы вызвать a.clone() вместо Rc::clone(&a), но в Rust принято использовать Rc::clone в этом случае. Реализация Rc::clone не делает глубокую копию всех данных, как это делают реализации clone для большинства типов. Вызов Rc::clone только увеличивает счётчик ссылок, что не занимает много времени. Глубокие копии данных могут занимать много времени. Используя Rc::clone для подсчёта ссылок, мы можем визуально отличать глубокие копии клонов от видов клонов, которые увеличивают счётчик ссылок. При поиске проблем с производительностью в коде нам нужно рассматривать только глубокие копии клонов и можем игнорировать вызовы Rc::clone.
Клонирование для увеличения счётчика ссылок
Давайте изменим наш рабочий пример в Листинге 15-18, чтобы мы могли видеть, как меняется счётчик ссылок при создании и удалении ссылок на Rc<List> в a.
В Листинге 15-19 мы изменим main так, чтобы вокруг списка c была внутренняя область видимости; тогда мы сможем увидеть, как меняется счётчик ссылок, когда c выходит из области видимости.
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; // --snip-- fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
В каждой точке программы, где счётчик ссылок изменяется, мы выводим счётчик ссылок, который мы получаем, вызывая функцию Rc::strong_count. Эта функция названа strong_count, а не count, потому что тип Rc<T> также имеет weak_count; мы увидим, для чего используется weak_count, в разделе «Предотвращение циклов ссылок с помощью Weak<T>».
Этот код выводит следующее:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Мы видим, что Rc<List> в a имеет начальный счётчик ссылок 1; затем каждый раз, когда мы вызываем clone, счётчик увеличивается на 1. Когда c выходит из области видимости, счётчик уменьшается на 1. Нам не нужно вызывать функцию для уменьшения счётчика ссылок, как нам нужно вызывать Rc::clone для увеличения счётчика ссылок: реализация трейта Drop уменьшает счётчик ссылок автоматически, когда значение Rc<T> выходит из области видимости.
Что мы не видим в этом примере, так это то, что когда b, а затем a выходят из области видимости в конце main, счётчик становится 0, и Rc<List> полностью очищается. Использование Rc<T> позволяет одному значению иметь нескольких владельцев, и счётчик гарантирует, что значение остаётся действительным, пока любой из владельцев всё ещё существует.
Через неизменяемые ссылки Rc<T> позволяет вам делиться данными между несколькими частями вашей программы только для чтения. Если бы Rc<T> позволял вам также иметь несколько изменяемых ссылок, вы могли бы нарушить одно из правил заимствования, обсуждавшихся в Главе 4: несколько изменяемых заимствований одного и того же места могут вызывать гонки данных и несогласованность. Но возможность изменять данные очень полезна! В следующем разделе мы обсудим шаблон внутренней изменяемости и тип RefCell<T>, который вы можете использовать вместе с Rc<T>, чтобы работать с этим ограничением неизменяемости.
RefCell<T> и шаблон внутренней изменяемости
Внутренняя изменяемость (Interior mutability) — это шаблон проектирования в Rust, который позволяет вам изменять данные, даже когда существуют неизменяемые ссылки на эти данные; обычно это действие запрещено правилами заимствования. Чтобы изменять данные, шаблон использует unsafe код внутри структуры данных, чтобы обойти обычные правила Rust, управляющие изменением и заимствованием. Небезопасный код указывает компилятору, что мы проверяем правила вручную, вместо того чтобы полагаться на компилятор для их проверки; мы обсудим небезопасный код более подробно в Главе 20.
Мы можем использовать типы, которые используют шаблон внутренней изменяемости, только когда можем гарантировать, что правила заимствования будут соблюдаться во время выполнения, даже though компилятор не может этого гарантировать. Задействованный unsafe код затем оборачивается в безопасный API, и внешний тип остаётся неизменяемым.
Давайте исследуем эту концепцию, рассмотрев тип RefCell<T>, который следует шаблону внутренней изменяемости.
Обеспечение правил заимствования во время выполнения
В отличие от Rc<T>, тип RefCell<T> представляет единоличное владение данными, которые он содержит. Так что же отличает RefCell<T> от типа вроде Box<T>? Вспомните правила заимствования, которые вы изучили в Главе 4:
- В любой given момент времени вы можете иметь либо одну изменяемую ссылку, либо любое количество неизменяемых ссылок (но не both).
- Ссылки должны always быть действительными.
Со ссылками и Box<T> инварианты правил заимствования обеспечиваются во время компиляции. С RefCell<T> эти инварианты обеспечиваются во время выполнения. Со ссылками, если вы нарушите эти правила, вы получите ошибку компилятора. С RefCell<T>, если вы нарушите эти правила, ваша программа запаникует и завершится.
Преимущества проверки правил заимствования во время компиляции заключаются в том, что ошибки будут обнаружены раньше в процессе разработки, и нет влияния на производительность во время выполнения, потому что весь анализ завершается заранее. По этим причинам проверка правил заимствования во время компиляции является лучшим выбором в majority случаев, поэтому это поведение по умолчанию в Rust.
Преимущество проверки правил заимствования во время выполнения instead заключается в том, что certain безопасные с точки зрения памяти сценарии then разрешены, где они были бы запрещены проверками во время компиляции. Статический анализ, такой как компилятор Rust, по своей природе консервативен. Некоторые свойства кода невозможно обнаружить, анализируя код: самый известный пример — это проблема остановки (Halting Problem), которая выходит за рамки этой книги, но является интересной темой для исследования.
Поскольку некоторый анализ невозможен, если компилятор Rust не может быть уверен, что код соответствует правилам владения, он может отвергнуть правильную программу; таким образом, он консервативен. Если бы Rust принимал неправильную программу, пользователи не могли бы доверять гарантиям, которые даёт Rust. Однако, если Rust отвергает правильную программу, программист будет неудобен, но nothing катастрофическое не может произойти. Тип RefCell<T> полезен, когда вы уверены, что ваш код следует правилам заимствования, но компилятор не может понять и гарантировать это.
Подобно Rc<T>, RefCell<T> предназначен только для использования в однопоточных сценариях и выдаст ошибку компиляции, если вы попытаетесь использовать его в многопоточном контексте. Мы поговорим о том, как получить функциональность RefCell<T> в многопоточной программе, в Главе 16.
Вот краткое изложение причин для выбора Box<T>, Rc<T> или RefCell<T>:
Rc<T>позволяет иметь нескольких владельцев одних и тех же данных;Box<T>иRefCell<T>имеют единственного владельца.Box<T>позволяет иметь неизменяемые или изменяемые заимствования, проверяемые во время компиляции;Rc<T>позволяет only неизменяемые заимствования, проверяемые во время компиляции;RefCell<T>позволяет неизменяемые или изменяемые заимствования, проверяемые во время выполнения.- Поскольку
RefCell<T>позволяет изменяемые заимствования, проверяемые во время выполнения, вы можете изменять значение внутриRefCell<T>, даже когдаRefCell<T>является неизменяемым.
Изменение значения внутри неизменяемого значения — это шаблон внутренней изменяемости. Давайте рассмотрим ситуацию, в которой внутренняя изменяемость полезна, и изучим, как это возможно.
Использование внутренней изменяемости
Следствием правил заимствования является то, что когда у вас есть неизменяемое значение, вы не можете заимствовать его изменяемо. Например, этот код не скомпилируется:
fn main() {
let x = 5;
let y = &mut x;
}Если бы вы попытались скомпилировать этот код, вы получили бы следующую ошибку:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Однако бывают ситуации, когда было бы полезно, чтобы значение могло изменять себя в своих методах, но казаться неизменяемым для другого кода. Код вне методов значения не сможет изменять значение. Использование RefCell<T> — один из способов получить возможность внутренней изменяемости, но RefCell<T> не обходит правила заимствования completely: проверщик заимствований в компиляторе разрешает эту внутреннюю изменяемость, и правила заимствования проверяются во время выполнения instead. Если вы нарушите правила, вы получите panic! вместо ошибки компилятора.
Давайте разберём практический пример, где мы можем использовать RefCell<T> для изменения неизменяемого значения, и посмотрим, почему это полезно.
Тестирование с помощью Mock-объектов
Иногда во время тестирования программист использует один тип вместо другого, чтобы наблюдать определённое поведение и утверждать, что оно реализовано правильно. Этот тип-заменитель называется test double (тестовый двойник). Думайте об этом в смысле каскадёра в кинопроизводстве, где человек подменяет актёра для выполнения особенно сложной сцены. Тестовые двойники заменяют другие типы, когда мы запускаем тесты. Mock objects (Мок-объекты) — это specific типы тестовых двойников, которые записывают, что происходит во время теста, чтобы вы могли утверждать, что произошли правильные действия.
В Rust нет объектов в том же смысле, как в других языках, и в Rust нет встроенной в стандартную библиотеку функциональности мок-объектов, как в некоторых других языках. Однако вы definitely можете создать структуру, которая будет служить тем же целям, что и мок-объект.
Вот сценарий, который мы будем тестировать: мы создадим библиотеку, которая отслеживает значение относительно максимального значения и отправляет сообщения в зависимости от того, насколько текущее значение близко к максимальному. Например, эта библиотека могла бы использоваться для отслеживания квоты пользователя на количество вызовов API, которые ему разрешено делать.
Наша библиотека будет предоставлять only функциональность отслеживания близости значения к максимуму и того, какими должны быть сообщения и в какое время. От приложений, использующих нашу библиотеку, ожидается предоставление механизма отправки сообщений: приложение могло бы показывать сообщение пользователю directly, отправлять электронное письмо, отправлять текстовое сообщение или делать что-то ещё. Библиотеке не нужно знать эту деталь. Всё, что ей нужно, — это что-то, что реализует предоставляемый нами трейт с именем Messenger. Листинг 15-20 показывает код библиотеки.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Одна важная часть этого кода заключается в том, что трейт Messenger имеет один метод с именем send, который принимает неизменяемую ссылку на self и текст сообщения. Этот трейт — это интерфейс, который наш мок-объект должен реализовать, чтобы мок можно было использовать так же, как реальный объект. Другая важная часть заключается в том, что мы хотим протестировать поведение метода set_value у LimitTracker. Мы можем изменять то, что передаём для параметра value, но set_value не возвращает ничего, на что мы могли бы делать утверждения. Мы хотим иметь возможность сказать, что если мы создадим LimitTracker с чем-то, что реализует трейт Messenger, и определённым значением для max, то messenger будет получать указание отправлять соответствующие сообщения, когда мы передаём разные числа для value.
Нам нужен мок-объект, который instead отправки электронного письма или текстового сообщения, когда мы вызываем send, будет only отслеживать сообщения, которые ему велено отправить. Мы можем создать новый экземпляр мок-объекта, создать LimitTracker, который использует мок-объект, вызвать метод set_value у LimitTracker, а затем проверить, что мок-объект имеет ожидаемые нами сообщения. Листинг 15-21 показывает попытку реализовать мок-объект для этого, но проверщик заимствований не позволит это.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}Этот тестовый код определяет структуру MockMessenger, которая имеет поле sent_messages с Vec значений String для отслеживания сообщений, которые ему велено отправить. Мы также определяем ассоциированную функцию new для удобства создания новых значений MockMessenger, которые начинаются с пустого списка сообщений. Затем мы реализуем трейт Messenger для MockMessenger, чтобы мы могли дать MockMessenger в LimitTracker. В определении метода send мы берём сообщение, переданное в качестве параметра, и сохраняем его в списке sent_messages у MockMessenger.
В тесте мы проверяем, что происходит, когда LimitTracker получает указание установить value во что-то, что составляет более 75 процентов от значения max. Сначала мы создаём новый MockMessenger, который начнёт с пустого списка сообщений. Затем мы создаём новый LimitTracker и даём ему ссылку на новый MockMessenger и значение max, равное 100. Мы вызываем метод set_value у LimitTracker со значением 80, что составляет более 75 процентов от 100. Затем мы утверждаем, что список сообщений, которые отслеживает MockMessenger, теперь должен содержать одно сообщение.
Однако есть одна проблема с этим тестом, как показано здесь:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Мы не можем изменить MockMessenger для отслеживания сообщений, потому что метод send принимает неизменяемую ссылку на self. Мы также не можем принять предложение из текста ошибки использовать &mut self и в impl методе, и в определении трейта. Мы не хотим изменять трейт Messenger solely ради тестирования. Instead, нам нужно найти способ заставить наш тестовый код работать correctly с нашей существующей конструкцией.
Это ситуация, в которой может помочь внутренняя изменяемость! Мы сохраним sent_messages внутри RefCell<T>, и тогда метод send сможет изменять sent_messages для хранения сообщений, которые мы видели. Листинг 15-22 показывает, как это выглядит.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Поле sent_messages теперь имеет тип RefCell<Vec<String>> instead Vec<String>. В функции new мы создаём новый экземпляр RefCell<Vec<String>> вокруг пустого вектора.
Для реализации метода send первый параметр всё ещё является неизменяемым заимствованием self, что соответствует определению трейта. Мы вызываем borrow_mut на RefCell<Vec<String>> в self.sent_messages, чтобы получить изменяемую ссылку на значение внутри RefCell<Vec<String>>, которым является вектор. Затем мы можем вызвать push на изменяемой ссылке на вектор, чтобы отслеживать сообщения, отправленные во время теста.
Последнее изменение, которое мы должны сделать, — в утверждении: чтобы увидеть, сколько элементов находится во внутреннем векторе, мы вызываем borrow на RefCell<Vec<String>>, чтобы получить неизменяемую ссылку на вектор.
Теперь, когда вы видели, как использовать RefCell<T>, давайте углубимся в то, как это работает!
Отслеживание заимствований во время выполнения
При создании неизменяемых и изменяемых ссылок мы используем синтаксис & и &mut соответственно. С RefCell<T> мы используем методы borrow и borrow_mut, которые являются частью безопасного API, принадлежащего RefCell<T>. Метод borrow возвращает тип умного указателя Ref<T>, а borrow_mut возвращает тип умного указателя RefMut<T>. Оба типа реализуют Deref, поэтому мы можем обращаться с ними как с обычными ссылками.
RefCell<T> отслеживает, сколько умных указателей Ref<T> и RefMut<T> в настоящее время активно. Каждый раз, когда мы вызываем borrow, RefCell<T> увеличивает свой счётчик того, сколько неизменяемых заимствований активно. Когда значение Ref<T> выходит из области видимости, счётчик неизменяемых заимствований уменьшается на 1. Так же, как правила заимствования во время компиляции, RefCell<T> позволяет нам иметь много неизменяемых заимствований или одно изменяемое заимствование в любой момент времени.
Если мы попытаемся нарушить эти правила, instead получения ошибки компилятора, как было бы со ссылками, реализация RefCell<T> запаникует во время выполнения. Листинг 15-23 показывает модификацию реализации send из Листинга 15-22. Мы намеренно пытаемся создать два активных изменяемых заимствования для одной и той же области видимости, чтобы проиллюстрировать, что RefCell<T> предотвращает это во время выполнения.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Мы создаём переменную one_borrow для умного указателя RefMut<T>, возвращённого из borrow_mut. Затем мы создаём другое изменяемое заимствование таким же образом в переменной two_borrow. Это создаёт две изменяемые ссылки в одной и той же области видимости, что не разрешено. Когда мы запускаем тесты для нашей библиотеки, код в Листинге 15-23 скомпилируется без any ошибок, но тест завершится неудачно:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Обратите внимание, что код запаниковал с сообщением already borrowed: BorrowMutError. Так RefCell<T> обрабатывает нарушения правил заимствования во время выполнения.
Выбор перехвата ошибок заимствования во время выполнения rather than во время компиляции, как мы сделали здесь, означает, что вы potentially будете находить ошибки в своём коде позже в процессе разработки: possibly не until ваш код будет развёрнут в продакшене. Also, ваш код будет нести небольшие потери производительности во время выполнения в результате отслеживания заимствований во время выполнения rather than во время компиляции. However, использование RefCell<T> делает возможным написание мок-объекта, который может изменять себя для отслеживания сообщений, которые он видел, пока вы используете его в контексте, где разрешены only неизменяемые значения. Вы можете использовать RefCell<T>, несмотря на его компромиссы, чтобы получить больше функциональности, чем предоставляют обычные ссылки.
Разрешение нескольких владельцев изменяемых данных
Распространённый способ использования RefCell<T> — в combination с Rc<T>. Напомним, что Rc<T> позволяет вам иметь нескольких владельцев некоторых данных, но он даёт only неизменяемый доступ к этим данным. Если у вас есть Rc<T>, который содержит RefCell<T>, вы можете получить значение, которое может иметь нескольких владельцев и которое вы можете изменять!
Например, вспомните пример cons list из Листинга 15-18, где мы использовали Rc<T>, чтобы позволить нескольким спискам разделять владение другим списком. Поскольку Rc<T> содержит only неизменяемые значения, мы не можем изменять any из значений в списке once мы их создали. Давайте добавим RefCell<T> для его способности изменять значения в списках. Листинг 15-24 показывает, что, используя RefCell<T> в определении Cons, мы можем изменять значение, хранящееся во всех списках.
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {a:?}"); println!("b after = {b:?}"); println!("c after = {c:?}"); }
Мы создаём значение, которое является экземпляром Rc<RefCell<i32>>, и сохраняем его в переменной с именем value, чтобы мы могли обращаться к нему directly позже. Затем мы создаём List в a с вариантом Cons, который содержит value. Нам нужно клонировать value, чтобы и a, и value имели владение внутренним значением 5 rather than передавая владение от value к a или заставляя a заимствовать из value.
Мы оборачиваем список a в Rc<T>, чтобы, когда мы создаём списки b и c, они оба могли ссылаться на a, что мы и делали в Листинге 15-18.
После того как мы создали списки в a, b и c, мы хотим добавить 10 к значению в value. Мы делаем это, вызывая borrow_mut на value, что использует функцию автоматического разыменования, которую мы обсуждали в разделе «Где оператор ->?» в Главе 5, чтобы разыменовать Rc<T> до внутреннего значения RefCell<T>. Метод borrow_mut возвращает умный указатель RefMut<T>, и мы используем оператор разыменования на нём и изменяем внутреннее значение.
Когда мы печатаем a, b и c, мы видим, что все они имеют изменённое значение 15 rather than 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Этот метод довольно опрятен! Используя RefCell<T>, мы имеем внешне неизменяемое значение List. Но мы можем использовать методы на RefCell<T>, которые предоставляют доступ к его внутренней изменяемости, чтобы мы могли изменять наши данные, когда нам нужно. Проверки правил заимствования во время выполнения защищают нас от гонок данных, и sometimes стоит обменять немного скорости на эту гибкость в наших структурах данных. Обратите внимание, что RefCell<T> не работает для многопоточного кода! Mutex<T> — это потокобезопасная версия RefCell<T>, и мы обсудим Mutex<T> в Главе 16.
Циклы ссылок могут приводить к утечкам памяти
Гарантии безопасности памяти Rust делают трудным, но не невозможным, случайное создание памяти, которая никогда не очищается (известной как утечка памяти). Полное предотвращение утечек памяти не является одной из гарантий Rust, что означает, что утечки памяти являются безопасными для памяти в Rust. Мы можем видеть, что Rust допускает утечки памяти, используя Rc<T> и RefCell<T>: возможно создание ссылок, где элементы ссылаются друг на друга в цикле. Это создаёт утечки памяти, потому что счётчик ссылок каждого элемента в цикле никогда не достигнет 0, и значения никогда не будут удалены.
Создание цикла ссылок
Давайте посмотрим, как может произойти цикл ссылок и как его предотвратить, начиная с определения перечисления List и метода tail в Листинге 15-25.
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
Мы используем another вариацию определения List из Листинга 15-5. Второй элемент в варианте Cons теперь RefCell<Rc<List>>, что означает, что instead возможности изменять значение i32, как мы делали в Листинге 15-24, мы хотим изменять значение List, на которое указывает вариант Cons. Мы также добавляем метод tail, чтобы нам было удобно получать доступ ко второму элементу, если у нас есть вариант Cons.
В Листинге 15-26 мы добавляем функцию main, которая использует определения из Листинга 15-25. Этот код создаёт список в a и список в b, который указывает на список в a. Затем он изменяет список в a, чтобы он указывал на b, создавая цикл ссылок. В процессе есть операторы println!, чтобы показать, каковы счётчики ссылок в различных точках этого процесса.
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack. // println!("a next item = {:?}", a.tail()); }
Мы создаём экземпляр Rc<List>, содержащий значение List в переменной a с начальным списком 5, Nil. Затем мы создаём экземпляр Rc<List>, содержащий another значение List в переменной b, которое содержит значение 10 и указывает на список в a.
Мы изменяем a так, чтобы он указывал на b вместо Nil, создавая цикл. Мы делаем это, используя метод tail, чтобы получить ссылку на RefCell<Rc<List>> в a, которую мы помещаем в переменную link. Затем мы используем метод borrow_mut на RefCell<Rc<List>>, чтобы изменить значение внутри из Rc<List>, которое содержит значение Nil, на Rc<List> в b.
Когда мы запускаем этот код, оставляя последний println! закомментированным на moment, мы получим этот вывод:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Счётчик ссылок экземпляров Rc<List> в both a и b равен 2 after того, как мы изменяем список в a чтобы указывать на b. В конце main Rust удаляет переменную b, что уменьшает счётчик ссылок экземпляра Rc<List> b с 2 до 1. Память, которую Rc<List> имеет в куче, не будет удалена в этот point, потому что её счётчик ссылок равен 1, а не 0. Затем Rust удаляет a, что уменьшает счётчик ссылок экземпляра Rc<List> a с 2 до 1 также. Память этого экземпляра не может быть удалена either, потому что other экземпляр Rc<List> всё ещё ссылается на неё. Память, выделенная для списка, останется неосвобождённой навсегда. Чтобы визуализировать этот цикл ссылок, мы создали диаграмму на Рисунке 15-4.

Рисунок 15-4: Цикл ссылок списков a и b, указывающих друг на друга
Если вы раскомментируете последний println! и запустите программу, Rust попытается напечатать этот цикл с a, указывающим на b, указывающим на a и так далее, until он переполнит стек.
По сравнению с реальной программой, последствия создания цикла ссылок в этом примере не очень серьёзны: сразу after того, как мы создаём цикл ссылок, программа завершается. However, если бы более сложная программа выделяла много памяти в цикле и удерживала её в течение long времени, программа использовала бы больше памяти, чем нужно, и могла бы перегрузить систему, вызывая исчерпание доступной памяти.
Создание циклов ссылок не делается легко, но и не невозможно. Если у вас есть значения RefCell<T>, которые содержат значения Rc<T>, или similar вложенные комбинации типов с внутренней изменяемостью и подсчётом ссылок, вы должны гарантировать, что не создаёте циклы; вы не можете полагаться на Rust в их обнаружении. Создание цикла ссылок было бы логической ошибкой в вашей программе, которую вы должны использовать автоматизированные тесты, обзоры кода и other практики разработки программного обеспечения для минимизации.
Another решение для избежания циклов ссылок — реорганизация ваших структур данных так, чтобы some ссылки выражали владение, а some ссылки — нет. В результате вы можете иметь циклы, состоящие из some отношений владения и some отношений без владения, и only отношения владения влияют на то, будет ли значение удалено или нет. В Листинге 15-25 мы always хотим, чтобы варианты Cons владели своим списком, поэтому реорганизация структуры данных невозможна. Давайте рассмотрим пример использования графов, состоящих из родительских узлов и дочерних узлов, чтобы увидеть, когда отношения без владения являются подходящим способом предотвращения циклов ссылок.
Предотвращение циклов ссылок с помощью Weak<T>
До сих пор мы демонстрировали, что вызов Rc::clone увеличивает strong_count экземпляра Rc<T>, и экземпляр Rc<T> очищается only если его strong_count равен 0. Вы также можете создать слабую ссылку на значение внутри экземпляра Rc<T>, вызвав Rc::downgrade и передав ссылку на Rc<T>. Сильные ссылки (Strong references) — это то, как вы можете разделять владение экземпляром Rc<T>. Слабые ссылки (Weak references) не выражают отношение владения, и их счётчик не влияет на то, когда экземпляр Rc<T> очищается. Они не вызовут цикла ссылок, потому что any цикл, включающий some слабые ссылки, будет разорван, once счётчик сильных ссылок задействованных значений станет 0.
Когда вы вызываете Rc::downgrade, вы получаете умный указатель типа Weak<T>. Instead увеличения strong_count в экземпляре Rc<T> на 1, вызов Rc::downgrade увеличивает weak_count на 1. Тип Rc<T> использует weak_count для отслеживания того, сколько ссылок Weak<T> существует, similar strong_count. Разница в том, что weak_count не обязательно должен быть 0 для очистки экземпляра Rc<T>.
Поскольку значение, на которое ссылается Weak<T>, могло быть удалено, чтобы сделать anything со значением, на которое указывает Weak<T>, вы должны убедиться, что значение всё ещё существует. Сделайте это, вызвав метод upgrade на экземпляре Weak<T>, который вернёт Option<Rc<T>>. Вы получите результат Some, если значение Rc<T> ещё не было удалено, и результат None, если значение Rc<T> было удалено. Поскольку upgrade возвращает Option<Rc<T>>, Rust гарантирует, что случаи Some и None обрабатываются, и не будет недействительного указателя.
В качестве примера, instead использования списка, элементы которого знают only о следующем элементе, мы создадим дерево, элементы которого знают о своих дочерних элементах и своих родительских элементах.
Создание древовидной структуры данных
Для начала мы построим дерево с узлами, которые знают о своих дочерних узлах. Мы создадим структуру с именем Node, которая содержит собственное значение i32, а также ссылки на свои дочерние значения Node:
Файл: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Мы хотим, чтобы Node владел своими детьми, и мы хотим разделить это владение с переменными, чтобы мы могли получать доступ к каждому Node в дереве directly. Для этого мы определяем элементы Vec<T> как значения типа Rc<Node>. Мы также хотим изменять, какие узлы являются детьми другого узла, поэтому у нас есть RefCell<T> в children вокруг Vec<Rc<Node>>.
Далее мы используем наше определение структуры и создаём один экземпляр Node с именем leaf со значением 3 и без детей, и another экземпляр с именем branch со значением 5 и leaf как одним из его детей, как показано в Листинге 15-27.
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Мы клонируем Rc<Node> в leaf и сохраняем это в branch, что означает, что Node в leaf теперь имеет двух владельцев: leaf и branch. Мы можем попасть из branch в leaf через branch.children, но нет способа попасть из leaf в branch. Причина в том, что leaf не имеет ссылки на branch и не знает, что они связаны. Мы хотим, чтобы leaf знал, что branch является его родителем. Мы сделаем это далее.
Добавление ссылки от ребёнка к его родителю
Чтобы дочерний узел знал о своём родителе, нам нужно добавить поле parent в наше определение структуры Node. Проблема в том, чтобы решить, каким должен быть тип parent. Мы знаем, что он не может содержать Rc<T>, потому что это создало бы цикл ссылок с leaf.parent, указывающим на branch, и branch.children, указывающим на leaf, что вызвало бы то, что их значения strong_count никогда не станут 0.
Думая об отношениях another way, родительский узел должен владеть своими детьми: если родительский узел удалён, его дочерние узлы должны быть также удалены. However, ребёнок не должен владеть своим родителем: если мы удалим дочерний узел, родитель должен всё ещё существовать. Это случай для слабых ссылок!
Итак, instead Rc<T>, мы сделаем тип parent использующим Weak<T>, specifically RefCell<Weak<Node>>. Теперь наше определение структуры Node выглядит так:
Файл: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Узел сможет ссылаться на свой родительский узел, но не владеет своим родителем. В Листинге 15-28 мы обновляем main, чтобы использовать это новое определение, чтобы узел leaf имел способ ссылаться на своего родителя, branch.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Создание узла leaf выглядит similar Листингу 15-27 за исключением поля parent: leaf начинается без родителя, поэтому мы создаём новый, пустой экземпляр ссылки Weak<Node>.
В этот point, когда мы пытаемся получить ссылку на родителя leaf, используя метод upgrade, мы получаем значение None. Мы видим это в выводе из первого оператора println!:
leaf parent = None
Когда мы создаём узел branch, он также будет иметь новую ссылку Weak<Node> в поле parent, потому что branch не имеет родительского узла. У нас всё ещё есть leaf как один из детей branch. Once мы имеем экземпляр Node в branch, мы можем изменить leaf, чтобы дать ему ссылку Weak<Node> на его родителя. Мы используем метод borrow_mut на RefCell<Weak<Node>> в поле parent у leaf, а затем мы используем функцию Rc::downgrade, чтобы создать ссылку Weak<Node> на branch из Rc<Node> в branch.
Когда мы снова печатаем родителя leaf, на этот раз мы получим вариант Some, содержащий branch: Теперь leaf может обращаться к своему родителю! Когда мы печатаем leaf, мы также избегаем цикла, который в конечном итоге заканчивался переполнением стека, как у нас было в Листинге 15-26; ссылки Weak<Node> печатаются как (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Отсутствие бесконечного вывода указывает, что этот код не создал цикла ссылок. Мы также можем сказать это, посмотрев на значения, которые мы получаем от вызовов Rc::strong_count и Rc::weak_count.
Визуализация изменений strong_count и weak_count
Давайте посмотрим, как изменяются значения strong_count и weak_count экземпляров Rc<Node>, создав новую внутреннюю область видимости и переместив создание branch в эту область. Сделав это, мы можем увидеть, что происходит, когда branch создаётся, а затем удаляется, когда выходит из области видимости. Изменения показаны в Листинге 15-29.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
After создания leaf его Rc<Node> имеет сильный счётчик 1 и слабый счётчик 0. Во внутренней области видимости мы создаём branch и связываем его с leaf, в which point, когда мы печатаем счётчики, Rc<Node> в branch будет иметь сильный счётчик 1 и слабый счётчик 1 (для leaf.parent, указывающего на branch с Weak<Node>). Когда мы печатаем счётчики в leaf, мы увидим, что он будет иметь сильный счётчик 2, потому что branch теперь имеет клон Rc<Node> из leaf, сохранённый в branch.children, но будет still иметь слабый счётчик 0.
Когда внутренняя область видимости заканчивается, branch выходит из области видимости, и сильный счётчик Rc<Node> уменьшается до 0, поэтому его Node удаляется. Слабый счётчик 1 от leaf.parent не имеет влияния на то, будет ли Node удалён или нет, поэтому мы не получаем any утечек памяти!
Если мы попытаемся получить доступ к родителю leaf after конца области видимости, мы снова получим None. В конце программы Rc<Node> в leaf имеет сильный счётчик 1 и слабый счётчик 0, потому что переменная leaf теперь again является единственной ссылкой на Rc<Node>.
Вся логика, которая управляет счётчиками и удалением значений, встроена в Rc<T> и Weak<T> и их реализации трейта Drop. Указав, что отношение от ребёнка к его родителю должно быть ссылкой Weak<T> в определении Node, вы able иметь родительские узлы, указывающие на дочерние узлы, и наоборот без создания цикла ссылок и утечек памяти.
Итоги
Эта глава охватила, как использовать умные указатели для создания различных гарантий и компромиссов от тех, которые Rust делает по умолчанию с обычными ссылками. Тип Box<T> имеет известный размер и указывает на данные, выделенные в куче. Тип Rc<T> отслеживает количество ссылок на данные в куче, чтобы данные могли иметь нескольких владельцев. Тип RefCell<T> с его внутренней изменяемостью даёт нам тип, который мы можем использовать, когда нам нужен неизменяемый тип, но необходимо изменить внутреннее значение этого типа; он также обеспечивает соблюдение правил заимствования во время выполнения instead во время компиляции.
Также обсуждались трейты Deref и Drop, которые обеспечивают много функциональности умных указателей. Мы исследовали циклы ссылок, которые могут вызывать утечки памяти, и как предотвратить их с помощью Weak<T>.
Если эта глава возбудила ваш интерес и вы хотите реализовать свои собственные умные указатели, проверьте «The Rustonomicon» для получения more полезной информации.
Далее мы поговорим о конкурентности в Rust. Вы даже узнаете о нескольких новых умных указателях.
Безопасная конкурентность
Безопасная и эффективная обработка конкурентного программирования — ещё одна из главных целей Rust. Конкурентное программирование, в котором разные части программы выполняются независимо, и параллельное программирование, в котором разные части программы выполняются одновременно, становятся всё более важными, поскольку всё больше компьютеров используют преимущества своих многочисленных процессоров. Исторически программирование в этих контекстах было сложным и подверженным ошибкам. Rust надеется это изменить.
Изначально команда Rust считала, что обеспечение безопасности памяти и предотвращение проблем конкурентности — это две отдельные задачи, которые следует решать разными методами. Со временем команда обнаружила, что система владения и типизации — это мощный набор инструментов для управления безопасностью памяти и проблемами конкурентности! Используя владение и проверку типов, многие ошибки конкурентности в Rust становятся ошибками времени компиляции, а не времени выполнения. Поэтому вместо того, чтобы заставлять вас тратить много времени на попытки воспроизведения точных обстоятельств, при которых возникает ошибка конкурентности во время выполнения, некорректный код откажется компилироваться и представит ошибку с объяснением проблемы. В результате вы можете исправить свой код во время работы над ним, а не потенциально после того, как он был выпущен в продакшен. Мы прозвали этот аспект Rust бестрашной конкурентностью. Бестрашная конкурентность позволяет вам писать код, свободный от незаметных ошибок и легко поддающийся рефакторингу без внесения новых ошибок.
Примечание: Для простоты мы будем называть многие проблемы конкурентными, вместо того чтобы быть более точными и говорить конкурентные и/или параллельные. В этой главе, пожалуйста, мысленно подставляйте конкурентные и/или параллельные везде, где мы используем конкурентные. В следующей главе, где различие более важно, мы будем более конкретны.
Многие языки догматичны в отношении решений, которые они предлагают для обработки проблем конкурентности. Например, Erlang имеет элегантную функциональность для конкурентности с передачей сообщений, но имеет лишь малопонятные способы совместного использования состояния между потоками. Поддержка только подмножества возможных решений — это разумная стратегия для языков высокого уровня, потому что язык высокого уровня сулит преимущества от отказа от некоторого контроля ради получения абстракций. Однако от языков низкого уровня ожидается, что они предоставят решение с наилучшей производительностью в любой given ситуации и имеют меньше абстракций над оборудованием. Поэтому Rust предлагает variety инструментов для моделирования проблем любым способом, подходящим для вашей ситуации и требований.
Вот темы, которые мы рассмотрим в этой главе:
- Как создавать потоки для выполнения нескольких частей кода одновременно
- Конкурентность с передачей сообщений, где каналы отправляют сообщения между потоками
- Конкурентность с разделяемым состоянием, где несколько потоков имеют доступ к некоторым данным
- Трейты
SyncиSend, которые расширяют гарантии конкурентности Rust на пользовательские типы, а также на типы из стандартной библиотеки
Использование потоков для одновременного выполнения кода
В большинстве современных операционных систем код выполняемой программы запускается в процессе, и операционная система управляет несколькими процессами одновременно. Внутри программы также могут быть независимые части, которые выполняются одновременно. Функциональные возможности, которые запускают эти независимые части, называются потоками. Например, веб-сервер может иметь несколько потоков, чтобы иметь возможность обрабатывать более одного запроса одновременно.
Разделение вычислений в вашей программе на несколько потоков для одновременного выполнения нескольких задач может повысить производительность, но также добавляет сложности. Поскольку потоки могут выполняться одновременно, нет никаких inherent гарантий относительно порядка, в котором части вашего кода в разных потоках будут выполняться. Это может привести к проблемам, таким как:
- Состояния гонки (Race conditions), при которых потоки обращаются к данным или ресурсам в непоследовательном порядке
- Взаимные блокировки (Deadlocks), при которых два потока ждут друг друга, не позволяя обоим потокам продолжить выполнение
- Ошибки, которые происходят только в определённых ситуациях и которые трудно воспроизвести и надёжно исправить
Rust пытается смягчить негативные эффекты от использования потоков, но программирование в многопоточном контексте всё равно требует тщательного обдумывания и структуры кода, которая отличается от программ, выполняющихся в одном потоке.
Языки программирования реализуют потоки несколькими разными способами, и многие операционные системы предоставляют API, который язык программирования может вызывать для создания новых потоков. Стандартная библиотека Rust использует модель реализации потоков 1:1, при которой программа использует один поток операционной системы на один языковой поток. Существуют крейты, которые реализуют другие модели многопоточности, делающие иные компромиссы по сравнению с моделью 1:1. (Асинхронная система Rust, которую мы увидим в следующей главе, также предоставляет другой подход к конкурентности.)
Создание нового потока с помощью spawn
Чтобы создать новый поток, мы вызываем функцию thread::spawn и передаём ей замыкание (мы говорили о замыканиях в Главе 13), содержащее код, который мы хотим выполнить в новом потоке. Пример в Листинге 16-1 выводит некоторый текст из главного потока и другой текст из нового потока.
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
Обратите внимание, что когда главный поток программы Rust завершается, все порождённые потоки завершаются, независимо от того, закончили они выполнение или нет. Вывод этой программы может немного отличаться каждый раз, но он будет выглядеть примерно так:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Вызовы thread::sleep принудительно останавливают выполнение потока на короткое время, позволяя выполняться другому потоку. Потоки, вероятно, будут чередоваться, но это не гарантировано: это зависит от того, как ваша операционная система планирует потоки. В этом запуске главный поток напечатал первым, даже though оператор печати из порождённого потока appears первым в коде. И даже though мы сказали порождённому потоку печатать до тех пор, пока i не станет 9, он успел дойти только до 5, прежде чем главный поток завершился.
Если вы запустите этот код и увидите вывод только из главного потока или не увидите перекрытия, попробуйте увеличить числа в диапазонах, чтобы создать больше возможностей для операционной системы переключаться между потоками.
Ожидание завершения всех потоков
Код в Листинге 16-1 не только преждевременно останавливает порождённый поток в большинстве случаев из-за завершения главного потока, но и, поскольку нет гарантии порядка выполнения потоков, мы также не можем гарантировать, что порождённый поток вообще будет запущен!
Мы можем исправить проблему с тем, что порождённый поток не запускается или завершается преждевременно, сохранив возвращаемое значение thread::spawn в переменной. Возвращаемый тип thread::spawn — JoinHandle<T>. JoinHandle<T> — это владеемое значение, которое при вызове метода join будет ждать завершения своего потока. Листинг 16-2 показывает, как использовать JoinHandle<T> потока, который мы создали в Листинге 16-1, и как вызвать join, чтобы убедиться, что порождённый поток завершится до выхода из main.
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
Вызов join для дескриптора блокирует текущий выполняющийся поток до тех пор, пока поток, представленный дескриптором, не завершится. Блокировка потока означает, что поток не может выполнять работу или завершаться. Поскольку мы поместили вызов join после цикла for главного потока, выполнение Листинга 16-2 должно давать вывод, похожий на этот:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Два потока продолжают чередоваться, но главный поток ждет из-за вызова handle.join() и не завершается, пока порождённый поток не закончит выполнение.
Но давайте посмотрим, что происходит, когда мы перемещаем handle.join() перед циклом for в main, вот так:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
Главный поток будет ждать завершения порождённого потока, а затем выполнит свой цикл for, так что вывод больше не будет перемежаться, как показано здесь:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Мелкие детали, такие как место вызова join, могут влиять на то, выполняются ли ваши потоки одновременно.
Использование замыканий move с потоками
Мы часто будем использовать ключевое слово move с замыканиями, передаваемыми в thread::spawn, потому что замыкание тогда забирает во владение значения, которые оно использует из окружения, таким образом передавая владение этими значениями из одного потока в другой. В разделе «Захват ссылок или перемещение владения» в Главе 13 мы обсуждали move в контексте замыканий. Теперь мы сосредоточимся больше на взаимодействии между move и thread::spawn.
Обратите внимание в Листинге 16-1, что замыкание, которое мы передаём в thread::spawn, не принимает аргументов: мы не используем никакие данные из главного потока в коде порождённого потока. Чтобы использовать данные из главного потока в порождённом потоке, замыкание порождённого потока должно захватывать нужные ему значения. Листинг 16-3 показывает попытку создать вектор в главном потоке и использовать его в порождённом потоке. Однако это пока не будет работать, как вы увидите через мгновение.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Замыкание использует v, поэтому оно захватит v и сделает его частью окружения замыкания. Поскольку thread::spawn запускает это замыкание в новом потоке, мы должны иметь возможность получить доступ к v внутри этого нового потока. Но когда мы компилируем этот пример, мы получаем следующую ошибку:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust выводит (infers), как захватить v, и поскольку println! нужна только ссылка на v, замыкание пытается заимствовать v. Однако возникает проблема: Rust не может определить, как долго будет работать порождённый поток, поэтому он не знает, будет ли ссылка на v всегда действительной.
Листинг 16-4 предоставляет сценарий, в котором более вероятно наличие ссылки на v, которая будет недействительной.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}Если бы Rust позволил нам запустить этот код, существует вероятность, что порождённый поток будет немедленно помещён в фоновый режим без запуска вообще. Порождённый поток имеет ссылку на v внутри, но главный поток немедленно освобождает v, используя функцию drop, которую мы обсуждали в Главе 15. Затем, когда порождённый поток начинает выполняться, v больше не действителен, поэтому ссылка на него также недействительна. О нет!
Чтобы исправить ошибку компилятора в Листинге 16-3, мы можем использовать совет из сообщения об ошибке:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Добавляя ключевое слово move перед замыканием, мы принудительно заставляем замыкание забирать во владение значения, которые оно использует, вместо того чтобы позволить Rust вывести, что оно должно заимствовать значения. Модификация Листинга 16-3, показанная в Листинге 16-5, будет компилироваться и работать так, как мы задумали.
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {v:?}"); }); handle.join().unwrap(); }
Нас может потяогнуть попробовать то же самое, чтобы исправить код в Листинге 16-4, где главный поток вызывал drop, используя замыкание move. Однако это исправление не сработает, потому то, что пытается сделать Листинг 16-4, запрещено по другой причине. Если бы мы добавили move к замыканию, мы бы переместили v в окружение замыкания и больше не смогли бы вызвать drop для него в главном потоке. Вместо этого мы получили бы эту ошибку компилятора:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Правила владения Rust снова спасли нас! Мы получили ошибку из кода в Листинге 16-3, потому что Rust был консервативен и только заимствовал v для потока, что означало, что главный поток теоретически мог сделать ссылку порождённого потока недействительной. Приказав Rust переместить владение v в порождённый поток, мы гарантируем Rust, что главный поток больше не будет использовать v. Если мы изменим Листинг 16-4 таким же образом, мы тогда нарушим правила владения, когда попытаемся использовать v в главном потоке. Ключевое слово move переопределяет консервативный по умолчанию подход Rust к заимствованию; оно не позволяет нам нарушать правила владения.
Теперь, когда мы рассмотрели, что такое потоки и методы, предоставляемые API потоков, давайте посмотрим на некоторые ситуации, в которых мы можем использовать потоки.
Передача данных между потоками с помощью обмена сообщениями
Одним из всё более популярных подходов к обеспечению безопасной конкурентности является передача сообщений, где потоки или акторы общаются, отправляя друг другу сообщения, содержащие данные. Вот идея, выраженная в слогане из документации языка Go: «Не общайтесь, разделяя память; вместо этого разделяйте память, общаясь».
Для реализации конкурентности с отправкой сообщений стандартная библиотека Rust предоставляет реализацию каналов. Канал — это общая концепция программирования, при которой данные отправляются из одного потока в другой.
Вы можете представить канал в программировании как направленный водный канал, такой как ручей или река. Если вы поместите что-то вроде резиновой уточки в реку, она поплывёт вниз по течению до конца водного пути.
Канал состоит из двух половин: передатчика и приёмника. Половина передатчика — это место upstream, где вы бросаете резиновую уточку в реку, а половина приёмника — это место, где резиновая уточка оказывается downstream. Одна часть вашего кода вызывает методы передатчика с данными, которые вы хотите отправить, а другая часть проверяет принимающий конец на наличие поступающих сообщений. Говорят, что канал закрыт, если либо передатчик, либо приёмник уничтожены.
Здесь мы будем работать над программой, в которой один поток генерирует значения и отправляет их по каналу, а другой поток получает значения и выводит их. Мы будем отправлять простые значения между потоками, используя канал, чтобы проиллюстрировать функциональность. Как только вы ознакомитесь с техникой, вы сможете использовать каналы для любых потоков, которым нужно общаться друг с другом, например, для чат-системы или системы, в которой многие потоки выполняют части вычисления и отправляют части в один поток, который агрегирует результаты.
Сначала, в Листинге 16-6, мы создадим канал, но ничего не будем с ним делать. Обратите внимание, что это пока не скомпилируется, потому что Rust не может определить, значения какого типа мы хотим отправлять по каналу.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Мы создаём новый канал с помощью функции mpsc::channel; mpsc означает multiple producer, single consumer (несколько производителей, один потребитель). Короче говоря, то, как стандартная библиотека Rust реализует каналы, означает, что канал может иметь несколько отправляющих концов, которые производят значения, но только один принимающий конец, который потребляет эти значения. Представьте несколько ручьев, сливающихся в одну большую реку: всё, что отправлено по любому из ручьев, окажется в одной реке в конце. Мы начнём с одного производителя, но добавим несколько производителей, когда этот пример заработает.
Функция mpsc::channel возвращает кортеж, первый элемент которого — отправляющий конец (передатчик), а второй элемент — принимающий конец (приёмник). Аббревиатуры tx и rx традиционно используются во многих областях для transmitter (передатчик) и receiver (приёмник) соответственно, поэтому мы называем наши переменные так, чтобы обозначить каждый конец. Мы используем оператор let с шаблоном, который деструктурирует кортежи; мы обсудим использование шаблонов в операторах let и деструктуризацию в Главе 19. Пока знайте, что использование оператора let таким образом — это удобный подход для извлечения частей кортежа, возвращаемого mpsc::channel.
Давайте переместим передающий конец в порождённый поток и заставим его отправить одну строку, чтобы порождённый поток общался с главным потоком, как показано в Листинге 16-7. Это похоже на помещение резиновой уточки в реку upstream или отправку сообщения чата из одного потока в другой.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); }
Снова мы используем thread::spawn для создания нового потока, а затем используем move для перемещения tx в замыкание, чтобы порождённый поток владел tx. Порождённому потоку необходимо владеть передатчиком, чтобы иметь возможность отправлять сообщения через канал.
Передатчик имеет метод send, который принимает значение, которое мы хотим отправить. Метод send возвращает тип Result<T, E>, поэтому, если приёмник уже уничтожен и некуда отправлять значение, операция отправки вернёт ошибку. В этом примере мы вызываем unwrap, чтобы паниковать в случае ошибки. Но в реальном приложении мы бы обработали это properly: вернитесь к Главе 9, чтобы повторить стратегии правильной обработки ошибок.
В Листинге 16-8 мы получим значение от приёмника в главном потоке. Это похоже на извлечение резиновой уточки из воды в конце реки или получение сообщения чата.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Got: {received}"); }
У приёмника есть два полезных метода: recv и try_recv. Мы используем recv, сокращение от receive (получить), который будет блокировать выполнение главного потока и ждать, пока значение не будет отправлено по каналу. Как только значение отправлено, recv вернёт его в Result<T, E>. Когда передатчик закроется, recv вернёт ошибку, сигнализируя, что больше значений не будет.
Метод try_recv не блокирует, а вместо этого немедленно возвращает Result<T, E>: значение Ok, содержащее сообщение, если оно доступно, и значение Err, если в этот раз сообщений нет. Использование try_recv полезно, если у этого потока есть другая работа, пока он ждёт сообщений: мы могли бы написать цикл, который время от времени вызывает try_recv, обрабатывает сообщение, если оно доступно, а в противном случае выполняет другую работу в течение короткого времени, пока снова не проверит.
Мы использовали recv в этом примере для простоты; у нас нет другой работы для главного потока, кроме как ждать сообщения, поэтому блокировка главного потока уместна.
Когда мы запустим код из Листинга 16-8, мы увидим значение, выведенное из главного потока:
Got: hi
Отлично!
Передача владения через каналы
Правила владения играют жизненно важную роль в отправке сообщений, потому что они помогают писать безопасный конкурентный код. Предотвращение ошибок в конкурентном программировании — это преимущество мышления о владении во всех ваших программах на Rust. Давайте проведём эксперимент, чтобы показать, как каналы и владение работают вместе, чтобы предотвратить проблемы: мы попытаемся использовать значение val в порождённом потоке после того, как отправили его по каналу. Попробуйте скомпилировать код в Листинге 16-9, чтобы понять, почему этот код не разрешён.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}Здесь мы пытаемся напечатать val после того, как отправили его по каналу через tx.send. Разрешить это было бы плохой идеей: как только значение отправлено в другой поток, этот поток может изменить или удалить его до того, как мы попытаемся использовать значение снова. Потенциально модификации другого потока могут вызвать ошибки или неожиданные результаты из-за inconsistent или несуществующих данных. Однако Rust выдаёт нам ошибку, если мы пытаемся скомпилировать код из Листинга 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Наша ошибка конкурентности вызвала ошибку времени компиляции. Функция send забирает владение своим параметром, и когда значение перемещается, приёмник забирает владение им. Это мешает нам случайно использовать значение again после его отправки; система владения проверяет, что всё в порядке.
Отправка нескольких значений
Код в Листинге 16-8 скомпилировался и запустился, но он не показал нам чётко, что два отдельных потока общаются друг с другом через канал.
В Листинге 16-10 мы внесли некоторые изменения, которые докажут, что код в Листинге 16-8 выполняется конкурентно: порождённый поток теперь будет отправлять несколько сообщений и делать паузу на секунду между каждым сообщением.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}На этот раз порождённый поток имеет вектор строк, которые мы хотим отправить в главный поток. Мы перебираем их, отправляя каждую individually, и делаем паузу между каждой, вызывая функцию thread::sleep со значением Duration в одну секунду.
В главном потоке мы больше не вызываем функцию recv явно: вместо этого мы обращаемся с rx как с итератором. Для каждого полученного значения мы выводим его. Когда канал закрывается, итерация заканчивается.
При запуске кода из Листинга 16-10 вы должны увидеть следующий вывод с паузой в одну секунду между каждой строкой:
Got: hi
Got: from
Got: the
Got: thread
Поскольку у нас нет никакого кода, который приостанавливает или задерживает выполнение в цикле for в главном потоке, мы можем сказать, что главный поток ждет получения значений от порождённого потока.
Создание нескольких производителей
Ранее мы упоминали, что mpsc была аббревиатурой для multiple producer, single consumer (несколько производителей, один потребитель). Давайте используем mpsc и расширим код в Листинге 16-10, чтобы создать несколько потоков, которые все отправляют значения одному и тому же приёмнику. Мы можем сделать это, клонировав передатчик, как показано в Листинге 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}На этот раз, прежде чем создать первый порождённый поток, мы вызываем clone для передатчика. Это даст нам новый передатчик, который мы можем передать первому порождённому потоку. Мы передаём оригинальный передатчик второму порождённому потоку. Это даёт нам два потока, каждый из которых отправляет разные сообщения одному приёмнику.
Когда вы запустите код, ваш вывод должен выглядеть примерно так:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Вы можете увидеть значения в другом порядке, в зависимости от вашей системы. Это то, что делает конкурентность интересной, а также сложной. Если вы поэкспериментируете с thread::sleep, давая ему различные значения в разных потоках, каждый запуск будет более недетерминированным и будет создавать different вывод каждый раз.
Теперь, когда мы рассмотрели, как работают каналы, давайте посмотрим на другой метод конкурентности.
Конкурентность с разделяемым состоянием
Передача сообщений — это хороший способ обработки конкурентности, но не единственный. Другой метод заключается в том, чтобы несколько потоков обращались к одним и тем же разделяемым данным. Рассмотрим ещё раз эту часть слогана из документации языка Go: «Не общайтесь, разделяя память».
Как бы выглядело общение путём разделения памяти? Кроме того, почему энтузиасты передачи сообщений предостерегают от использования разделения памяти?
В некотором смысле каналы в любом языке программирования похожи на единоличное владение, потому что once вы передаёте значение по каналу, вы больше не должны использовать это значение. Конкурентность с разделяемой памятью похожа на множественное владение: несколько потоков могут обращаться к одной и той же области памяти одновременно. Как вы видели в Главе 15, где умные указатели сделали множественное владение возможным, множественное владение может добавлять сложности, потому что этими разными владельцами нужно управлять. Система типов и правила владения Rust greatly помогают в правильной организации этого управления. Для примера давайте рассмотрим мьютексы — один из наиболее распространённых примитивов конкурентности для разделяемой памяти.
Управление доступом с помощью мьютексов
Мьютекс — это сокращение от mutual exclusion (взаимное исключение), так как мьютекс позволяет only одному потоку получать доступ к некоторым данным в любой given момент времени. Чтобы получить доступ к данным в мьютексе, поток должен сначала сигнализировать, что он хочет доступ, запросив захват блокировки мьютекса. Блокировка — это структура данных, которая является частью мьютекса и отслеживает, кто в настоящее время имеет эксклюзивный доступ к данным. Поэтому мьютекс описывается как защищающий данные, которые он содержит, через систему блокировок.
Мьютексы имеют репутацию сложных в использовании, потому что вы должны помнить два правила:
- Вы должны попытаться захватить блокировку before использования данных.
- Когда вы закончили работать с данными, которые защищает мьютекс, вы должны разблокировать данные, чтобы другие потоки могли захватить блокировку.
Для реальной метафоры мьютекса представьте панельную дискуссию на конференции only с одним микрофоном. Прежде чем участник панели сможет говорить, он должен попросить или сигнализировать, что хочет использовать микрофон. Когда он получает микрофон, он может говорить столько, сколько захочет, а затем передать микрофон следующему участнику панели, который попросит слово. Если участник панели забудет передать микрофон, когда закончит, никто другой не сможет говорить. Если управление общим микрофоном пойдёт не так, панель не будет работать как planned!
Управление мьютексами может быть невероятно сложным для правильной реализации, поэтому многие люди enthusiastic о каналах. Однако благодаря системе типов и правилам владения Rust вы не можете ошибиться с блокировкой и разблокировкой.
API Mutex<T>
В качестве примера использования мьютекса давайте начнём с использования мьютекса в однопоточном контексте, как показано в Листинге 16-12.
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {m:?}"); }
Как и для многих типов, мы создаём Mutex<T> с помощью ассоциированной функции new. Чтобы получить доступ к данным внутри мьютекса, мы используем метод lock для получения блокировки. Этот вызов будет блокировать текущий поток, чтобы он не мог выполнять any работу, пока не наступит его очередь получить блокировку.
Вызов lock завершится ошибкой, если другой поток, удерживающий блокировку, запаникует. В этом случае никто никогда не сможет получить блокировку, поэтому мы выбрали unwrap и заставляем этот поток паниковать, если мы окажемся в такой ситуации.
После того как мы получили блокировку, мы можем обращаться с возвращаемым значением, названным num в этом случае, как с изменяемой ссылкой на внутренние данные. Система типов гарантирует, что мы получим блокировку before использования значения в m. Тип m — Mutex<i32>, а не i32, поэтому мы должны вызвать lock, чтобы иметь возможность использовать значение i32. Мы не можем забыть; система типов не позволит нам получить доступ к внутреннему i32 иначе.
Вызов lock возвращает тип с именем MutexGuard, обёрнутый в LockResult, который мы обработали вызовом unwrap. Тип MutexGuard реализует Deref для указания на наши внутренние данные; этот тип также имеет реализацию Drop, которая автоматически освобождает блокировку, когда MutexGuard выходит из области видимости, что происходит в конце внутренней области видимости. В результате мы не рискуем забыть освободить блокировку и заблокировать мьютекс для использования другими потоками, потому что освобождение блокировки происходит automatically.
После сброса блокировки мы можем вывести значение мьютекса и увидеть, что нам удалось изменить внутреннее i32 на 6.
Разделяемый доступ к Mutex<T>
Теперь давайте попробуем разделить значение между несколькими потоками, используя Mutex<T>. Мы запустим 10 потоков и заставим каждый из них увеличить значение счётчика на 1, чтобы счётчик изменился с 0 на 10. Пример в Листинге 16-13 будет содержать ошибку компиляции, и мы используем эту ошибку, чтобы узнать больше об использовании Mutex<T> и о том, как Rust помогает нам использовать его correctly.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Мы создаём переменную counter, чтобы хранить i32 внутри Mutex<T>, как мы делали в Листинге 16-12. Далее мы создаём 10 потоков, перебирая диапазон чисел. Мы используем thread::spawn и даём всем потокам одно и то же замыкание: такое, которое перемещает counter в поток, получает блокировку на Mutex<T>, вызывая метод lock, а затем добавляет 1 к значению в мьютексе. Когда поток завершает выполнение своего замыкания, num выходит из области видимости и освобождает блокировку, чтобы другой поток мог её получить.
В главном потоке мы собираем все дескрипторы присоединения (join handles). Затем, как мы делали в Листинге 16-2, мы вызываем join для каждого дескриптора, чтобы убедиться, что все потоки завершатся. В этот момент главный поток получит блокировку и выведет результат работы программы.
Мы намекнули, что этот пример не скомпилируется. Теперь давайте выясним, почему!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Сообщение об ошибке гласит, что значение counter было перемещено на предыдущей итерации цикла. Rust говорит нам, что мы не можем переместить владение блокировкой counter в несколько потоков. Давайте исправим ошибку компиляции с помощью метода множественного владения, который мы обсуждали в Главе 15.
Множественное владение с несколькими потоками
В Главе 15 мы передавали значение нескольким владельцам, используя умный указатель Rc<T> для создания значения с подсчётом ссылок. Давайте сделаем то же самое здесь и посмотрим, что произойдёт. Мы обернём Mutex<T> в Rc<T> в Листинге 16-14 и клонируем Rc<T> before перемещения владения в поток.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Снова компилируем и получаем... другие ошибки! Компилятор учит нас многому:
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Вау, это сообщение об ошибке очень многословно! Вот важная часть, на которой нужно сосредоточиться: `Rc<Mutex<i32>>` cannot be sent between threads safely. Компилятор также сообщает нам причину: the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Мы поговорим о Send в следующем разделе: это один из трейтов, который гарантирует, что типы, которые мы используем с потоками, предназначены для использования в конкурентных ситуациях.
К сожалению, Rc<T> небезопасно разделять между потоками. Когда Rc<T> управляет счётчиком ссылок, он добавляет к счётчику при каждом вызове clone и вычитает из счётчика, когда каждый клон удаляется. Но он не использует any примитивы конкурентности, чтобы гарантировать, что изменения счётчика не могут быть прерваны другим потоком. Это может привести к неверным счетчикам — subtle ошибкам, которые, в свою очередь, могут привести к утечкам памяти или удалению значения before того, как мы закончим с ним работать. Что нам нужно, так это тип, exactly похожий на Rc<T>, но который вносит изменения в счётчик ссылок потокобезопасным способом.
Атомарный подсчёт ссылок с Arc<T>
К счастью, Arc<T> является типом, подобным Rc<T>, который безопасно использовать в конкурентных ситуациях. Буква a означает atomic (атомарный), то есть это атомарно подсчитываемый тип ссылок. Атомарные операции — это дополнительный вид примитивов конкурентности, которые мы не будем здесь подробно рассматривать: см. документацию стандартной библиотеки для std::sync::atomic для получения более detailed информации. На данном этапе вам просто нужно знать, что атомарные операции работают как примитивные типы, но безопасны для разделения между потоками.
Вам может быть интересно, почему все примитивные типы не являются атомарными и почему типы стандартной библиотеки не реализованы для использования Arc<T> по умолчанию. Причина в том, что потокобезопасность comes с штрафом производительности, который вы хотите платить only тогда, когда вам это really нужно. Если вы просто выполняете операции со значениями в within одного потока, ваш код может работать faster, если ему не нужно обеспечивать гарантии, предоставляемые атомарными операциями.
Вернёмся к нашему примеру: Arc<T> и Rc<T> имеют одинаковый API, поэтому мы исправляем нашу программу, изменяя строку use, вызов new и вызов clone. Код в Листинге 16-15 finally скомпилируется и запустится.
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Этот код выведет следующее:
Result: 10
Мы сделали это! Мы посчитали от 0 до 10, что может показаться не очень впечатляющим, но это научило нас многому о Mutex<T> и потокобезопасности. Вы также можете использовать структуру этой программы для выполнения более сложных операций, чем просто увеличение счётчика. Используя эту стратегию, вы можете разделить вычисление на независимые части, распределить эти части по потокам, а затем использовать Mutex<T>, чтобы каждый поток обновлял конечный результат своей частью.
Обратите внимание, что если вы выполняете простые числовые операции, существуют типы проще, чем Mutex<T>, предоставляемые модулем std::sync::atomic стандартной библиотеки. Эти типы обеспечивают безопасный, конкурентный, атомарный доступ к примитивным типам. Мы выбрали использование Mutex<T> с примитивным типом для этого примера, чтобы мы могли сосредоточиться на том, как работает Mutex<T>.
Сравнение RefCell<T>/Rc<T> и Mutex<T>/Arc<T>
Вы, возможно, заметили, что counter является неизменяемым, но мы могли получить изменяемую ссылку на значение внутри него; это означает, что Mutex<T> обеспечивает внутреннюю изменяемость (interior mutability), как и семейство Cell. Таким же образом, как мы использовали RefCell<T> в Главе 15, чтобы позволить нам изменять содержимое внутри Rc<T>, мы используем Mutex<T> для изменения содержимого внутри Arc<T>.
Ещё одна деталь, которую следует отметить, заключается в том, что Rust не может защитить вас от всех видов логических ошибок, когда вы используете Mutex<T>. Вспомните из Главы 15, что использование Rc<T> связано с риском создания циклов ссылок, где два значения Rc<T> ссылаются друг на друга, вызывая утечки памяти. Аналогично, Mutex<T> связан с риском создания взаимных блокировок (deadlocks). Они возникают, когда операции необходимо заблокировать два ресурса, и два потока захватили по одной блокировке, заставляя их ждать друг друга вечно. Если вам интересны взаимные блокировки, попробуйте создать программу на Rust, в которой есть взаимная блокировка; затем изучите стратегии смягчения взаимных блокировок для мьютексов на любом языке и попробуйте реализовать их в Rust. Документация API стандартной библиотеки для Mutex<T> и MutexGuard предлагает useful информацию.
Мы завершим эту главу, рассказав о трейтах Send и Sync и о том, как мы можем использовать их с пользовательскими типами.
Расширяемая конкурентность с Send и Sync
Интересно, что почти каждая функция конкурентности, о которой мы говорили до сих пор в этой главе, была частью стандартной библиотеки, а не языка. Ваши варианты обработки конкурентности не ограничиваются языком или стандартной библиотекой; вы можете написать свои собственные функции конкурентности или использовать написанные другими.
Однако среди ключевых концепций конкурентности, встроенных в язык, а не в стандартную библиотеку, находятся трейты-маркеры std::marker Send и Sync.
Передача владения между потоками
Трейт-маркер Send указывает, что владение значениями типа, реализующего Send, может передаваться между потоками. Почти каждый тип Rust реализует Send, но есть некоторые исключения, включая Rc<T>: он не может реализовать Send, потому что если бы вы клонировали значение Rc<T> и попытались передать владение клоном другому потоку, оба потока могли бы обновлять счётчик ссылок одновременно. По этой причине Rc<T> реализован для использования в однопоточных ситуациях, где вы не хотите платить штраф производительности за потокобезопасность.
Следовательно, система типов и ограничения трейтов Rust гарантируют, что вы никогда не сможете случайно отправить значение Rc<T> между потоками небезопасным образом. Когда мы попытались сделать это в Листинге 16-14, мы получили ошибку the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Когда мы переключились на Arc<T>, который реализует Send, код скомпилировался.
Любой тип, полностью состоящий из типов Send, автоматически помечается как Send. Почти все примитивные типы являются Send, за исключением сырых указателей, которые мы обсудим в Главе 20.
Доступ из нескольких потоков
Трейт-маркер Sync указывает, что для типа, реализующего Sync, безопасно иметь ссылки из нескольких потоков. Другими словами, любой тип T реализует Sync, если &T (неизменяемая ссылка на T) реализует Send, то есть ссылку можно безопасно отправить в другой поток. Подобно Send, все примитивные типы реализуют Sync, и типы, полностью состоящие из типов, которые реализуют Sync, также реализуют Sync.
Умный указатель Rc<T> также не реализует Sync по тем же причинам, по которым он не реализует Send. Тип RefCell<T> (который мы обсуждали в Главе 15) и семейство связанных типов Cell<T> не реализуют Sync. Реализация проверки заимствования, которую RefCell<T> выполняет во время выполнения, не является потокобезопасной. Умный указатель Mutex<T> реализует Sync и может использоваться для совместного доступа с несколькими потоками, как вы видели в разделе «Разделяемый доступ к Mutex<T>».
Ручная реализация Send и Sync небезопасна
Поскольку типы, полностью состоящие из других типов, которые реализуют трейты Send и Sync, также автоматически реализуют Send и Sync, нам не приходится реализовывать эти трейты вручную. Как трейты-маркеры, они даже не имеют никаких методов для реализации. Они просто полезны для обеспечения инвариантов, связанных с конкурентностью.
Ручная реализация этих трейтов включает написание небезопасного кода на Rust. Мы поговорим об использовании небезопасного кода Rust в Главе 20; пока что важная информация заключается в том, что создание новых конкурентных типов, не состоящих из частей Send и Sync, требует тщательного обдумывания для соблюдения гарантий безопасности. «The Rustonomicon» содержит больше информации об этих гарантиях и о том, как их соблюдать.
Итоги
Это не последний раз, когда вы видите конкурентность в этой книге: следующая глава посвящена асинхронному программированию, а проект в Главе 21 будет использовать концепции этой главы в более реалистичной ситуации, чем небольшие примеры, обсуждаемые здесь.
Как упоминалось ранее, поскольку очень малое из того, как Rust обрабатывает конкурентность, является частью языка, многие решения для конкурентности реализованы в виде крейтов. Они развиваются быстрее, чем стандартная библиотека, поэтому обязательно ищите в Интернете современные, передовые крейты для использования в многопоточных ситуациях.
Стандартная библиотека Rust предоставляет каналы для передачи сообщений и типы умных указателей, такие как Mutex<T> и Arc<T>, которые безопасно использовать в конкурентных контекстах. Система типов и проверщик заимствований гарантируют, что код, использующий эти решения, не будет содержать гонок данных или недействительных ссылок. Как только ваш код скомпилируется, вы можете быть уверены, что он будет успешно работать в нескольких потоках без трудноуловимых ошибок, характерных для других языков. Конкурентное программирование больше не является концепцией, которой стоит бояться: вперёд, делайте свои программы конкурентными — бестрашно!
Глава 17
Основы асинхронного программирования: Async, Await, Futures и Streams
Многие операции, которые мы поручаем компьютеру, могут занимать значительное время. Было бы удобно, если бы мы могли делать что-то еще, пока ожидаем завершения этих длительных процессов. Современные компьютеры предлагают две техники для выполнения более одной операции одновременно: параллелизм и конкурентность. Однако логика наших программ записывается в основном линейным образом. Мы хотели бы иметь возможность указывать операции, которые должна выполнить программа, и точки, в которых функция может приостановиться, а другая часть программы может работать вместо нее, без необходимости заранее точно определять порядок и способ выполнения каждого фрагмента кода. Асинхронное программирование — это абстракция, которая позволяет нам выражать наш код в терминах потенциальных точек приостановки и конечных результатов, беря на себя заботу о деталях координации.
Эта глава развивает использование потоков из Главы 16 для параллелизма и конкурентности, представляя альтернативный подход к написанию кода: futures, streams и синтаксис async/await в Rust, которые позволяют нам выражать, как операции могут быть асинхронными, а также сторонние крейты, реализующие асинхронные рантаймы — код, который управляет и координирует выполнение асинхронных операций.
Рассмотрим пример. Допустим, вы экспортируете созданное вами видео семейного праздника — операция, которая может занять от нескольких минут до нескольких часов. Экспорт видео будет использовать максимум мощности CPU и GPU. Если бы у вас было только одно ядро CPU, и ваша операционная система не приостанавливала бы этот экспорт до его завершения — то есть, если бы она выполняла экспорт синхронно — вы не могли бы делать ничего другого на вашем компьютере, пока эта задача выполняется. Это был бы довольно неприятный опыт. К счастью, операционная система вашего компьютера может и действительно невидимо прерывает экспорт достаточно часто, чтобы позволить вам одновременно выполнять другую работу.
Теперь предположим, вы загружаете видео, которым поделился кто-то другой — это тоже может занять некоторое время, но не занимает столько времени CPU. В этом случае CPU должен ждать поступления данных из сети. Хотя вы можете начать читать данные, как только они начнут поступать, может потребоваться некоторое время, чтобы они все прибыли. Даже когда все данные получены, если видео достаточно большое, его загрузка может занять хотя бы секунду или две. Это может показаться незначительным, но для современного процессора, который может выполнять миллиарды операций в секунду, это очень долго. Опять же, ваша операционная система невидимо прервет вашу программу, чтобы позволить CPU выполнять другую работу в ожидании завершения сетевого вызова.
Экспорт видео — пример операции, ограниченной по CPU (compute-bound). Она ограничена потенциальной скоростью обработки данных внутри CPU или GPU и тем, какая часть этой скорости может быть выделена для операции. Загрузка видео — пример операции, ограниченной вводом-выводом (I/O-bound), потому что она ограничена скоростью ввода и вывода компьютера; она может выполняться только так быстро, как данные могут быть переданы по сети.
В обоих этих примерах невидимые прерывания операционной системы обеспечивают форму конкурентности. Однако эта конкурентность происходит только на уровне всей программы: операционная система прерывает одну программу, чтобы позволить другим программам выполнять работу. Во многих случаях, поскольку мы понимаем наши программы на гораздо более детальном уровне, чем операционная система, мы можем заметить возможности для конкурентности, которые ОС увидеть не может.
Например, если мы создаем инструмент для управления загрузкой файлов, мы должны иметь возможность написать нашу программу так, чтобы запуск одной загрузки не блокировал пользовательский интерфейс, и пользователи могли бы запускать несколько загрузок одновременно. Однако многие API операционной системы для взаимодействия с сетью являются блокирующими; то есть они блокируют выполнение программы до тех пор, пока обрабатываемые ими данные не будут полностью готовы.
Примечание: Если задуматься, именно так работают большинство вызовов функций. Однако термин "блокирующий" обычно зарезервирован для вызовов функций, которые взаимодействуют с файлами, сетью или другими ресурсами на компьютере, потому что именно в этих случаях отдельная программа выиграла бы от того, чтобы операция была неблокирующей.
Мы могли бы избежать блокировки нашего основного потока, порождая выделенный поток для загрузки каждого файла. Однако, накладные расходы на системные ресурсы, используемые этими потоками, в конечном итоге стали бы проблемой. Было бы предпочтительнее, если бы вызов изначально не блокировался, и вместо этого мы могли бы определить ряд задач, которые мы хотим, чтобы наша программа выполнила, и позволить рантайму выбрать наилучший порядок и способ их выполнения.
Именно это и дает нам абстракция async (сокращение от asynchronous) в Rust. В этой главе вы узнаете все об async, так как мы рассмотрим следующие темы:
- Как использовать синтаксис async и await в Rust и выполнять асинхронные функции с помощью рантайма.
- Как использовать асинхронную модель для решения некоторых из тех же задач, которые мы рассматривали в Главе 16.
- Как многопоточность и async предлагают взаимодополняющие решения, которые во многих случаях можно комбинировать.
Прежде чем мы увидим, как async работает на практике, нам нужно сделать небольшое отступление, чтобы обсудить различия между параллелизмом и конкурентностью.
Параллелизм и Конкурентность
До сих пор мы рассматривали параллелизм и конкурентность как в основном взаимозаменяемые понятия. Теперь нам нужно точнее разграничить их, поскольку различия проявятся, когда мы начнем работать.
Рассмотрим различные способы, которыми команда могла бы разделить работу над программным проектом. Вы могли бы назначить одному участнику несколько задач, назначить каждому участнику по одной задаче или использовать комбинацию этих двух подходов.
Когда один человек работает над несколькими разными задачами до завершения любой из них, это конкурентность (concurrency). Один из способов реализовать конкурентность похож на то, как если бы у вас на компьютере были открыты два разных проекта, и когда вам наскучило или вы застряли на одном проекте, вы переключаетесь на другой. Вы всего один человек, поэтому не можете одновременно прогрессировать в обеих задачах, но можете работать в режиме многозадачности, продвигаясь по одной задаче за раз, переключаясь между ними (см. Рисунок 17-1).

Рисунок 17-1: Конкурентный рабочий процесс, переключение между Задачей А и Задачей Б
Когда команда разделяет группу задач, поручая каждому участнику по одной задаче для самостоятельной работы, это параллелизм (parallelism). Каждый человек в команде может работать одновременно (см. Рисунок 17-2).

Рисунок 17-2: Параллельный рабочий процесс, где работа над Задачей А и Задачей Б происходит независимо
В обоих этих рабочих процессах вам, возможно, придется координировать действия между разными задачами. Может быть, вы думали, что задача, назначенная одному человеку, полностью независима от работы всех остальных, но на самом деле она требует, чтобы другой человек в команде сначала закончил свою задачу. Часть работы можно было выполнять параллельно, но часть на самом деле была последовательной: ее можно было выполнять только серийно, одна задача за другой, как на Рисунке 17-3.
 Рисунок 17-3: Частично параллельный рабочий процесс, где работа над Задачей А и Задачей Б происходит независимо до тех пор, пока Задача A3 не заблокирована в ожидании результатов Задачи B3.
Рисунок 17-3: Частично параллельный рабочий процесс, где работа над Задачей А и Задачей Б происходит независимо до тех пор, пока Задача A3 не заблокирована в ожидании результатов Задачи B3.
Точно так же вы можете осознать, что одна из ваших собственных задач зависит от другой вашей задачи. Теперь ваша конкурентная работа также стала последовательной.
Параллелизм и конкурентность также могут пересекаться друг с другом. Если вы узнаете, что ваш коллега не может продвигаться, пока вы не закончите одну из своих задач, вы, вероятно, сосредоточите все свои усилия на этой задаче, чтобы "разблокировать" коллегу. Вы и ваш коллега больше не можете работать параллельно, и вы также больше не можете работать конкурентно над своими собственными задачами.
Такая же базовая динамика проявляется в программном и аппаратном обеспечении. На машине с одним ядром CPU процессор может выполнять только одну операцию за раз, но он все равно может работать конкурентно. Используя такие инструменты, как потоки (threads), процессы и async, компьютер может приостановить одну активность и переключиться на другие, прежде чем в конечном итоге вернуться к первой активности. На машине с несколькими ядрами CPU он также может выполнять работу параллельно. Одно ядро может выполнять одну задачу, в то время как другое ядро выполняет совершенно несвязанную задачу, и эти операции фактически происходят одновременно.
Запуск асинхронного кода в Rust обычно происходит конкурентно. В зависимости от оборудования, операционной системы и используемого нами асинхронного рантайма (подробнее о рантаймах чуть позже), эта конкурентность также может использовать параллелизм под капотом.
Теперь давайте углубимся в то, как на самом деле работает асинхронное программирование в Rust.
Основы асинхронного программирования: Async, Await, Futures и Streams
Futures и синтаксис Async
Ключевыми элементами асинхронного программирования в Rust являются futures, а также ключевые слова Rust async и await.
Future (футур) — это значение, которое может быть не готово сейчас, но станет готовым в какой-то момент в будущем. (Этот же концепт встречается во многих языках, иногда под другими названиями, такими как задача (task) или промис (promise).) Rust предозывает типаж Future в качестве строительного блока, чтобы различные асинхронные операции могли быть реализованы с помощью разных структур данных, но с общим интерфейсом. В Rust фьючерсы — это типы, которые реализуют типаж Future. Каждый фьючерс хранит свою собственную информацию о том, какой прогресс был достигнут и что означает "готово".
Вы можете применить ключевое слово async к блокам и функциям, чтобы указать, что их можно приостанавливать и возобновлять. Внутри async-блока или async-функции вы можете использовать ключевое слово .await для ожидания фьючерса (то есть, чтобы дождаться его готовности). Любая точка, в которой вы ожидаете (await) фьючерс внутри async-блока или функции, является потенциальным местом для приостановки и возобновления этого блока или функции. Процесс проверки фьючерса на доступность его значения называется опросом (polling).
В некоторых других языках, таких как C# и JavaScript, также используются ключевые слова async и await для асинхронного программирования. Если вы знакомы с этими языками, вы можете заметить существенные различия в том, как Rust обрабатывает синтаксис. На это есть веские причины, как мы увидим!
При написании асинхронного кода на Rust мы большую часть времени используем ключевые слова async и .await. Rust компилирует их в эквивалентный код, использующий типаж Future, подобно тому, как он компилирует циклы for в эквивалентный код, использующий типаж Iterator. Однако, поскольку Rust предоставляет типаж Future, вы также можете реализовать его для своих собственных типов данных, когда это необходимо. Многие функции, которые мы увидим в этой главе, возвращают типы с их собственными реализациями Future. Мы вернемся к определению этого типажа в конце главы и углубимся в детали его работы, но пока этого достаточно, чтобы двигаться дальше.
Всё это может показаться немного абстрактным, поэтому давайте напишем нашу первую асинхронную программу: небольшой веб-скрапер. Мы передадим два URL-адреса из командной строки, загрузим их оба конкурентно и вернем результат того, который завершится первым. В этом примере будет довольно много нового синтаксиса, но не волнуйтесь — мы объясним всё, что нужно знать, по мере его появления.
Наша первая асинхронная программа
Чтобы сосредоточить внимание этой главы на изучении async, а не на работе с различными частями экосистемы, мы создали крейт trpl (сокращение от "The Rust Programming Language"). Он реэкспортирует все типы, типажи и функции, которые вам понадобятся, в основном из крейтов futures и tokio. Крейт futures — это официальная площадка для экспериментов с асинхронным кодом в Rust, и именно там изначально был разработан типаж Future. Tokio — это наиболее широко используемый асинхронный рантайм в Rust на сегодняшний день, особенно для веб-приложений. Существуют и другие отличные рантаймы, которые могут лучше подходить для ваших целей. Мы используем крейт tokio внутри trpl, потому что он хорошо протестирован и широко используется.
В некоторых случаях trpl также переименовывает или оборачивает оригинальные API, чтобы помочь вам сосредоточиться на деталях, relevantных для этой главы. Если вы хотите понять, что делает этот крейт, мы рекомендуем ознакомиться с его исходным кодом. Вы сможете увидеть, из какого крейта происходит каждый реэкспорт, и мы оставили подробные комментарии, объясняющие, что делает крейт.
Создайте новый бинарный проект с именем hello-async и добавьте крейт trpl в качестве зависимости:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Теперь мы можем использовать различные компоненты, предоставляемые trpl, чтобы написать нашу первую асинхронную программу. Мы создадим небольшой инструмент командной строки, который загружает две веб-страницы, извлекает элемент <title> из каждой и печатает заголовок той страницы, которая первой завершит весь этот процесс.
Определение функции page_title
Давайте начнем с написания функции, которая принимает один URL-адрес страницы в качестве параметра, делает к нему запрос и возвращает текст элемента <title> (см. Листинг 17-1).
Файл: src/main.rs
#![allow(unused)] fn main() { use trpl::Html; async fn page_title(url: &str) -> Option<String> { let response = trpl::get(url).await; let response_text = response.text().await; Html::parse(&response_text) .select_first("title") .map(|title| title.inner_html()) } }
Листинг 17-1: Определение асинхронной функции для получения элемента title из HTML-страницы
Сначала мы определяем функцию с именем page_title и помечаем ее ключевым словом async. Затем мы используем функцию trpl::get для загрузки любого переданного URL-адреса и добавляем ключевое слово .await для ожидания ответа. Чтобы получить текст ответа, мы вызываем его метод text и снова ожидаем его с помощью ключевого слова .await. Оба этих шага являются асинхронными. Для функции get нам приходится ждать, пока сервер отправит обратно первую часть своего ответа, которая будет включать HTTP-заголовки, куки и так далее и может доставляться отдельно от тела ответа. Особенно если тело очень большое, его полная передача может занять некоторое время. Поскольку нам нужно дождаться полного поступления ответа, метод text также является асинхронным.
Нам нужно явно ожидать оба этих фьючерса, потому что фьючерсы в Rust ленивы (lazy): они ничего не делают, пока вы не попросите их об этом с помощью ключевого слова .await. (На самом деле, Rust покажет предупреждение компилятора, если вы не используете фьючерс.) Это может напомнить вам обсуждение итераторов в разделе "Обработка последовательности элементов с помощью итераторов" Главы 13. Итераторы ничего не делают, если вы не вызываете их метод next — напрямую или с помощью циклов for, или методов, таких как map, которые используют next внутри. Точно так же фьючерсы ничего не делают, если вы явно не попросите их об этом. Эта ленивость позволяет Rust избежать выполнения асинхронного кода до тех пор, пока он действительно не понадобится.
Примечание: Это поведение отличается от того, что мы видели при использовании
thread::spawnв разделе "Создание нового потока с помощью spawn" Главы 16, где переданное в другой поток замыкание начинало выполняться немедленно. Это также отличается от подхода ко async во многих других языках. Но это важно для возможности Rust предоставлять свои гарантии производительности, так же, как и в случае с итераторами.
Как только у нас есть response_text, мы можем разобрать его в экземпляр типа Html с помощью Html::parse. Теперь у нас есть тип данных, который мы можем использовать для работы с HTML как с более богатой структурой данных. В частности, мы можем использовать метод select_first, чтобы найти первый экземпляр заданного CSS-селектора. Передав строку "title", мы получим первый элемент <title> в документе, если он есть. Поскольку может не быть ни одного подходящего элемента, select_first возвращает Option<ElementRef>. Наконец, мы используем метод Option::map, который позволяет нам работать с элементом внутри Option, если он присутствует, и ничего не делать, если его нет. (Мы могли бы также использовать здесь выражение match, но map является более идиоматичным.) В теле функции, которую мы передаем в map, мы вызываем inner_html для заголовка, чтобы получить его содержимое, которое имеет тип String. В конечном итоге у нас получается Option<String>.
Обратите внимание, что ключевое слово .await в Rust ставится после выражения, которое вы ожидаете, а не перед ним. То есть, это постфиксное ключевое слово. Это может отличаться от того, к чему вы привыкли, если использовали async в других языках, но в Rust это делает цепочки методов гораздо удобнее. В результате мы могли бы изменить тело page_title, чтобы объединить вызовы функций trpl::get и text вместе с .await между ними, как показано в Листинге 17-2.
Файл: src/main.rs
#![allow(unused)] fn main() { let response_text = trpl::get(url).await.text().await; }
Листинг 17-2: Цепочка вызовов с ключевым словом await
Таким образом, мы успешно написали нашу первую асинхронную функцию! Прежде чем мы добавим код в main для ее вызова, давайте немного поговорим о том, что мы написали и что это означает.
Когда Rust видит блок, помеченный ключевым словом async, он компилирует его в уникальный, анонимный тип данных, который реализует типаж Future. Когда Rust видит функцию, помеченную async, он компилирует ее в не-асинхронную функцию, тело которой представляет собой async-блок. Тип возвращаемого значения асинхронной функции — это тип анонимного типа данных, который компилятор создает для этого async-блока.
Таким образом, написание async fn эквивалентно написанию функции, которая возвращает фьючерс типа возвращаемого значения. Для компилятора определение функции, такое как async fn page_title в Листинге 17-1, примерно эквивалентно не-асинхронной функции, определенной следующим образом:
#![allow(unused)] fn main() { use std::future::Future; use trpl::Html; fn page_title(url: &str) -> impl Future<Output = Option<String>> { async move { let text = trpl::get(url).await.text().await; Html::parse(&text) .select_first("title") .map(|title| title.inner_html()) } } }
Давайте разберем каждую часть преобразованной версии:
- Она использует синтаксис
impl Trait, который мы обсуждали в Главе 10 в разделе "Traits as Parameters". - Возвращаемое значение реализует типаж
Futureс ассоциированным типомOutput. Обратите внимание, что типOutput— этоOption<String>, который совпадает с исходным типом возвращаемого значения из асинхронной версииpage_title. - Весь код, вызываемый в теле исходной функции, обернут в блок
async move. Помните, что блоки являются выражениями. Весь этот блок является выражением, возвращаемым из функции. - Этот
async-блок производит значение с типомOption<String>, как только что было описано. Это значение соответствует типуOutputв возвращаемом типе. Это похоже на другие блоки, которые вы видели. - Новое тело функции представляет собой блок
async moveиз-за того, как оно использует параметрurl. (Мы поговорим гораздо больше оasyncпротивasync moveпозже в этой главе.)
Теперь мы можем вызвать page_title в main.
Выполнение асинхронной функции с помощью рантайма
Для начала мы получим заголовок для одной страницы, как показано в Листинге 17-3. К сожалению, этот код пока не компилируется.
Файл: src/main.rs
// [Этот код не компилируется!] async fn main() { let args: Vec<String> = std::env::args().collect(); let url = &args[1]; match page_title(url).await { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } }
Листинг 17-3: Вызов функции page_title из main с аргументом, предоставленным пользователем
Мы следуем тому же шаблону, который использовали для получения аргументов командной строки в разделе ["Принятие аргументов командной строки"] Главы 12. Затем мы передаем аргумент URL в page_title и ожидаем (await) результат. Поскольку значение, производимое фьючерсом, — это Option<String>, мы используем выражение match для вывода разных сообщений в зависимости от того, была ли у страницы <title>.
Единственное место, где мы можем использовать ключевое слово .await, — это асинхронные функции или блоки, и Rust не позволяет нам пометить специальную функцию main как async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Причина, по которой main не может быть помечена как async, заключается в том, что асинхронному коду нужен рантайм (runtime): крейт Rust, который управляет деталями выполнения асинхронного кода. Функция main программы может инициализировать рантайм, но сама по себе рантаймом не является. (Мы вскоре увидим подробнее, почему это так.) Каждая программа Rust, выполняющая асинхронный код, имеет как минимум одно место, где она настраивает рантайм для выполнения фьючерсов.
В большинстве языков, поддерживающих async, рантайм поставляется в комплекте, но в Rust — нет. Вместо этого доступно множество различных асинхронных рантаймов, каждый из которых предлагает разные компромиссы, подходящие для целевых сценариев использования. Например, высокопроизводительный веб-сервер с множеством ядер CPU и большим объемом оперативной памяти имеет совершенно другие потребности, чем микроконтроллер с одним ядром, небольшим объемом RAM и без возможности выделения памяти в куче. Крейты, предоставляющие эти рантаймы, также часто поставляют асинхронные версии распространенной функциональности, такой как файловый или сетевой ввод-вывод.
Здесь и на протяжении оставшейся части главы мы будем использовать функцию block_on из крейта trpl, которая принимает фьючерс в качестве аргумента и блокирует (blocks) текущий поток до тех пор, пока этот фьючерс не выполнится до конца. За кулисами вызов block_on настраивает рантайм с использованием крейта tokio, который используется для запуска переданного фьючерса (поведение block_on в крейте trpl похоже на функции block_on в других крейтах-рантаймах). Как только фьючерс завершается, block_on возвращает то значение, которое произвел фьючерс.
Мы могли бы передать фьючерс, возвращенный page_title, напрямую в block_on, и, как только он завершится, мы могли бы сопоставить результат Option<String>, как мы пытались сделать в Листинге 17-3. Однако для большинства примеров в этой главе (и для большей части асинхронного кода в реальном мире) мы будем делать больше, чем просто один вызов асинхронной функции, поэтому вместо этого мы передадим асинхронный блок и явно будем ожидать результат вызова page_title, как в Листинге 17-4.
Файл: src/main.rs
fn main() { let args: Vec<String> = std::env::args().collect(); trpl::block_on(async { let url = &args[1]; match page_title(url).await { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } }) }
Листинг 17-4: Ожидание асинхронного блока с помощью trpl::block_on
Когда мы запускаем этот код, мы получаем поведение, которое изначально ожидали:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Фух — у нас наконец-то есть работающий асинхронный код! Но прежде чем мы добавим код для "гонки" двух сайтов друг с другом, давайте ненадолго вернем наше внимание к тому, как работают фьючерсы.
Каждая точка ожидания (await point) — то есть каждое место, где код использует ключевое слово .await — представляет собой место, где управление возвращается рантайму. Чтобы это работало, Rust должен отслеживать состояние, задействованное в асинхронном блоке, чтобы рантайм мог запустить другую работу, а затем вернуться, когда будет готов попытаться продолжить выполнение первой. Это невидимая state machine (state machine), как если бы вы написали перечисление (enum) примерно такого вида, чтобы сохранять текущее состояние в каждой точке ожидания:
#![allow(unused)] fn main() { enum PageTitleFuture<'a> { Initial { url: &'a str }, GetAwaitPoint { url: &'a str }, TextAwaitPoint { response: trpl::Response }, } }
Написание кода для перехода между каждым состоянием вручную было бы утомительным и подверженным ошибкам, особенно когда позже вам потребуется добавить больше функциональности и больше состояний в код. К счастью, компилятор Rust автоматически создает структуры данных для state machine и управляет ими для асинхронного кода. Обычные правила заимствования и владения для структур данных все так же применяются, и, к счастью, компилятор также проверяет их для нас и предоставляет полезные сообщения об ошибках. Мы рассмотрим некоторые из них позже в этой главе.
В конечном счете, что-то должно выполнять эту state machine, и это что-то — рантайм. (Вот почему вы можете встретить упоминания об исполнителях (executors), когда будете изучать рантаймы: исполнитель — это часть рантайма, ответственная за выполнение асинхронного кода.)
Теперь вы понимаете, почему компилятор остановил нас, когда мы попытались сделать саму функцию main асинхронной в Листинге 17-3. Если бы main была асинхронной функцией, что-то другое должно было бы управлять state machine для того фьючерса, который возвращает main, но main — это отправная точка программы! Вместо этого мы вызвали функцию trpl::block_on в main, чтобы настроить рантайм и запустить фьючерс, возвращенный асинхронным блоком, до его завершения.
Примечание: Некоторые рантаймы предоставляют макросы, позволяющие писать асинхронную функцию
main. Эти макросы переписываютasync fn main() { ... }в обычнуюfn main, которая делает то же самое, что мы сделали вручную в Листинге 17-4: вызывает функцию, которая запускает фьючерс до завершения, подобно тому, как это делаетtrpl::block_on.
Теперь давайте соберем эти части вместе и посмотрим, как мы можем писать конкурентный код.
Соревнование двух URL-адресов друг с другом конкурентно
В Листинге 17-5 мы вызываем page_title с двумя разными URL-адресами, переданными из командной строки, и организуем между ними "гонку" (race), выбирая тот фьючерс, который завершится первым.
Файл: src/main.rs
use trpl::{Either, Html}; fn main() { let args: Vec<String> = std::env::args().collect(); trpl::block_on(async { let title_fut_1 = page_title(&args[1]); let title_fut_2 = page_title(&args[2]); let (url, maybe_title) = match trpl::select(title_fut_1, title_fut_2).await { Either::Left(left) => left, Either::Right(right) => right, }; println!("{url} returned first"); match maybe_title { Some(title) => println!("Its page title was: '{title}'"), None => println!("It had no title."), } }) } async fn page_title(url: &str) -> (&str, Option<String>) { let response_text = trpl::get(url).await.text().await; let title = Html::parse(&response_text) .select_first("title") .map(|title| title.inner_html()); (url, title) }
Листинг 17-5: Вызов page_title для двух URL-адресов, чтобы узнать, какой вернется первым
Мы начинаем с вызова page_title для каждого из URL-адресов, предоставленных пользователем. Мы сохраняем результирующие фьючерсы как title_fut_1 и title_fut_2. Помните, они пока ничего не делают, потому что фьючерсы ленивы, и мы еще не начали их ожидать (await). Затем мы передаем эти фьючерсы в trpl::select, которая возвращает значение, указывающее, какой из переданных фьючерсов завершился первым.
Примечание: Внутри
trpl::selectпостроена на основе более общей функцииselect, определенной в крейтеfutures. Функцияselectиз крейтаfuturesможет делать многое из того, что не можетtrpl::select, но она также имеет некоторую дополнительную сложность, которую мы можем пока опустить.
Любой из фьючерсов может законно "победить", поэтому возвращать Result не имеет смысла. Вместо этого trpl::select возвращает тип, который мы раньше не видели, — trpl::Either. Тип Either чем-то похож на Result тем, что имеет два варианта. Однако, в отличие от Result, в Either не заложено понятие успеха или неудачи. Вместо этого он использует Left (Левый) и Right (Правый) для обозначения "тот или другой":
#![allow(unused)] fn main() { enum Either<A, B> { Left(A), Right(B), } }
Функция select возвращает Left с выходным значением этого фьючерса, если побеждает первый аргумент, и Right с выходным значением второго фьючерса, если побеждает он. Это соответствует порядку, в котором аргументы появляются при вызове функции: первый аргумент находится слева от второго.
Мы также обновили page_title, чтобы она возвращала тот же переданный URL. Таким образом, если страница, которая вернулась первой, не имеет <title>, которое мы можем получить, мы все равно можем вывести содержательное сообщение. Имея эту информацию, мы завершаем, обновляя наш вывод println!, чтобы указать и какой URL завершился первым, и какой (если есть) <title> у веб-страницы по этому URL.
Теперь вы создали небольшой работающий веб-скрапер! Выберите пару URL-адресов и запустите инструмент командной строки. Вы можете обнаружить, что некоторые сайты стабильно быстрее других, в то время как в других случаях более быстрый сайт меняется от запуска к запуску. Что более важно, вы изучили основы работы с фьючерсами, так что теперь мы можем глубже погрузиться в то, что мы можем делать с помощью async.
Применение конкурентности с помощью Async
В этом разделе мы применим async к некоторым из тех же задач конкурентности, которые мы решали с помощью потоков в Главе 16. Поскольку мы уже обсуждали там многие ключевые идеи, в этом разделе мы сосредоточимся на том, что отличает потоки от фьючерсов.
Во многих случаях API для работы с конкурентностью с использованием async очень похожи на те, что используются с потоками. В других случаях они оказываются совершенно разными. Даже когда API выглядят похоже между потоками и async, они часто имеют разное поведение — и почти всегда имеют разные характеристики производительности.
Создание новой задачи с помощью spawn_task
Первой операцией, которую мы рассмотрели в разделе ["Создание нового потока с помощью spawn"] Главы 16, был счет на двух отдельных потоках. Давайте сделаем то же самое, используя async. Крейт trpl предоставляет функцию spawn_task, которая очень похожа на API thread::spawn, и функцию sleep, которая является асинхронной версией API thread::sleep. Мы можем использовать их вместе для реализации примера со счетом, как показано в Листинге 17-6.
Файл: src/main.rs
use std::time::Duration; fn main() { trpl::block_on(async { trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }); }
Листинг 17-6: Создание новой задачи для печати одного сообщения, пока основная задача печатает другое
В качестве отправной точки мы настраиваем нашу функцию main с trpl::block_on, чтобы наша функция верхнего уровня могла быть асинхронной.
Примечание: С этого момента и до конца главы каждый пример будет включать один и тот же оборачивающий код с
trpl::block_onвmain, поэтому мы часто будем опускать его, как мы это делаем сmain. Не забудьте включить его в свой код!
Затем мы пишем два цикла внутри этого блока, каждый из которых содержит вызов trpl::sleep, который ждет полсекунды (500 миллисекунд) перед отправкой следующего сообщения. Мы помещаем один цикл в тело trpl::spawn_task, а другой — в цикл for верхнего уровня. Мы также добавляем .await после вызовов sleep.
Этот код ведет себя аналогично реализации на основе потоков — включая тот факт, что в вашем терминале при запуске сообщения могут появляться в другом порядке:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Эта версия останавливается, как только цикл for в теле основного асинхронного блока завершается, потому что задача, порожденная spawn_task, завершается, когда заканчивается функция main. Если вы хотите, чтобы она выполнялась до полного завершения задачи, вам нужно использовать дескриптор присоединения (join handle), чтобы дождаться завершения первой задачи. С потоками мы использовали метод join, чтобы "заблокироваться" до завершения работы потока. В Листинге 17-7 мы можем использовать .await для того же самого, потому что сам дескриптор задачи является фьючерсом. Его ассоциированный тип Output — это Result, поэтому мы также извлекаем из него значение (unwrap) после ожидания.
Файл: src/main.rs
#![allow(unused)] fn main() { let handle = trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } handle.await.unwrap(); }
Листинг 17-7: Использование await с дескриптором присоединения для выполнения задачи до завершения
Эта обновленная версия работает до завершения обоих циклов:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Пока что кажется, что async и потоки дают нам схожие результаты, просто с разным синтаксисом: использование .await вместо вызова join у дескриптора присоединения и ожидание вызовов sleep.
Более важное различие заключается в том, что нам не потребовалось порождать еще один поток операционной системы для этого. На самом деле, нам даже не нужно здесь порождать задачу. Поскольку асинхронные блоки компилируются в анонимные фьючерсы, мы можем поместить каждый цикл в асинхронный блок и заставить рантайм выполнить их оба до завершения с помощью функции trpl::join.
В разделе ["Ожидание завершения всех потоков"] Главы 16 мы показали, как использовать метод join для типа JoinHandle, возвращаемого при вызове std::thread::spawn. Функция trpl::join похожа, но предназначена для фьючерсов. Когда вы передаете ей два фьючерса, она производит один новый фьючерс, выходным значением которого является кортеж, содержащий выходные значения каждого переданного фьючерса после того, как они оба завершатся. Таким образом, в Листинге 17-8 мы используем trpl::join, чтобы дождаться завершения и fut1, и fut2. Мы не ожидаем fut1 и fut2 напрямую, а вместо этого ожидаем новый фьючерс, созданный trpl::join. Мы игнорируем выходное значение, потому что это просто кортеж, содержащий два значения unit-типа ().
Файл: src/main.rs
#![allow(unused)] fn main() { let fut1 = async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }; let fut2 = async { for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }; trpl::join(fut1, fut2).await; }
Листинг 17-8: Использование trpl::join для ожидания двух анонимных фьючерсов
При запуске мы видим, что оба фьючерса выполняются до завершения:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Теперь вы будете видеть один и тот же порядок каждый раз, что сильно отличается от того, что мы видели с потоками и с trpl::spawn_task в Листинге 17-7. Это потому, что функция trpl::join является честной (fair), что означает, что она проверяет каждый фьючерс одинаково часто, чередуя их, и никогда не позволяет одному уйти далеко вперед, если другой готов к выполнению. В случае с потоками операционная система решает, какой поток проверять и как долго позволять ему работать. В асинхронном Rust рантайм решает, какую задачу проверять. (На практике детали усложняются, потому что асинхронный рантайм может использовать потоки операционной системы внутри себя как часть управления конкурентностью, поэтому гарантировать честность может быть сложнее для рантайма — но это все равно возможно!) Рантаймы не обязаны гарантировать честность для любой конкретной операции, и они часто предлагают разные API, позволяющие вам выбирать, нужна вам честность или нет.
Попробуйте некоторые из этих вариантов ожидания фьючерсов и посмотрите, что они делают:
- Уберите асинхронный блок из одного или обоих циклов.
- Ожидайте каждый асинхронный блок сразу после его определения.
- Оберните только первый цикл в асинхронный блок и ожидайте результирующий фьючерс после тела второго цикла.
Для дополнительного испытания попробуйте догадаться, каким будет вывод в каждом случае, прежде чем запускать код!
Передача данных между двумя задачами с помощью обмена сообщениями
Совместное использование данных между фьючерсами также будет знакомым: мы снова воспользуемся передачей сообщений, но на этот раз с асинхронными версиями типов и функций. Мы пойдем немного другим путем, чем в разделе ["Передача данных между потоками с помощью обмена сообщениями"] Главы 16, чтобы проиллюстрировать некоторые ключевые различия между конкурентностью на основе потоков и на основе фьючерсов. В Листинге 17-9 мы начнем с одного асинхронного блока — не порождая отдельную задачу, как мы порождали отдельный поток.
Файл: src/main.rs
#![allow(unused)] fn main() { let (tx, mut rx) = trpl::channel(); let val = String::from("hi"); tx.send(val).unwrap(); let received = rx.recv().await.unwrap(); println!("received '{received}'"); }
Листинг 17-9: Создание асинхронного канала и назначение двух его половин tx и rx
Здесь мы используем trpl::channel — асинхронную версию API канала с несколькими производителями и одним потребителем (multiple-producer, single-consumer), который мы использовали с потоками в Главе 16. Асинхронная версия API лишь немного отличается от версии на основе потоков: она использует изменяемый (mut), а не неизменяемый приемник rx, и ее метод recv производит фьючерс, который нам нужно ожидать (await), а не производит значение напрямую. Теперь мы можем отправлять сообщения от отправителя к получателю. Обратите внимание, что нам не нужно порождать отдельный поток или даже задачу; нам просто нужно ожидать вызов rx.recv.
Синхронный метод Receiver::recv в std::mpsc::channel блокируется, пока не получит сообщение. Метод trpl::Receiver::recv так не делает, потому что он асинхронный. Вместо блокировки он возвращает управление рантайму до тех пор, пока либо не будет получено сообщение, либо отправляющая сторона канала не закроется. Напротив, мы не ожидаем вызов send, потому что он не блокирующий. Ему и не нужно блокироваться, потому что канал, в который мы отправляем, является неограниченным (unbounded).
Примечание: Поскольку весь этот асинхронный код выполняется в асинхронном блоке внутри вызова
trpl::block_on, всё внутри него может избегать блокировки. Однако код снаружи будет блокироваться на возврате из функцииblock_on. В этом и состоит вся суть функцииtrpl::block_on: она позволяет вам выбрать, где блокироваться на некотором наборе асинхронного кода и, следовательно, где происходит переход между синхронным и асинхронным кодом.
Обратите внимание на две вещи в этом примере. Во-первых, сообщение придет сразу. Во-вторых, хотя мы используем здесь фьючерс, конкурентности пока нет. Все в листинге происходит последовательно, точно так же, как если бы фьючерсов не было вовсе.
Давайте решим первую часть, отправив серию сообщений и делая паузы между ними, как показано в Листинге 17-10.
Файл: src/main.rs
#![allow(unused)] fn main() { let (tx, mut rx) = trpl::channel(); let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } while let Some(value) = rx.recv().await { println!("received '{value}'"); } }
Листинг 17-10: Отправка и получение нескольких сообщений через асинхронный канал и ожидание с помощью await между каждым сообщением
В дополнение к отправке сообщений нам нужно их получать. В данном случае, поскольку мы знаем, сколько сообщений придет, мы могли бы сделать это вручную, вызвав rx.recv().await четыре раза. Однако в реальном мире мы обычно будем ожидать неизвестное количество сообщений, поэтому нам нужно продолжать ждать, пока мы не определим, что сообщений больше нет.
В Листинге 16-10 мы использовали цикл for для обработки всех элементов, полученных из синхронного канала. Однако в Rust пока нет возможности использовать цикл for с асинхронно производимой серией элементов, поэтому нам нужно использовать цикл, который мы раньше не видели: условный цикл while let. Это цикловая версия конструкции if let, которую мы видели в разделе ["Краткий поток управления с if let и let else"] Главы 6. Цикл будет продолжать выполняться до тех пор, пока указанный в нем шаблон продолжает соответствовать значению.
Вызов rx.recv производит фьючерс, который мы ожидаем (await). Рантайм приостановит выполнение этого фьючерса, пока он не будет готов. Как только сообщение arrives, фьючерс будет разрешаться в Some(message) столько раз, сколько сообщений придет. Когда канал закроется, независимо от того, поступали ли сообщения, фьючерс вместо этого разрешится в None, указывая, что больше значений нет и, следовательно, нам следует прекратить опрос (polling) — то есть прекратить ожидание (await).
Цикл while let объединяет всё это вместе. Если результат вызова rx.recv().await — это Some(message), мы получаем доступ к сообщению и можем использовать его в теле цикла, точно так же, как с if let. Если результат None, цикл завершается. Каждый раз, когда цикл завершается, он снова достигает точки ожидания (await point), поэтому рантайм снова приостанавливает его до прибытия следующего сообщения.
Теперь код успешно отправляет и получает все сообщения. К сожалению, осталась пара проблем. Во-первых, сообщения не приходят с интервалом в полсекунды. Они приходят все сразу, через 2 секунды (2000 миллисекунд) после запуска программы. Во-вторых, эта программа также никогда не завершается! Вместо этого она ждет новые сообщения вечно. Вам нужно будет завершить ее с помощью Ctrl-C.
Код внутри одного асинхронного блока выполняется линейно
Давайте начнем с того, чтобы выяснить, почему сообщения приходят все сразу после полной задержки, а не с задержками между каждым. Внутри данного асинхронного блока порядок, в котором ключевые слова .await появляются в коде, также является порядком их выполнения при запуске программы.
В Листинге 17-10 есть только один асинхронный блок, поэтому всё в нем выполняется линейно. Конкурентности по-прежнему нет. Все вызовы tx.send происходят, перемежаясь со всеми вызовами trpl::sleep и их соответствующими точками ожидания (await points). Только после этого цикл while let получает возможность пройти через какие-либо точки ожидания для вызовов recv.
Чтобы добиться желаемого поведения, при котором задержка sleep происходит между каждым сообщением, нам нужно поместить операции tx и rx в их собственные асинхронные блоки, как показано в Листинге 17-11. Тогда рантайм сможет выполнять каждый из них отдельно с помощью trpl::join, как в Листинге 17-8. Еще раз: мы ожидаем результат вызова trpl::join, а не отдельные фьючерсы. Если бы мы ожидали отдельные фьючерсы последовательно, мы бы просто вернулись к последовательному потоку — именно то, чего мы пытаемся избежать.
Файл: src/main.rs
#![allow(unused)] fn main() { let (tx, mut rx) = trpl::channel(); let tx_fut = async { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; trpl::join(tx_fut, rx_fut).await; }
Листинг 17-11: Разделение отправки и получения в собственные асинхронные блоки и ожидание фьючерсов для этих блоков
С обновленным кодом из Листинга 17-11 сообщения печатаются с интервалом в 500 миллисекунд, а не все сразу через 2 секунды.
Перемещение владения в асинхронный блок
Однако программа по-прежнему никогда не завершается из-за того, как цикл while let взаимодействует с trpl::join:
- Фьючерс, возвращенный из
trpl::join, завершается только тогда, когда оба переданных ему фьючерса завершены. - Фьючерс
tx_futзавершается, как только он заканчивает ожидание после отправки последнего сообщения вvals. - Фьючерс
rx_futне завершится, пока не закончится циклwhile let. - Цикл
while letне закончится, пока ожиданиеrx.recvне дастNone. - Ожидание
rx.recvвернетNoneтолько тогда, когда другой конец канала закроется. - Канал закроется только если мы вызовем
rx.closeили когда отправляющая сторона,tx, будет удалена (dropped). - Мы нигде не вызываем
rx.close, аtxне будет удалена до тех пор, пока не завершится самый внешний асинхронный блок, переданный вtrpl::block_on. - Блок не может завершиться, потому что он заблокирован на завершении
trpl::join, что возвращает нас к началу этого списка.
Сейчас асинхронный блок, в котором мы отправляем сообщения, только заимствует (borrows) tx, потому что отправка сообщения не требует владения. Но если бы мы могли переместить (move) tx в этот асинхронный блок, он был бы удален, как только этот блок завершится. В разделе ["Захват ссылок или перемещение владения"] Главы 13 вы узнали, как использовать ключевое слово move с замыканиями, и, как обсуждалось в разделе ["Использование замыканий move с потоками"] Главы 16, нам часто нужно перемещать данные в замыкания при работе с потоками. Та же базовая динамика применима к асинхронным блокам, поэтому ключевое слово move работает с асинхронными блоками так же, как и с замыканиями.
В Листинге 17-12 мы изменяем блок, используемый для отправки сообщений, с async на async move.
Файл: src/main.rs
#![allow(unused)] fn main() { let (tx, mut rx) = trpl::channel(); let tx_fut = async move { // --snip-- }
Листинг 17-12: Пересмотренная версия кода из Листинга 17-11, которая корректно завершается после выполнения
Когда мы запускаем эту версию кода, она корректно завершается после отправки и получения последнего сообщения. Далее давайте посмотрим, что нужно изменить, чтобы отправлять данные из более чем одного фьючерса.
Объединение нескольких фьючерсов с помощью макроса join!
Этот асинхронный канал также является каналом с несколькими производителями, поэтому мы можем вызвать clone на tx, если хотим отправлять сообщения из нескольких фьючерсов, как показано в Листинге 17-13.
Файл: src/main.rs
#![allow(unused)] fn main() { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; let tx_fut = async move { let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(1500)).await; } }; trpl::join!(tx1_fut, tx_fut, rx_fut); }
Листинг 17-13: Использование нескольких производителей с асинхронными блоками
Сначала мы клонируем tx, создавая tx1 вне первого асинхронного блока. Мы перемещаем tx1 в этот блок так же, как делали это ранее с tx. Затем, позже, мы перемещаем оригинальный tx в новый асинхронный блок, где отправляем больше сообщений с немного более медленной задержкой. Мы размещаем этот новый асинхронный блок после блока для приема сообщений, но он с тем же успехом мог бы быть и до него. Ключевым моментом является порядок, в котором ожидаются фьючерсы, а не порядок их создания.
Оба асинхронных блока для отправки сообщений должны быть блоками async move, чтобы и tx, и tx1 были удалены (dropped) при завершении этих блоков. В противном случае мы снова окажемся в том же бесконечном цикле, с которого начинали.
Наконец, мы переходим от trpl::join к trpl::join!, чтобы обработать дополнительный фьючерс: макрос join! ожидает произвольное количество фьючерсов, когда мы знаем их количество на этапе компиляции. Мы обсудим ожидание коллекции из неизвестного числа фьючерсов позже в этой главе.
Теперь мы видим все сообщения от обоих отправляющих фьючерсов, и, поскольку отправляющие фьючерсы используют немного разные задержки после отправки, сообщения также принимаются с этими разными интервалами:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Мы исследовали, как использовать передачу сообщений для отправки данных между фьючерсами, как код внутри асинхронного блока выполняется последовательно, как переместить владение в асинхронный блок и как объединить несколько фьючерсов. Далее давайте обсудим, как и зачем сообщать рантайму, что он может переключиться на другую задачу.
Возврат управления рантайму
Вспомните из раздела ["Наша первая асинхронная программа"], что в каждой точке ожидания (await point) Rust дает рантайму возможность приостановить задачу и переключиться на другую, если ожидаемый фьючерс еще не готов. Верно и обратное: Rust приостанавливает асинхронные блоки и возвращает управление рантайму только в точках ожидания. Всё, что находится между точками ожидания, выполняется синхронно.
Это означает, что если вы выполняете много работы в асинхронном блоке без точек ожидания, этот фьючерс будет блокировать прогресс любых других фьючерсов. Вы можете иногда слышать, что это называют ситуацией, когда один фьючерс "морит голодом" (starving) другие фьючерсы. В некоторых случаях это может быть не страшно. Однако если вы выполняете какое-то ресурсоемкое начальное действие или длительную работу, или если у вас есть фьючерс, который будет постоянно выполнять какую-то определенную задачу, вам нужно подумать о том, когда и где возвращать управление рантайму.
Давайте смоделируем длительную операцию, чтобы проиллюстрировать проблему "голодания", а затем исследуем, как ее решить. В Листинге 17-14 представлена функция slow.
Файл: src/main.rs
#![allow(unused)] fn main() { fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); } }
Листинг 17-14: Использование thread::sleep для имитации медленных операций
Этот код использует std::thread::sleep вместо trpl::sleep, поэтому вызов slow будет блокировать текущий поток на некоторое количество миллисекунд. Мы можем использовать slow для имитации реальных операций, которые являются одновременно длительными и блокирующими.
В Листинге 17-15 мы используем slow, чтобы сымитировать выполнение такой работы, ограниченной по CPU, в паре фьючерсов.
Файл: src/main.rs
#![allow(unused)] fn main() { let a = async { println!("'a' started."); slow("a", 30); slow("a", 10); slow("a", 20); trpl::sleep(Duration::from_millis(50)).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); slow("b", 10); slow("b", 15); slow("b", 350); trpl::sleep(Duration::from_millis(50)).await; println!("'b' finished."); }; trpl::select(a, b).await; }
Листинг 17-15: Вызов slow для имитации выполнения медленных операций
Каждый фьючерс возвращает управление рантайму только после выполнения целой серии медленных операций. Если вы запустите этот код, вы увидите такой вывод:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Как и в Листинге 17-5, где мы использовали trpl::select для "гонки" фьючерсов, загружающих два URL, select все равно завершается, как только a готов. Однако между вызовами slow в двух фьючерсах нет чередования. Фьючерс a выполняет всю свою работу до тех пор, пока не будет достигнут вызов trpl::sleep, затем фьючерс b выполняет всю свою работу до тех пор, пока не будет достигнут его собственный вызов trpl::sleep, и, наконец, фьючерс a завершается. Чтобы позволить обоим фьючерсам прогрессировать между их медленными задачами, нам нужны точки ожидания, чтобы мы могли вернуть управление рантайму. Это означает, что нам нужно что-то, что мы можем ожидать (await)!
Мы уже видим, что такая передача управления происходит в Листинге 17-15: если бы мы убрали trpl::sleep в конце фьючерса a, он бы завершился, а фьючерс b вообще не запустился бы. Давайте попробуем использовать функцию trpl::sleep в качестве отправной точки для того, чтобы позволить операциям поочередно прогрессировать, как показано в Листинге 17-16.
Файл: src/main.rs
#![allow(unused)] fn main() { let one_ms = Duration::from_millis(1); let a = async { println!("'a' started."); slow("a", 30); trpl::sleep(one_ms).await; slow("a", 10); trpl::sleep(one_ms).await; slow("a", 20); trpl::sleep(one_ms).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::sleep(one_ms).await; slow("b", 10); trpl::sleep(one_ms).await; slow("b", 15); trpl::sleep(one_ms).await; slow("b", 350); trpl::sleep(one_ms).await; println!("'b' finished."); }; }
Листинг 17-16: Использование trpl::sleep для того, чтобы позволить операциям поочередно прогрессировать
Мы добавили вызовы trpl::sleep с точками ожидания между каждым вызовом slow. Теперь работа двух фьючерсов чередуется:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
Фьючерс a все еще работает некоторое время, прежде чем передать управление b, потому что он вызывает slow до любого вызова trpl::sleep, но после этого фьючерсы меняются местами каждый раз, когда один из них достигает точки ожидания. В данном случае мы сделали это после каждого вызова slow, но мы могли бы разбить работу любым способом, который имеет для нас наибольший смысл.
Однако на самом деле мы не хотим "спать" здесь: мы хотим прогрессировать как можно быстрее. Нам просто нужно вернуть управление рантайму. Мы можем сделать это напрямую, используя функцию trpl::yield_now. В Листинге 17-17 мы заменяем все эти вызовы trpl::sleep на trpl::yield_now.
Файл: src/main.rs
#![allow(unused)] fn main() { let a = async { println!("'a' started."); slow("a", 30); trpl::yield_now().await; slow("a", 10); trpl::yield_now().await; slow("a", 20); trpl::yield_now().await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::yield_now().await; slow("b", 10); trpl::yield_now().await; slow("b", 15); trpl::yield_now().await; slow("b", 350); trpl::yield_now().await; println!("'b' finished."); }; }
Листинг 17-17: Использование yield_now для того, чтобы позволить операциям поочередно прогрессировать
Этот код более четко отражает фактическое намерение и может быть значительно быстрее, чем использование sleep, потому что таймеры, такие как тот, что используется в sleep, часто имеют ограничения на свою точность. Версия sleep, которую мы используем, например, всегда будет "спать" как минимум миллисекунду, даже если мы передадим ей Duration в одну наносекунду. Повторим: современные компьютеры быстры — они могут сделать очень многое за одну миллисекунду!
Это означает, что async может быть полезен даже для задач, ограниченных по CPU, в зависимости от того, что еще делает ваша программа, потому что он предоставляет полезный инструмент для структурирования отношений между различными частями программы (но ценой накладных расходов на асинхронную state machine). Это форма кооперативной многозадачности (cooperative multitasking), где каждый фьючерс имеет возможность определять, когда он передает управление через точки ожидания. Следовательно, каждый фьючерс также несет ответственность за то, чтобы избегать блокировки на слишком долгое время. В некоторых встраиваемых (embedded) операционных системах на основе Rust это единственный вид многозадачности!
В реальном коде вы, конечно, обычно не будете чередовать вызовы функций с точками ожидания в каждой строке. Хотя передача управления таким образом относительно недорога, она не бесплатна. Во многих случаях попытка разбить задачу, ограниченную по CPU, может сделать ее значительно медленнее, поэтому иногда для общей производительности лучше позволить операции ненадолго заблокироваться. Всегда проводите замеры, чтобы увидеть, каковы реальные узкие места производительности вашего кода. Однако лежащая в основе динамика важна, и о ней стоит помнить, если вы видите, что много работы выполняется последовательно, хотя вы ожидали, что она будет выполняться конкурентно!
Создание наших собственных асинхронных абстракций
Мы также можем комбинировать фьючерсы вместе для создания новых паттернов. Например, мы можем построить функцию timeout с помощью уже имеющихся асинхронных строительных блоков. Когда мы закончим, результатом будет еще один строительный блок, который мы могли бы использовать для создания еще более сложных асинхронных абстракций.
Листинг 17-18 показывает, как мы ожидаем, что этот timeout будет работать с медленным фьючерсом.
Файл: src/main.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }
Листинг 17-18: Использование нашей воображаемой функции timeout для выполнения медленной операции с ограничением по времени
Давайте реализуем это! Для начала давайте подумаем об API для timeout:
- Она сама должна быть асинхронной функцией, чтобы мы могли ее ожидать (await).
- Ее первый параметр должен быть фьючерсом для выполнения. Мы можем сделать его обобщенным (generic), чтобы он работал с любым фьючерсом.
- Ее второй параметр — это максимальное время ожидания. Если мы используем
Duration, это упростит передачу вtrpl::sleep. - Она должна возвращать
Result. Если фьючерс завершается успешно,ResultбудетOkсо значением, произведенным фьючерсом. Если сначала истекает таймаут,ResultбудетErrс длительностью (duration), которую таймаут ожидал.
Листинг 17-19 показывает это объявление.
Файл: src/main.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { // Здесь будет наша реализация! } }
Листинг 17-19: Определение сигнатуры функции timeout
Это удовлетворяет нашим целям для типов. Теперь давайте подумаем о поведении, которое нам нужно: мы хотим устроить "гонку" между переданным фьючерсом и длительностью. Мы можем использовать trpl::sleep, чтобы создать фьючерс-таймер из длительности, и использовать trpl::select, чтобы запустить этот таймер вместе с фьючерсом, переданным вызывающей стороной.
В Листинге 17-20 мы реализуем timeout, сопоставляя результат ожидания trpl::select.
Файл: src/main.rs
#![allow(unused)] fn main() { use trpl::Either; // --snip-- async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { match trpl::select(future_to_try, trpl::sleep(max_time)).await { Either::Left(output) => Ok(output), Either::Right(_) => Err(max_time), } } }
Листинг 17-20: Определение timeout с помощью select и sleep
Реализация trpl::select не является честной (fair): она всегда опрашивает (polls) аргументы в том порядке, в котором они переданы (другие реализации select могут случайным образом выбирать, какой аргумент опрашивать первым). Таким образом, мы передаем future_to_try в select первым, чтобы у него был шанс завершиться, даже если max_time — очень короткая длительность. Если future_to_try завершится первым, select вернет Left с выходным значением от future_to_try. Если таймер завершится первым, select вернет Right с выходным значением таймера ().
Если future_to_try успешен, и мы получаем Left(output), мы возвращаем Ok(output). Если вместо этого истекает таймер сна sleep, и мы получаем Right(()), мы игнорируем () с помощью _ и возвращаем Err(max_time).
Таким образом, у нас есть работающий timeout, построенный из двух других асинхронных помощников. Если мы запустим наш код, он выведет сообщение об ошибке после таймаута:
Failed after 2 seconds
Поскольку фьючерсы комбинируются с другими фьючерсами, вы можете строить действительно мощные инструменты, используя меньшие асинхронные строительные блоки. Например, вы можете использовать этот же подход, чтобы комбинировать таймауты с повторными попытками (retries), и, в свою очередь, использовать их с такими операциями, как сетевые вызовы (как те, что в Листинге 17-5).
На практике вы обычно будете работать напрямую с async и await, а во вторую очередь — с такими функциями, как select, и макросами, такими как join!, чтобы контролировать, как выполняются самые внешние фьючерсы.
Мы рассмотрели несколько способов работы с несколькими фьючерсами одновременно. Далее мы посмотрим, как мы можем работать с несколькими фьючерсами в последовательности с течением времени с помощью потоков (streams).
Потоки (Streams): Фьючерсы в последовательности
Вспомните, как мы использовали получатель (receiver) для нашего асинхронного канала ранее в этой главе в разделе "Передача сообщений". Асинхронный метод recv производит последовательность элементов с течением времени. Это экземпляр гораздо более общего паттерна, известного как поток (stream). Многие концепции естественным образом представляются в виде потоков: элементы, становящиеся доступными в очереди; части данных, постепенно загружаемые из файловой системы, когда полный набор данных слишком велик для памяти компьютера; или данные, поступающие по сети с течением времени. Поскольку потоки являются фьючерсами, мы можем использовать их с любым другим типом фьючерсов и комбинировать их интересными способами. Например, мы можем группировать события в пакеты, чтобы избежать слишком частых сетевых вызовов, устанавливать таймауты для последовательностей длительных операций или регулировать (throttle) события пользовательского интерфейса, чтобы избежать ненужной работы.
Мы видели последовательность элементов в Главе 13, когда рассматривали типаж Iterator в разделе ["Типаж Iterator и метод next"], но между итераторами и получателем асинхронного канала есть два различия. Первое различие — это время: итераторы являются синхронными, а получатель канала — асинхронным. Второе различие — это API. При работе напрямую с Iterator мы вызываем его синхронный метод next. В случае же с потоком trpl::Receiver мы вызывали асинхронный метод recv. В остальном эти API кажутся очень похожими, и это сходство не случайно. Поток похож на асинхронную форму итерации. Однако в то время как trpl::Receiver конкретно ожидает получения сообщений, API потока общего назначения гораздо шире: он предоставляет следующий элемент, как это делает Iterator, но асинхронно.
Сходство между итераторами и потоками в Rust означает, что мы фактически можем создать поток из любого итератора. Как и с итератором, мы можем работать с потоком, вызывая его метод next, а затем ожидая (await) выходное значение, как в Листинге 17-21, который пока не компилируется.
Файл: src/main.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let iter = values.iter().map(|n| n * 2); let mut stream = trpl::stream_from_iter(iter); while let Some(value) = stream.next().await { println!("The value was: {value}"); } }
Листинг 17-21: Создание потока из итератора и вывод его значений
Мы начинаем с массива чисел, который преобразуем в итератор, а затем вызываем map, чтобы удвоить все значения. Затем мы преобразуем итератор в поток с помощью функции trpl::stream_from_iter. Далее мы перебираем элементы в потоке по мере их поступления с помощью цикла while let.
К сожалению, при попытке запустить код он не компилируется и вместо этого сообщает, что метод next недоступен:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Как объясняется в этом выводе, причина ошибки компилятора в том, что нам нужен соответствующий типаж в области видимости, чтобы использовать метод next. Учитывая наше обсуждение, вы могли бы разумно предположить, что этим типажом является Stream, но на самом деле это StreamExt. Сокращение от extension (расширение), Ext — это распространенный паттерн в сообществе Rust для расширения одного типажа другим.
Типаж Stream определяет низкоуровневый интерфейс, который фактически объединяет типажи Iterator и Future. StreamExt предоставляет набор API более высокого уровня поверх Stream, включая метод next, а также другие вспомогательные методы, подобные тем, что предоставляются типажом Iterator. Stream и StreamExt пока не являются частью стандартной библиотеки Rust, но большинство крейтов экосистемы используют похожие определения.
Исправление ошибки компилятора заключается в добавлении оператора use для trpl::StreamExt, как в Листинге 17-22.
Файл: src/main.rs
use trpl::StreamExt; fn main() { trpl::block_on(async { let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // --snip--
Листинг 17-22: Успешное использование итератора в качестве основы для потока
Когда все эти части собраны вместе, этот код работает так, как мы хотим! Более того, теперь, когда StreamExt находится в области видимости, мы можем использовать все его вспомогательные методы, так же как и с итераторами.
Более детальный взгляд на типажи для Async
На протяжении всей главы мы использовали типажи Future, Stream и StreamExt различными способами. Однако до сих пор мы избегали слишком глубокого погружения в детали их работы или того, как они сочетаются друг с другом, и в большинстве случаев этого достаточно для вашей повседневной работы с Rust. Но иногда вы столкнетесь с ситуациями, когда вам потребуется понять немного больше деталей об этих типажах, а также о типе Pin и типаже Unpin. В этом разделе мы углубимся ровно настолько, чтобы помочь в таких сценариях, оставив действительно глубокое погружение для другой документации.
Типаж Future
Давайте начнем с более пристального взгляда на то, как работает типаж Future. Вот как Rust определяет его:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Это определение типажа включает кучу новых типов, а также некоторый синтаксис, который мы раньше не видели, так что давайте разберем определение по частям.
Во-первых, ассоциированный тип Output указывает, во что разрешается (resolves) фьючерс. Это аналогично ассоциированному типу Item для типажа Iterator. Во-вторых, у Future есть метод poll, который принимает специальную ссылку Pin для своего параметра self и изменяемую ссылку на тип Context, и возвращает Poll<Self::Output>. Мы поговорим больше о Pin и Context чуть позже. А сейчас давайте сосредоточимся на том, что возвращает метод, — на типе Poll:
#![allow(unused)] fn main() { pub enum Poll<T> { Ready(T), Pending, } }
Этот тип Poll похож на Option. У него есть один вариант со значением, Ready(T), и один без значения, Pending. Однако Poll означает нечто совершенно иное, чем Option! Вариант Pending указывает, что фьючерс все еще выполняет работу, поэтому вызывающей стороне нужно будет проверить снова позже. Вариант Ready указывает, что Future завершил свою работу и значение T доступно.
Примечание: Редко возникает необходимость вызывать
pollнапрямую, но если она есть, имейте в виду, что для большинства фьючерсов вызывающая сторона не должна вызыватьpollснова после того, как фьючерс вернулReady. Многие фьючерсы вызовут панику (panic), если их опрашивать снова после готовности. Фьючерсы, которые безопасно опрашивать повторно, явно скажут об этом в своей документации. Это похоже на поведениеIterator::next.
Когда вы видите код, использующий .await, Rust компилирует его под капотом в код, который вызывает poll. Если вы посмотрите на Листинг 17-4, где мы выводили заголовок страницы для одного URL-адреса после его разрешения, Rust компилирует это во что-то вроде (хотя и не совсем) такого:
#![allow(unused)] fn main() { match page_title(url).poll() { Ready(page_title) => match page_title { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } Pending => { // Но что здесь должно быть? } } }
Что нам делать, когда фьючерс все еще Pending? Нам нужен какой-то способ пытаться снова, и снова, и снова, пока фьючерс наконец не будет готов. Другими словами, нам нужен цикл:
#![allow(unused)] fn main() { let mut page_title_fut = page_title(url); loop { match page_title_fut.poll() { Ready(value) => match page_title { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } Pending => { // continue } } } }
Однако, если бы Rust компилировал это в точности в такой код, каждый .await был бы блокирующим — прямо противоположно тому, чего мы добивались! Вместо этого Rust обеспечивает, чтобы цикл мог передать управление чему-то, что может приостановить работу над этим фьючерсом, чтобы работать над другими фьючерсами, а затем проверить этот снова позже. Как мы видели, этим "чем-то" является асинхронный рантайм, и эта работа по планированию и координации — одна из его основных задач.
В разделе ["Передача данных между двумя задачами с помощью обмена сообщениями"] мы описывали ожидание rx.recv. Вызов recv возвращает фьючерс, и ожидание (await) этого фьючерса опрашивает (polls) его. Мы отметили, что рантайм приостановит выполнение фьючерса, пока он не будет готов с либо Some(message), либо None (когда канал закроется). С нашим более глубоким пониманием типажа Future и, в частности, Future::poll, мы можем видеть, как это работает. Рантайм знает, что фьючерс не готов, когда он возвращает Poll::Pending. И наоборот, рантайм знает, что фьючерс готов, и продвигает его, когда poll возвращает Poll::Ready(Some(message)) или Poll::Ready(None).
Точные детали того, как рантайм это делает, выходят за рамки этой книги, но ключевой момент — увидеть базовую механику фьючерсов: рантайм опрашивает каждый фьючерс, за который он отвечает, и снова "усыпляет" фьючерс, когда он еще не готов.
Тип Pin и типаж Unpin
Вернемся к Листингу 17-13, где мы использовали макрос trpl::join! для ожидания трех фьючерсов. Однако часто бывает, что есть коллекция, например вектор, содержащая некоторое количество фьючерсов, которое не будет известно до времени выполнения. Давайте изменим Листинг 17-13 на код в Листинге 17-23, который помещает три фьючерса в вектор и вместо этого вызывает функцию trpl::join_all, который пока не компилируется.
Файл: src/main.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] let tx_fut = async move { // --snip-- }; let futures: Vec<Box<dyn Future<Output = ()>>> = vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)]; trpl::join_all(futures).await; }
Листинг 17-23: Ожидание фьючерсов в коллекции
Мы помещаем каждый фьючерс в Box, чтобы превратить их в трейт-объекты, точно так же, как мы делали в разделе ["Возврат ошибок из run"] Главы 12. (Мы подробно рассмотрим трейт-объекты в Главе 18.) Использование трейт-объектов позволяет нам рассматривать каждый из анонимных фьючерсов, созданных этими типами, как один и тот же тип, потому что все они реализуют типаж Future.
Это может быть удивительно. В конце концов, ни один из асинхронных блоков ничего не возвращает, поэтому каждый производит Future<Output = ()>. Однако помните, что Future — это типаж, и компилятор создает уникальное перечисление (enum) для каждого асинхронного блока, даже если они имеют идентичные типы выходных данных. Так же как вы не можете поместить две разные структуры, написанные вручную, в Vec, вы не можете смешивать сгенерированные компилятором перечисления.
Затем мы передаем коллекцию фьючерсов в функцию trpl::join_all и ожидаем результат. Однако это не компилируется; вот соответствующая часть сообщений об ошибках.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
Примечание в этом сообщении об ошибке говорит нам, что мы должны использовать макрос pin!, чтобы закрепить (pin) значения, что означает поместить их внутрь типа Pin, который гарантирует, что значения не будут перемещены в памяти. Сообщение об ошибке говорит, что закрепление требуется, потому что dyn Future<Output = ()> должен реализовать типаж Unpin, а в настоящее время он этого не делает.
Функция trpl::join_all возвращает структуру с именем JoinAll. Эта структура обобщена (generic) по типу F, который ограничен (constrained) необходимостью реализовывать типаж Future. Прямое ожидание фьючерса с помощью .await неявно закрепляет (pins) фьючерс. Вот почему нам не нужно использовать pin! везде, где мы хотим ожидать фьючерсы.
Однако здесь мы не ожидаем фьючерс напрямую. Вместо этого мы создаем новый фьючерс, JoinAll, передавая коллекцию фьючерсов в функцию join_all. Сигнатура для join_all требует, чтобы типы элементов в коллекции все реализовывали типаж Future, а Box<T> реализует Future только в том случае, если обернутый им T — это фьючерс, который реализует типаж Unpin.
Это много информации для усвоения! Чтобы действительно понять это, давайте углубимся немного дальше в то, как на самом деле работает типаж Future, в частности, в отношении закрепления (pinning). Посмотрите еще раз на определение типажа Future:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; // Required method fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Параметр cx и его тип Context — это ключ к тому, как рантайм на самом деле знает, когда проверять любой данный фьючерс, оставаясь при этом ленивым. Опять же, детали того, как это работает, выходят за рамки этой главы, и вам обычно нужно думать об этом только при написании собственной реализации Future. Мы сосредоточимся вместо этого на типе для self, так как это первый раз, когда мы видим метод, где self имеет аннотацию типа. Аннотация типа для self работает так же, как аннотации типов для других параметров функции, но с двумя ключевыми различиями:
- Она сообщает Rust, какого типа должен быть
self, чтобы метод можно было вызвать. - Это не может быть просто любой тип. Он ограничен типом, для которого реализован метод, ссылкой или умным указателем на этот тип, или
Pin, оборачивающим ссылку на этот тип.
Мы увидим больше об этом синтаксисе в Главе 18. Пока достаточно знать, что если мы хотим опросить (poll) фьючерс, чтобы проверить, является ли он Pending или Ready(Output), нам нужна изменяемая ссылка на тип, обернутая в Pin.
Pin — это обертка для указателей (pointer-like types), таких как &, &mut, Box и Rc. (Технически, Pin работает с типами, которые реализуют типажи Deref или DerefMut, но это фактически эквивалентно работе только со ссылками и умными указателями.) Pin сам по себе не является указателем и не имеет собственного поведения, как Rc и Arc со счетчиком ссылок; это является инструментом, который компилятор может использовать для обеспечения ограничений на использование указателей.
Вспоминая, что .await реализован через вызовы poll, начинает объяснять сообщение об ошибке, которое мы видели ранее, но оно было сформулировано в терминах Unpin, а не Pin. Так как же именно Pin относится к Unpin и почему Future нуждается в том, чтобы self был в типе Pin для вызова poll?
Вспомните из начала этой главы, что серия точек ожидания (await points) в фьючерсе компилируется в state machine (машину состояний), и компилятор гарантирует, что эта state machine следует всем обычным правилам Rust в отношении безопасности, включая заимствование и владение. Чтобы это работало, Rust смотрит, какие данные нужны между одной точкой ожидания и либо следующей точкой ожидания, либо концом асинхронного блока. Затем он создает соответствующий вариант в скомпилированной state machine. Каждый вариант получает необходимый ему доступ к данным, которые будут использоваться в этом разделе исходного кода, будь то путем взятия владения этими данными или путем получения изменяемой или неизменяемой ссылки на них.
Пока все хорошо: если мы где-то ошибаемся с владением или ссылками в данном асинхронном блоке, проверщик заимствований (borrow checker) сообщит нам. Когда мы хотим переместить фьючерс, соответствующий этому блоку — например, переместить его в Vec для передачи в join_all — все становится сложнее.
Когда мы перемещаем фьючерс — будь то помещение его в структуру данных для использования в качестве итератора с join_all или возврат его из функции — это на самом деле означает перемещение state machine, которую Rust создает для нас. И в отличие от большинства других типов в Rust, фьючерсы, которые Rust создает для асинхронных блоков, могут в конечном итоге содержать ссылки на самих себя в полях любого данного варианта, как показано в упрощенной иллюстрации на Рисунке 17-4.

Рисунок 17-4: Самоссылающийся тип данных
Однако по умолчанию любое перемещение объекта, имеющего ссылку на себя, является небезопасным, потому что ссылки всегда указывают на фактический адрес памяти того, на что они ссылаются (см. Рисунок 17-5). Если вы переместите саму структуру данных, эти внутренние ссылки останутся указывать на старое местоположение. Однако это место в памяти теперь недействительно. С одной стороны, его значение не будет обновляться при внесении изменений в структуру данных. С другой — что более важно — компьютер теперь может свободно повторно использовать эту память для других целей! Впоследствии вы можете столкнуться с чтением совершенно несвязанных данных.
Рисунок 17-5: Небезопасный результат перемещения самоссылающегося типа данных
Теоретически компилятор Rust мог бы пытаться обновлять каждую ссылку на объект всякий раз, когда он перемещается, но это могло бы добавить много накладных расходов на производительность, особенно если нужно обновить целую сеть ссылок. Если бы мы вместо этого могли гарантировать, что рассматриваемая структура данных не перемещается в памяти, нам не пришлось бы обновлять никакие ссылки. Именно для этого и нужен проверщик заимствований (borrow checker) Rust: в безопасном коде он предотвращает перемещение любого элемента, на который есть активная ссылка.
Pin основывается на этом, чтобы дать нам именно ту гарантию, которая нам нужна. Когда мы закрепляем (pin) значение, оборачивая указатель на это значение в Pin, оно больше не может быть перемещено. Таким образом, если у вас есть Pin<Box<SomeType>>, вы фактически закрепляете значение SomeType, а не указатель Box. Рисунок 17-6 иллюстрирует этот процесс.

Рисунок 17-6: Закрепление Box, который указывает на самоссылающийся тип фьючерса
На самом деле, указатель Box все еще может свободно перемещаться. Помните: нам важно обеспечить, чтобы данные, на которые в конечном итоге ссылаются, оставались на месте. Если указатель перемещается, но данные, на которые он указывает, находятся в том же месте, как на Рисунке 17-7, то потенциальной проблемы нет. (В качестве самостоятельного упражнения посмотрите документацию по типам, а также модуль std::pin и попробуйте разобраться, как бы вы сделали это с Pin, оборачивающим Box.) Ключевой момент в том, что самоссылающийся тип сам не может перемещаться, потому что он все еще закреплен.

Рисунок 17-7: Перемещение Box, который указывает на самоссылающийся тип фьючерса
Однако большинство типов совершенно безопасно перемещать, даже если они находятся за указателем Pin. Нам нужно думать о закреплении только тогда, когда элементы имеют внутренние ссылки. Примитивные значения, такие как числа и логические значения, безопасны, потому что они, очевидно, не имеют никаких внутренних ссылок. Как и большинство типов, с которыми вы обычно работаете в Rust. Вы можете, например, перемещать Vec, не беспокоясь. Учитывая то, что мы видели до сих пор, если бы у вас был Pin<Vec<String>>, вам пришлось бы делать все через безопасные, но ограничительные API, предоставляемые Pin, даже though Vec<String> всегда безопасно перемещать, если на него нет других ссылок. Нам нужен способ сообщить компилятору, что в таких случаях можно перемещать элементы, — и здесь на сцену выходит Unpin.
Unpin — это маркерный типаж (marker trait), подобный типажам Send и Sync, которые мы видели в Главе 16, и, следовательно, не имеет собственной функциональности. Маркерные типажи существуют только для того, чтобы сообщить компилятору, что тип, реализующий данный типаж, безопасно использовать в определенном контексте. Unpin сообщает компилятору, что данный тип не нуждается в соблюдении каких-либо гарантий относительно того, можно ли безопасно перемещать рассматриваемое значение.
Так же, как с Send и Sync, компилятор автоматически реализует Unpin для всех типов, для которых может доказать, что это безопасно. Особый случай, опять же похожий на Send и Sync, — это когда Unpin не реализован для типа. Обозначение для этого — impl !Unpin for SomeType, где SomeType — это имя типа, которому нужно соблюдать эти гарантии для безопасности при использовании указателя на этот тип в Pin.
Другими словами, есть две вещи, которые нужно помнить об отношениях между Pin и Unpin. Во-первых, Unpin — это «нормальный» случай, а !Unpin — особый. Во-вторых, имеет ли тип реализацию Unpin или !Unpin, важно только тогда, когда вы используете закрепленный указатель на этот тип, например Pin<&mut SomeType>.
Чтобы сделать это конкретным, подумайте о String: у него есть длина и символы Юникода, из которых он состоит. Мы можем обернуть String в Pin, как показано на Рисунке 17-8. Однако String автоматически реализует Unpin, как и большинство других типов в Rust.
Рисунок 17-8: Закрепление String; пунктирная линия указывает на то, что String реализует типаж Unpin и, следовательно, не является закрепленным
В результате мы можем делать вещи, которые были бы незаконны, если бы String реализовывал !Unpin, например, заменять одну строку другой точно в том же месте памяти, как на Рисунке 17-9. Это не нарушает контракт Pin, потому что String не имеет внутренних ссылок, которые делали бы его перемещение небезопасным. Именно поэтому он реализует Unpin, а не !Unpin.

Рисунок 17-9: Замена String на совершенно другую String в памяти
Теперь мы знаем достаточно, чтобы понять ошибки, о которых сообщалось при вызове join_all обратно в Листинге 17-23. Изначально мы пытались переместить фьючерсы, созданные асинхронными блоками, в Vec<Box<dyn Future<Output = ()>>>, но, как мы видели, эти фьючерсы могут иметь внутренние ссылки, поэтому они не реализуют Unpin автоматически. Как только мы закрепим их, мы можем передать результирующий тип Pin в Vec, будучи уверенными, что базовые данные во фьючерсах не будут перемещены. Листинг 17-24 показывает, как исправить код, вызвав макрос pin! в месте определения каждого из трех фьючерсов и скорректировав тип трейт-объекта.
#![allow(unused)] fn main() { use std::pin::{Pin, pin}; // --snip-- let tx1_fut = pin!(async move { // --snip-- }); let rx_fut = pin!(async { // --snip-- }); let tx_fut = pin!(async move { // --snip-- }); let futures: Vec<Pin<&mut dyn Future<Output = ()>>> = vec![tx1_fut, rx_fut, tx_fut]; }
Листинг 17-24: Закрепление фьючерсов для возможности их перемещения в вектор
Этот пример теперь компилируется и запускается, и мы могли бы добавлять или удалять фьючерсы из вектора во время выполнения и объединять их все.
Pin и Unpin в основном важны для создания низкоуровневых библиотек или когда вы создаете сам рантайм, а не для повседневного кода на Rust. Однако, когда вы увидите эти типажи в сообщениях об ошибках, у вас теперь будет лучшее представление о том, как исправить ваш код!
Примечание: Это сочетание
PinиUnpinделает возможной безопасную реализацию целого класса сложных типов в Rust, которые в противном случае оказались бы сложными из-за их самоссылающейся природы. Типы, требующиеPin, сегодня чаще всего встречаются в асинхронном Rust, но иногда вы можете увидеть их и в других контекстах.Специфика того, как работают
PinиUnpin, и правила, которым они должны следовать, подробно описаны в API-документации дляstd::pin, так что если вы хотите узнать больше, это отличное место для начала.Если вы хотите понять, как все работает под капотом, еще более подробно, см. Главы 2 и 4 книги «Asynchronous Programming in Rust».
Типаж Stream
Теперь, когда вы глубже поняли типажи Future, Pin и Unpin, мы можем обратить наше внимание на типаж Stream. Как вы узнали ранее в главе, потоки (streams) похожи на асинхронные итераторы. Однако, в отличие от Iterator и Future, на момент написания этой книги Stream не имеет определения в стандартной библиотеке, но существует очень распространенное определение из крейта futures, используемое во всей экосистеме.
Давайте вспомним определения типажей Iterator и Future, прежде чем смотреть на то, как типаж Stream может объединить их вместе. Из Iterator у нас есть идея последовательности: его метод next предоставляет Option<Self::Item>. Из Future у нас есть идея готовности с течением времени: его метод poll предоставляет Poll<Self::Output>. Чтобы представить последовательность элементов, которые становятся готовыми с течением времени, мы определяем типаж Stream, который объединяет эти особенности:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } }
Типаж Stream определяет ассоциированный тип Item для типа элементов, производимых потоком. Это похоже на Iterator, где элементов может быть от нуля до многих, и в отличие от Future, где всегда есть единственный Output, даже если это тип ().
Stream также определяет метод для получения этих элементов. Мы называем его poll_next, чтобы было ясно, что он опрашивает (polls) так же, как это делает Future::poll, и производит последовательность элементов так же, как это делает Iterator::next. Его возвращаемый тип объединяет Poll с Option. Внешний тип — это Poll, потому что его нужно проверять на готовность, так же как и фьючерс. Внутренний тип — это Option, потому что ему нужно сигнализировать, есть ли еще сообщения, так же как и итератору.
Нечто очень похожее на это определение, вероятно, в конечном итоге станет частью стандартной библиотеки Rust. А пока это часть инструментария большинства рантаймов, так что вы можете на него положиться, и всё, что мы рассмотрим дальше, должно в целом применяться!
В примерах, которые мы видели в разделе ["Потоки (Streams): Фьючерсы в последовательности"], однако, мы не использовали poll_next или Stream, а вместо этого использовали next и StreamExt. Мы могли бы работать напрямую с API poll_next, вручную написав свои собственные state machine для потоков, конечно, так же как мы могли бы работать с фьючерсами напрямую через их метод poll. Однако использование .await гораздо приятнее, и типаж StreamExt предоставляет метод next, чтобы мы могли сделать именно это:
#![allow(unused)] fn main() { trait StreamExt: Stream { async fn next(&mut self) -> Option<Self::Item> where Self: Unpin; // другие методы... } }
Примечание: Фактическое определение, которое мы использовали ранее в главе, выглядит немного иначе, потому что оно поддерживает версии Rust, которые еще не поддерживали использование асинхронных функций в типажах. В результате оно выглядит так:
#![allow(unused)] fn main() { fn next(&mut self) -> Next<'_, Self> where Self: Unpin; }Этот тип
Next— это структура, которая реализуетFutureи позволяет нам обозначить время жизни ссылки наselfс помощьюNext<'_, Self>, чтобы.awaitмог работать с этим методом.
Типаж StreamExt также является местом, где находятся все интересные методы, доступные для использования с потоками. StreamExt автоматически реализуется для каждого типа, который реализует Stream, но эти типажи определены отдельно, чтобы позволить сообществу итерировать по удобным API, не затрагивая базовый типаж.
В версии StreamExt, используемой в крейте trpl, типаж не только определяет метод next, но и предоставляет реализацию по умолчанию для next, которая корректно обрабатывает детали вызова Stream::poll_next. Это означает, что даже когда вам нужно написать свой собственный тип данных-потока, вам достаточно реализовать только Stream, и тогда любой, кто использует ваш тип данных, сможет автоматически использовать с ним StreamExt и его методы.
Это всё, что мы рассмотрим по низкоуровневым деталям этих типажей. В завершение давайте рассмотрим, как фьючерсы (включая потоки), задачи (tasks) и потоки (threads) сочетаются вместе!
Собираем всё вместе: Фьючерсы, Задачи и Потоки
Как мы видели в Главе 16, потоки (threads) предоставляют один из подходов к конкурентности. В этой главе мы увидели другой подход: использование async с фьючерсами (futures) и потоками (streams). Если вы задаетесь вопросом, когда выбрать один метод вместо другого, ответ таков: это зависит от ситуации! И во многих случаях выбор стоит не между потоками или async, а между потоками и async.
Многие операционные системы поставляли модели конкурентности на основе потоков на протяжении десятилетий, и, как следствие, многие языки программирования их поддерживают. Однако у этих моделей есть свои компромиссы. Во многих операционных системах они используют изрядный объем памяти для каждого потока. Потоки также являются опцией только тогда, когда ваша операционная система и оборудование их поддерживают. В отличие от mainstream настольных и мобильных компьютеров, некоторые встраиваемые (embedded) системы вообще не имеют ОС, поэтому у них нет и потоков.
Асинхронная модель предоставляет другой — и в конечном счете дополняющий — набор компромиссов. В асинхронной модели конкурентные операции не требуют собственных потоков. Вместо этого они могут выполняться в задачах (tasks), как когда мы использовали trpl::spawn_task для запуска работы из синхронной функции в разделе о потоках (streams). Задача похожа на поток, но вместо управления операционной системой ею управляет код на уровне библиотеки: рантайм (runtime).
Есть причина, по которой API для порождения потоков и порождения задач так похожи. Потоки действуют как граница для наборов синхронных операций; конкурентность возможна между потоками. Задачи действуют как граница для наборов асинхронных операций; конкурентность возможна как между задачами, так и внутри них, потому что задача может переключаться между фьючерсами в своем теле. Наконец, фьючерсы — это самая гранулярная единица конкурентности в Rust, и каждый фьючерс может представлять собой дерево других фьючерсов. Рантайм — конкретно его исполнитель (executor) — управляет задачами, а задачи управляют фьючерсами. В этом отношении задачи похожи на облегченные, управляемые рантаймом потоки с дополнительными возможностями, которые возникают из-за управления рантаймом, а не операционной системой.
Это не означает, что асинхронные задачи всегда лучше потоков (или наоборот). Конкурентность с потоками в некотором смысле является более простой моделью программирования, чем конкурентность с async. Это может быть как силой, так и слабостью. Потоки в некотором роде «запустил и забыл»; у них нет собственного эквивалента фьючерсу, поэтому они просто выполняются до завершения, не прерываясь, кроме как самой операционной системой.
И оказывается, что потоки и задачи часто очень хорошо работают вместе, потому что задачи могут (по крайней мере, в некоторых рантаймах) перемещаться между потоками. На самом деле, под капотом рантайм, который мы использовали — включая функции spawn_blocking и spawn_task — по умолчанию является многопоточным! Многие рантаймы используют подход, называемый кража работы (work stealing), чтобы прозрачно перемещать задачи между потоками на основе текущей загрузки потоков, чтобы повысить общую производительность системы. Этот подход фактически требует и потоков, и задач, а следовательно, и фьючерсов.
Когда думаете о том, какой метод использовать, руководствуйтесь этими эмпирическими правилами:
- Если работа очень хорошо распараллеливается (то есть, ограничена по CPU (CPU-bound)), например, обработка набора данных, где каждая часть может обрабатываться отдельно, потоки — лучший выбор.
- Если работа очень конкурентна (то есть, ограничена по вводу-выводу (I/O-bound)), например, обработка сообщений из множества разных источников, которые могут поступать с разными интервалами или скоростями, async — лучший выбор.
И если вам нужен и параллелизм, и конкурентность, вам не обязательно выбирать между потоками и async. Вы можете свободно использовать их вместе, позволяя каждому играть свою наилучшую роль. Например, Листинг 17-25 показывает довольно распространенный пример такого смешения в реальном коде на Rust.
Файл: src/main.rs
use std::{thread, time::Duration}; fn main() { let (tx, mut rx) = trpl::channel(); thread::spawn(move || { for i in 1..11 { tx.send(i).unwrap(); thread::sleep(Duration::from_secs(1)); } }); trpl::block_on(async { while let Some(message) = rx.recv().await { println!("{message}"); } }); }
Листинг 17-25: Отправка сообщений блокирующим кодом в потоке и ожидание сообщений в асинхронном блоке
Мы начинаем с создания асинхронного канала, затем порождаем поток, который забирает владение отправляющей стороной канала с помощью ключевого слова move. Внутри потока мы отправляем числа от 1 до 10, делая паузу в секунду между каждым. Наконец, мы запускаем фьючерс, созданный с помощью асинхронного блока, переданного в trpl::block_on, как мы делали на протяжении всей главы. В этом фьючерсе мы ожидаем эти сообщения, как и в других примерах с передачей сообщений, которые мы видели.
Возвращаясь к сценарию, с которого мы начали главу, представьте себе выполнение набора задач кодирования видео с использованием выделенного потока (поскольку кодирование видео ограничено по CPU), но уведомление пользовательского интерфейса о завершении этих операций через асинхронный канал. В реальных случаях использования существует бесчисленное множество примеров таких комбинаций.
Резюме
Это не последний раз, когда вы увидите конкурентность в этой книге. Проект в Главе 21 применит эти концепции в более реалистичной ситуации, чем простые примеры, обсуждаемые здесь, и более прямо сравнит решение проблем с помощью потоков и задач/фьючерсов.
Независимо от того, какой из этих подходов вы выберете, Rust предоставляет вам инструменты, необходимые для написания безопасного, быстрого, конкурентного кода — будь то для высокопроизводительного веб-сервера или встраиваемой операционной системы.
Далее мы поговорим об идиоматических способах моделирования проблем и структурирования решений по мере роста ваших программ на Rust. Кроме того, мы обсудим, как идиомы Rust соотносятся с теми, с которыми вы могли быть знакомы по объектно-ориентированному программированию.
Особенности объектно-ориентированного программирования
Объектно-ориентированное программирование (ООП) — это способ моделирования программ. Объекты как программная концепция были введены в языке программирования Simula в 1960-х годах. Эти объекты повлияли на программную архитектуру Алана Кея, в которой объекты передают сообщения друг другу. Для описания этой архитектуры он ввел термин «объектно-ориентированное программирование» в 1967 году. Существует множество конкурирующих определений, описывающих, что такое ООП, и согласно некоторым из них Rust является объектно-ориентированным, а согласно другим — нет. В этой главе мы рассмотрим определенные характеристики, которые обычно считаются объектно-ориентированными, и то, как эти характеристики переводятся в идиоматический Rust. Затем мы покажем вам, как реализовать объектно-ориентированный шаблон проектирования в Rust, и обсудим компромиссы такого подхода в сравнении с реализацией решения с использованием некоторых сильных сторон Rust.
Характеристики объектно-ориентированных языков
В сообществе программистов нет консенсуса относительно того, какими функциями должен обладать язык, чтобы считаться объектно-ориентированным. Rust находится под влиянием многих парадигм программирования, включая ООП; например, мы изучали особенности, пришедшие из функционального программирования, в Главе 13. Можно утверждать, что ООП-языки разделяют определенные общие характеристики — а именно: объекты, инкапсуляция и наследование. Давайте посмотрим, что означает каждая из этих характеристик и поддерживает ли её Rust.
Объекты содержат данные и поведение
Книга "Design Patterns: Elements of Reusable Object-Oriented Software" Эриха Гаммы, Ричарда Хелма, Ральфа Джонсона и Джона Влиссидеса (Addison-Wesley, 1994), в просторечии называемая "книгой Банды Четырех", представляет собой каталог объектно-ориентированных шаблонов проектирования. Она определяет ООП следующим образом:
Объектно-ориентированные программы состоят из объектов. Объект объединяет как данные, так и процедуры, которые работают с этими данными. Процедуры обычно называются методами или операциями.
Согласно этому определению, Rust является объектно-ориентированным: структуры и перечисления содержат данные, а блоки impl предоставляют методы для структур и перечислений. Хотя структуры и перечисления с методами не называются объектами, они предоставляют ту же функциональность в соответствии с определением объектов от Банды Четырех.
Инкапсуляция, скрывающая детали реализации
Другой аспект, обычно связанный с ООП, — это идея инкапсуляции, которая означает, что детали реализации объекта недоступны для кода, использующего этот объект. Следовательно, единственный способ взаимодействовать с объектом — через его публичный API; код, использующий объект, не должен иметь возможности проникать во внутренности объекта и напрямую изменять данные или поведение. Это позволяет программисту изменять и рефакторить внутренности объекта без необходимости изменять код, который его использует.
Мы обсуждали, как управлять инкапсуляцией в Главе 7: мы можем использовать ключевое слово pub, чтобы решить, какие модули, типы, функции и методы в нашем коде должны быть публичными, а всё остальное по умолчанию является приватным. Например, мы можем определить структуру AveragedCollection, которая имеет поле, содержащее вектор значений i32. Структура также может иметь поле, содержащее среднее значение элементов в векторе, что означает, что среднее значение не нужно вычислять по требованию каждый раз, когда оно кому-то нужно. Другими словами, AveragedCollection будет кэшировать вычисленное среднее значение для нас. В листинге 18-1 приведено определение структуры AveragedCollection.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct AveragedCollection { list: Vec<i32>, average: f64, } }
Листинг 18-1: Структура AveragedCollection, которая хранит список целых чисел и среднее значение элементов в коллекции
Структура помечена как pub, чтобы другой код мог её использовать, но поля внутри структуры остаются приватными. Это важно в данном случае, потому что мы хотим гарантировать, что всякий раз, когда значение добавляется в список или удаляется из него, среднее значение также обновляется. Мы делаем это, реализуя методы add, remove и average для структуры, как показано в листинге 18-2.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl AveragedCollection { pub fn add(&mut self, value: i32) { self.list.push(value); self.update_average(); } pub fn remove(&mut self) -> Option<i32> { let result = self.list.pop(); match result { Some(value) => { self.update_average(); Some(value) } None => None, } } pub fn average(&self) -> f64 { self.average } fn update_average(&mut self) { let total: i32 = self.list.iter().sum(); self.average = total as f64 / self.list.len() as f64; } } }
Листинг 18-2: Реализации публичных методов add, remove и average для AveragedCollection
Публичные методы add, remove и average являются единственными способами доступа или изменения данных в экземпляре AveragedCollection. Когда элемент добавляется в list с помощью метода add или удаляется с помощью метода remove, реализации каждого вызывают приватный метод update_average, который обрабатывает обновление поля average.
Мы оставляем поля list и average приватными, чтобы у внешнего кода не было возможности напрямую добавлять или удалять элементы из поля list; в противном случае поле average может перестать быть актуальным при изменении списка. Метод average возвращает значение в поле average, позволяя внешнему коду читать среднее значение, но не изменять его.
Поскольку мы инкапсулировали детали реализации структуры AveragedCollection, мы можем легко изменять аспекты, такие как структура данных, в будущем. Например, мы могли бы использовать HashSet<i32> вместо Vec<i32> для поля list. До тех пор, пока сигнатуры публичных методов add, remove и average остаются неизменными, код, использующий AveragedCollection, не нуждался бы в изменениях. Если бы мы сделали list публичным, это не обязательно было бы так: HashSet<i32> и Vec<i32> имеют разные методы для добавления и удаления элементов, поэтому внешнему коду, вероятно, пришлось бы измениться, если бы он напрямую изменял list.
Если инкапсуляция является обязательным аспектом для того, чтобы язык считался объектно-ориентированным, то Rust соответствует этому требованию. Возможность использовать pub или нет для разных частей кода позволяет осуществлять инкапсуляцию деталей реализации.
Наследование как система типов и способ совместного использования кода
Наследование — это механизм, с помощью которого объект может наследовать элементы из определения другого объекта, таким образом получая данные и поведение родительского объекта без необходимости определять их снова.
Если язык должен иметь наследование, чтобы быть объектно-ориентированным, то Rust не является таким языком. Нет возможности определить структуру, которая наследует поля и реализации методов родительской структуры без использования макроса.
Однако, если вы привыкли иметь наследование в своем арсенале инструментов программирования, вы можете использовать другие решения в Rust, в зависимости от причины, по которой вы изначально обращаетесь к наследованию.
Вы бы выбрали наследование по двум основным причинам. Первая — это повторное использование кода: вы можете реализовать определенное поведение для одного типа, и наследование позволяет вам повторно использовать эту реализацию для другого типа. Вы можете сделать это ограниченным способом в коде Rust, используя реализации методов трейта по умолчанию, которые вы видели в листинге 10-14, когда мы добавляли реализацию по умолчанию для метода summarize в трейте Summary. Любой тип, реализующий трейт Summary, будет иметь доступный метод summarize без какого-либо дополнительного кода. Это похоже на то, как родительский класс имеет реализацию метода, а наследуемый дочерний класс также имеет реализацию этого метода. Мы также можем переопределить реализацию по умолчанию метода summarize, когда реализуем трейт Summary, что похоже на то, как дочерний класс переопределяет реализацию метода, унаследованного от родительского класса.
Другая причина использования наследования связана с системой типов: чтобы позволить дочернему типу использоваться в тех же местах, что и родительский тип. Это также называется полиморфизмом, что означает, что вы можете заменять несколько объектов друг другом во время выполнения, если они разделяют определенные характеристики.
Полиморфизм
Для многих людей полиморфизм является синонимом наследования. Но на самом деле это более общая концепция, которая относится к коду, который может работать с данными нескольких типов. При наследовании эти типы обычно являются подклассами.
Вместо этого Rust использует дженерики для абстрагирования от различных возможных типов и границы трейтов для наложения ограничений на то, что эти типы должны предоставлять. Это иногда называют ограниченным параметрическим полиморфизмом.
Rust выбрал другой набор компромиссов, не предлагая наследование. Наследование часто рискует общим использованием большего количества кода, чем необходимо. Подклассы не всегда должны разделять все характеристики своего родительского класса, но при наследовании это происходит. Это может сделать дизайн программы менее гибким. Это также introduces возможность вызова методов в подклассах, которые не имеют смысла или вызывают ошибки, потому что методы не применимы к подклассу. Кроме того, некоторые языки позволяют только одиночное наследование (что означает, что подкласс может наследовать только от одного класса), что еще больше ограничивает гибкость дизайна программы.
По этим причинам Rust использует другой подход, используя трейт-объекты вместо наследования для достижения полиморфизма во время выполнения. Давайте посмотрим, как работают трейт-объекты.
Использование трейт-объектов для абстракции над общим поведением
В Главе 8 мы упоминали, что одно из ограничений векторов заключается в том, что они могут хранить элементы только одного типа. Мы создали обходное решение в Листинге 8-9, где определили перечисление SpreadsheetCell с вариантами для хранения целых чисел, чисел с плавающей точкой и текста. Это означало, что мы могли хранить разные типы данных в каждой ячейке и при этом иметь вектор, представляющий строку ячеек. Это совершенно хорошее решение, когда наши взаимозаменяемые элементы представляют собой фиксированный набор типов, известный на момент компиляции кода.
Однако иногда мы хотим, чтобы пользователь нашей библиотеки мог расширять набор типов, допустимых в определенной ситуации. Чтобы показать, как мы можем достичь этого, мы создадим пример инструмента графического пользовательского интерфейса (GUI), который проходит по списку элементов, вызывая метод draw для каждого из них, чтобы отрисовать его на экране — распространенная техника для инструментов GUI. Мы создадим библиотечный крейт с именем gui, который содержит структуру библиотеки GUI. Этот крейт может включать некоторые типы для использования людьми, такие как Button или TextField. Кроме того, пользователи gui захотят создавать свои собственные типы, которые можно отрисовывать: например, один программист может добавить Image, а другой — SelectBox.
Во время написания библиотеки мы не можем знать и определять все типы, которые другие программисты могут захотеть создать. Но мы знаем, что gui должен отслеживать множество значений разных типов, и ему нужно вызывать метод draw для каждого из этих значений разных типов. Ему не нужно знать точно, что произойдет, когда мы вызовем метод draw, только то, что значение будет иметь этот метод доступным для вызова.
Чтобы сделать это в языке с наследованием, мы могли бы определить класс с именем Component, который имеет метод draw. Другие классы, такие как Button, Image и SelectBox, наследовались бы от Component и, таким образом, наследовали бы метод draw. Они могли бы каждый переопределить метод draw, чтобы определить свое собственное поведение, но фреймворк мог бы рассматривать все типы как экземпляры Component и вызывать draw на них. Но поскольку в Rust нет наследования, нам нужен другой способ структурировать библиотеку gui, чтобы позволить пользователям создавать новые типы, совместимые с библиотекой.
Определение трейта для общего поведения
Чтобы реализовать поведение, которое мы хотим иметь в gui, мы определим трейт с именем Draw, который будет иметь один метод с именем draw. Затем мы можем определить вектор, который принимает трейт-объект. Трейт-объект указывает как на экземпляр типа, реализующего наш указанный трейт, так и на таблицу, используемую для поиска методов трейта для этого типа во время выполнения. Мы создаем трейт-объект, указывая какой-либо указатель, такой как ссылка или умный указатель Box<T>, затем ключевое слово dyn, а затем указывая соответствующий трейт. (Мы поговорим о причине, по которой трейт-объекты должны использовать указатель, в разделе "Динамически sized типы и трейт Sized" в Главе 20.) Мы можем использовать трейт-объекты вместо универсального или конкретного типа. Где бы мы ни использовали трейт-объект, система типов Rust гарантирует во время компиляции, что любое значение, используемое в этом контексте, будет реализовывать трейт трейт-объекта. Следовательно, нам не нужно знать все возможные типы во время компиляции.
Мы упоминали, что в Rust мы избегаем называть структуры и перечисления «объектами», чтобы отличать их от объектов других языков. В структуре или перечислении данные в полях структуры и поведение в блоках impl разделены, тогда как в других языках данные и поведение, объединенные в одно понятие, часто называются объектом. Трейт-объекты отличаются от объектов в других языках тем, что мы не можем добавлять данные в трейт-объект. Трейт-объекты не так универсально полезны, как объекты в других языках: их конкретная цель — позволить абстракцию над общим поведением.
Листинг 18-3 показывает, как определить трейт с именем Draw с одним методом draw.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub trait Draw { fn draw(&self); } }
Листинг 18-3: Определение трейта Draw
Этот синтаксис должен выглядеть знакомым из наших обсуждений о том, как определять трейты в Главе 10. Далее следует новый синтаксис: Листинг 18-4 определяет структуру с именем Screen, которая содержит вектор с именем components. Этот вектор имеет тип Box<dyn Draw>, который является трейт-объектом; это заместитель для любого типа внутри Box, который реализует трейт Draw.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct Screen { pub components: Vec<Box<dyn Draw>>, } }
Листинг 18-4: Определение структуры Screen с полем components, содержащим вектор трейт-объектов, реализующих трейт Draw
Для структуры Screen мы определим метод с именем run, который будет вызывать метод draw для каждого из своих компонентов, как показано в Листинге 18-5.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Screen { pub fn run(&self) { for component in self.components.iter() { component.draw(); } } } }
Листинг 18-5: Метод run на Screen, который вызывает метод draw для каждого компонента
Это работает иначе, чем определение структуры, которая использует параметр обобщенного типа с границами трейта. Параметр обобщенного типа может быть заменен только одним конкретным типом за раз, тогда как трейт-объекты позволяют нескольким конкретным типам подставляться вместо трейт-объекта во время выполнения. Например, мы могли бы определить структуру Screen с использованием обобщенного типа и границы трейта, как в Листинге 18-6.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct Screen<T: Draw> { pub components: Vec<T>, } impl<T> Screen<T> where T: Draw, { pub fn run(&self) { for component in self.components.iter() { component.draw(); } } } }
Листинг 18-6: Альтернативная реализация структуры Screen и ее метода run с использованием дженериков и границ трейтов
Это ограничивает нас экземпляром Screen, который имеет список компонентов, все типа Button или все типа TextField. Если у вас всегда будут только однородные коллекции, использование дженериков и границ трейтов предпочтительнее, потому что определения будут моно morphизированы во время компиляции для использования конкретных типов.
С другой стороны, с методом, использующим трейт-объекты, один экземпляр Screen может содержать Vec<T>, который содержит Box<Button>, а также Box<TextField>. Давайте посмотрим, как это работает, а затем поговорим о последствиях для производительности во время выполнения.
Реализация трейта
Теперь мы добавим некоторые типы, которые реализуют трейт Draw. Мы предоставим тип Button. Опять же, фактическая реализация библиотеки GUI выходит за рамки этой книги, поэтому метод draw не будет иметь никакой полезной реализации в своем теле. Чтобы представить, как может выглядеть реализация, структура Button может иметь поля для width, height и label, как показано в Листинге 18-7.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct Button { pub width: u32, pub height: u32, pub label: String, } impl Draw for Button { fn draw(&self) { // код для фактической отрисовки кнопки } } }
Листинг 18-7: Структура Button, реализующая трейт Draw
Поля width, height и label на Button будут отличаться от полей других компонентов; например, тип TextField может иметь те же поля плюс поле placeholder. Каждый из типов, которые мы хотим отрисовать на экране, будет реализовывать трейт Draw, но будет использовать разный код в методе draw для определения того, как рисовать этот конкретный тип, как здесь у Button (без фактического кода GUI, как упоминалось). Тип Button, например, может иметь дополнительный блок impl, содержащий методы, связанные с тем, что происходит, когда пользователь нажимает кнопку. Такие методы не будут применяться к типам вроде TextField.
Если кто-то, использующий нашу библиотеку, решит реализовать структуру SelectBox, которая имеет поля width, height и options, он также реализует трейт Draw для типа SelectBox, как показано в Листинге 18-8.
Файл: src/main.rs
#![allow(unused)] fn main() { use gui::Draw; struct SelectBox { width: u32, height: u32, options: Vec<String>, } impl Draw for SelectBox { fn draw(&self) { // код для фактической отрисовки select box } } }
Листинг 18-8: Другой крейт, использующий gui и реализующий трейт Draw на структуре SelectBox
Теперь пользователь нашей библиотеки может написать свою функцию main, чтобы создать экземпляр Screen. К экземпляру Screen они могут добавить SelectBox и Button, поместив каждый в Box<T>, чтобы стать трейт-объектом. Затем они могут вызвать метод run на экземпляре Screen, который вызовет draw для каждого из компонентов. Листинг 18-9 показывает эту реализацию.
Файл: src/main.rs
use gui::{Button, Screen}; fn main() { let screen = Screen { components: vec![ Box::new(SelectBox { width: 75, height: 10, options: vec![ String::from("Yes"), String::from("Maybe"), String::from("No"), ], }), Box::new(Button { width: 50, height: 10, label: String::from("OK"), }), ], }; screen.run(); }
Листинг 18-9: Использование трейт-объектов для хранения значений разных типов, реализующих один и тот же трейт
Когда мы писали библиотеку, мы не знали, что кто-то может добавить тип SelectBox, но наша реализация Screen смогла работать с новым типом и рисовать его, потому что SelectBox реализует трейт Draw, что означает, что он реализует метод draw.
Эта концепция — забота только о сообщениях, на которые отвечает значение, а не о конкретном типе значения — похожа на концепцию утиной типизации в динамически типизированных языках: если оно ходит как утка и крякает как утка, то это должно быть уткой! В реализации run для Screen в Листинге 18-5, run не нужно знать, какой конкретный тип у каждого компонента. Он не проверяет, является ли компонент экземпляром Button или SelectBox, он просто вызывает метод draw на компоненте. Указав Box<dyn Draw> в качестве типа значений в векторе components, мы определили, что Screen нуждается в значениях, для которых мы можем вызвать метод draw.
Преимущество использования трейт-объектов и системы типов Rust для написания кода, похожего на код с утиной типизацией, заключается в том, что нам никогда не приходится проверять, реализует ли значение определенный метод во время выполнения, или беспокоиться о получении ошибок, если значение не реализует метод, но мы все равно его вызываем. Rust не скомпилирует наш код, если значения не реализуют трейты, которые нужны трейт-объектам.
Например, Листинг 18-10 показывает, что происходит, если мы пытаемся создать Screen со String в качестве компонента.
Файл: src/main.rs
// Этот код не компилируется! use gui::Screen; fn main() { let screen = Screen { components: vec![Box::new(String::from("Hi"))], }; screen.run(); }
Листинг 18-10: Попытка использовать тип, который не реализует трейт трейт-объекта
Мы получим эту ошибку, потому что String не реализует трейт Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Эта ошибка позволяет нам знать, что либо мы передаем что-то в Screen, что мы не собирались передавать, и поэтому должны передать другой тип, либо мы должны реализовать Draw для String, чтобы Screen мог вызвать draw на нем.
Выполнение динамической диспетчеризации
Вспомните в разделе "Производительность кода с использованием дженериков" в Главе 10 наше обсуждение процесса моно morphизации, выполняемого компилятором для дженериков: компилятор генерирует необобщенные реализации функций и методов для каждого конкретного типа, который мы используем вместо параметра обобщенного типа. Код, полученный в результате моно morphизации, выполняет статическую диспетчеризацию, когда компилятор знает, какой метод вы вызываете во время компиляции. Это противоположно динамической диспетчеризации, когда компилятор не может определить во время компиляции, какой метод вы вызываете. В случаях динамической диспетчеризации компилятор генерирует код, который во время выполнения будет знать, какой метод вызвать.
Когда мы используем трейт-объекты, Rust должен использовать динамическую диспетчеризацию. Компилятор не знает все типы, которые могут быть использованы с кодом, использующим трейт-объекты, поэтому он не знает, какой метод, реализованный на каком типе, вызывать. Вместо этого во время выполнения Rust использует указатели внутри трейт-объекта, чтобы узнать, какой метод вызвать. Этот поиск влечет за собой затраты времени выполнения, которых нет при статической диспетчеризации. Динамическая диспетчеризация также предотвращает возможность компилятора встраивать код метода, что, в свою очередь, предотвращает некоторые оптимизации, и у Rust есть некоторые правила о том, где можно и где нельзя использовать динамическую диспетчеризацию, называемые совместимостью с dyn. Эти правила выходят за рамки данного обсуждения, но вы можете прочитать о них больше в справочнике. Однако мы получили дополнительную гибкость в коде, который мы написали в Листинге 18-5 и смогли поддержать в Листинге 18-9, так что это компромисс, который стоит учитывать.
Реализация объектно-ориентированного шаблона проектирования
Шаблон состояния (state pattern) — это объектно-ориентированный шаблон проектирования. Суть шаблона в том, что мы определяем набор состояний, которые значение может иметь внутренне. Состояния представлены набором объектов-состояний, и поведение значения изменяется в зависимости от его состояния. Мы рассмотрим пример структуры BlogPost, которая имеет поле для хранения своего состояния, которое будет объектом состояния из набора «черновик», «рецензирование» или «опубликовано».
Объекты состояний разделяют функциональность: в Rust, конечно, мы используем структуры и трейты, а не объекты и наследование. Каждый объект состояния отвечает за свое собственное поведение и за управление тем, когда он должен измениться в другое состояние. Значение, которое содержит объект состояния, ничего не знает о различном поведении состояний или о том, когда переходить между состояниями.
Преимущество использования шаблона состояния в том, что когда бизнес-требования программы изменяются, нам не нужно изменять код значения, содержащего состояние, или код, использующего значение. Нам нужно будет только обновить код внутри одного из объектов состояния, чтобы изменить его правила или, возможно, добавить больше объектов состояния.
Сначала мы реализуем шаблон состояния более традиционным объектно-ориентированным способом. Затем мы используем подход, который более естественен для Rust. Давайте углубимся в поэтапную реализацию рабочего процесса блога с использованием шаблона состояния.
Конечная функциональность будет выглядеть так:
- Запись в блоге начинается как пустой черновик.
- Когда черновик готов, запрашивается рецензирование записи.
- Когда запись утверждена, она публикуется.
- Только опубликованные записи блога возвращают содержимое для печати, чтобы неутвержденные записи не могли быть случайно опубликованы.
Любые другие попытки изменения записи не должны иметь эффекта. Например, если мы попытаемся утвердить черновик записи блога до того, как запросили рецензирование, запись должна остаться неопубликованным черновиком.
Попытка традиционного объектно-ориентированного стиля
Существует бесконечное множество способов структурировать код для решения одной и той же проблемы, каждый со своими компромиссами. Реализация в этом разделе больше соответствует традиционному объектно-ориентированному стилю, который можно написать на Rust, но который не использует некоторые сильные стороны Rust. Позже мы продемонстрируем другое решение, которое все еще использует объектно-ориентированный шаблон проектирования, но структурировано таким образом, что может показаться менее familiar программистам с объектно-ориентированным опытом. Мы сравним два решения, чтобы ощутить компромиссы при проектировании кода на Rust иначе, чем кода на других языках.
Листинг 18-11 показывает этот рабочий процесс в виде кода: это пример использования API, который мы реализуем в библиотечном крейте с именем blog. Это пока не скомпилируется, потому что мы еще не реализовали крейт blog.
Файл: src/main.rs
// Этот код не компилируется! use blog::Post; fn main() { let mut post = Post::new(); post.add_text("I ate a salad for lunch today"); assert_eq!("", post.content()); post.request_review(); assert_eq!("", post.content()); post.approve(); assert_eq!("I ate a salad for lunch today", post.content()); }
Листинг 18-11: Код, демонстрирующий желаемое поведение, которое мы хотим иметь в нашем крейте blog
Мы хотим позволить пользователю создавать новый черновик записи блога с помощью Post::new. Мы хотим разрешить добавление текста в запись блога. Если мы попытаемся получить содержимое записи сразу, до утверждения, мы не должны получить никакого текста, потому что запись все еще является черновиком. Мы добавили assert_eq! в код для демонстрационных целей. Отличным модульным тестом для этого было бы утверждение, что черновик записи блога возвращает пустую строку из метода content, но мы не будем писать тесты для этого примера.
Далее мы хотим включить запрос на рецензирование записи, и мы хотим, чтобы content возвращал пустую строку во время ожидания рецензии. Когда запись получает одобрение, она должна быть опубликована, то есть текст записи будет возвращен при вызове content.
Обратите внимание, что единственный тип, с которым мы взаимодействуем из крейта, — это тип Post. Этот тип будет использовать шаблон состояния и будет содержать значение, которое будет одним из трех объектов состояния, представляющих различные состояния, в которых может находиться запись — черновик, рецензирование или опубликовано. Изменение из одного состояния в другое будет управляться внутренне в типе Post. Состояния изменяются в ответ на методы, вызываемые пользователями нашей библиотеки на экземпляре Post, но им не нужно напрямую управлять изменениями состояния. Кроме того, пользователи не могут ошибиться с состояниями, например, опубликовать запись до ее рецензирования.
Определение Post и создание нового экземпляра
Давайте начнем реализацию библиотеки! Мы знаем, что нам нужна публичная структура Post, которая содержит некоторый контент, поэтому мы начнем с определения структуры и связанной с ней публичной функции new для создания экземпляра Post, как показано в листинге 18-12. Мы также создадим приватный трейт State, который будет определять поведение, которое должны иметь все объекты состояния для Post.
Затем Post будет содержать трейт-объект Box<dyn State> внутри Option<T> в приватном поле с именем state для хранения объекта состояния. Вы скоро увидите, почему Option<T> необходим.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct Post { state: Option<Box<dyn State>>, content: String, } impl Post { pub fn new() -> Post { Post { state: Some(Box::new(Draft {})), content: String::new(), } } } trait State {} struct Draft {} impl State for Draft {} }
Листинг 18-12: Определение структуры Post и функции new, которая создает новый экземпляр Post, трейта State и структуры Draft
Трейт State определяет поведение, общее для различных состояний записи. Объекты состояний — это Draft, PendingReview и Published, и все они будут реализовывать трейт State. Пока что трейт не имеет никаких методов, и мы начнем с определения только состояния Draft, потому что это состояние, в котором мы хотим, чтобы запись начинала.
Когда мы создаем новый Post, мы устанавливаем его поле state в значение Some, содержащее Box. Этот Box указывает на новый экземпляр структуры Draft. Это гарантирует, что всякий раз, когда мы создаем новый экземпляр Post, он будет начинаться как черновик. Поскольку поле state структуры Post является приватным, нет способа создать Post в любом другом состоянии! В функции Post::new мы устанавливаем поле content в новую пустую String.
Хранение текста содержимого записи
Мы видели в листинге 18-11, что мы хотим иметь возможность вызывать метод с именем add_text и передавать ему &str, который затем добавляется как текстовое содержимое записи блога. Мы реализуем это как метод, а не выставляем поле content как pub, чтобы позже мы могли реализовать метод, который будет контролировать, как читаются данные поля content. Метод add_text довольно прост, поэтому давайте добавим реализацию из листинга 18-13 в блок impl Post.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Post { // --snip-- pub fn add_text(&mut self, text: &str) { self.content.push_str(text); } } }
Листинг 18-13: Реализация метода add_text для добавления текста в содержимое записи
Метод add_text принимает изменяемую ссылку на self, потому что мы изменяем экземпляр Post, для которого вызываем add_text. Затем мы вызываем push_str для String в content и передаем аргумент text для добавления к сохраненному содержимому. Это поведение не зависит от состояния записи, поэтому оно не является частью шаблона состояния. Метод add_text вообще не взаимодействует с полем state, но является частью поведения, которое мы хотим поддерживать.
Гарантия того, что содержимое черновика записи пусто
Даже после того как мы вызвали add_text и добавили некоторое содержимое в нашу запись, мы все равно хотим, чтобы метод content возвращал пустой строковый срез, потому что запись все еще находится в состоянии черновика, как показано первым assert_eq! в листинге 18-11. Пока давайте реализуем метод content самым простым способом, который будет удовлетворять этому требованию: всегда возвращать пустой строковый срез. Мы изменим это позже, как только реализуем возможность изменять состояние записи, чтобы ее можно было опубликовать. До сих пор записи могут быть только в состоянии черновика, поэтому содержимое записи должно всегда быть пустым. Листинг 18-14 показывает эту заглушку реализации.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Post { // --snip-- pub fn content(&self) -> &str { "" } } }
Листинг 18-14: Добавление реализации-заглушки для метода content в Post, которая всегда возвращает пустой строковый срез
С добавленным методом content все в листинге 18-11 до первого assert_eq! работает как задумано.
Запрос рецензирования, который изменяет состояние записи
Далее нам нужно добавить функциональность для запроса рецензирования записи, которая должна изменять ее состояние с Draft на PendingReview. Листинг 18-15 показывает этот код.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Post { // --snip-- pub fn request_review(&mut self) { if let Some(s) = self.state.take() { self.state = Some(s.request_review()) } } } trait State { fn request_review(self: Box<Self>) -> Box<dyn State>; } struct Draft {} impl State for Draft { fn request_review(self: Box<Self>) -> Box<dyn State> { Box::new(PendingReview {}) } } struct PendingReview {} impl State for PendingReview { fn request_review(self: Box<Self>) -> Box<dyn State> { self } } }
Листинг 18-15: Реализация методов request_review для Post и трейта State
Мы даем Post публичный метод request_review, который будет принимать изменяемую ссылку на self. Затем мы вызываем внутренний метод request_review для текущего состояния Post, и этот второй метод request_review потребляет текущее состояние и возвращает новое состояние.
Мы добавляем метод request_review в трейт State; все типы, реализующие этот трейт, теперь должны будут реализовать метод request_review. Обратите внимание, что вместо того, чтобы иметь self, &self или &mut self в качестве первого параметра метода, мы имеем self: Box<Self>. Этот синтаксис означает, что метод действителен только при вызове на Box, содержащем тип. Этот синтаксис забирает владение Box<Self>, делая недействительным старое состояние, чтобы значение состояния Post могло преобразоваться в новое состояние.
Чтобы потребить старое состояние, методу request_review нужно взять владение значением состояния. Здесь пригождается Option в поле state структуры Post: мы вызываем метод take, чтобы извлечь значение Some из поля state и оставить None на его месте, потому что Rust не позволяет нам иметь незаполненные поля в структурах. Это позволяет нам переместить значение состояния из Post, а не заимствовать его. Затем мы установим значение состояния записи в результат этой операции.
Нам нужно временно установить state в None, а не устанавливать его напрямую с помощью кода типа self.state = self.state.request_review();, чтобы получить владение значением состояния. Это гарантирует, что Post не сможет использовать старое значение состояния после того, как мы преобразовали его в новое состояние.
Метод request_review для Draft возвращает новый упакованный экземпляр новой структуры PendingReview, которая представляет состояние, когда запись ожидает рецензирования. Структура PendingReview также реализует метод request_review, но не выполняет никаких преобразований. Вместо этого она возвращает себя, потому что когда мы запрашиваем рецензирование для записи, уже находящейся в состоянии PendingReview, она должна остаться в состоянии PendingReview.
Теперь мы начинаем видеть преимущества шаблона состояния: метод request_review для Post одинаков независимо от значения его состояния. Каждое состояние отвечает за свои собственные правила.
Мы оставим метод content в Post как есть, возвращающий пустой строковый срез. Теперь мы можем иметь Post в состоянии PendingReview, а также в состоянии Draft, но мы хотим одинаковое поведение в состоянии PendingReview. Листинг 18-11 теперь работает до второго вызова assert_eq!!
Добавление approve для изменения поведения content
Метод approve будет похож на метод request_review: он установит state в значение, которое должно быть у текущего состояния, когда это состояние утверждено, как показано в листинге 18-16.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Post { // --snip-- pub fn approve(&mut self) { if let Some(s) = self.state.take() { self.state = Some(s.approve()) } } } trait State { fn request_review(self: Box<Self>) -> Box<dyn State>; fn approve(self: Box<Self>) -> Box<dyn State>; } struct Draft {} impl State for Draft { // --snip-- fn approve(self: Box<Self>) -> Box<dyn State> { self } } struct PendingReview {} impl State for PendingReview { // --snip-- fn approve(self: Box<Self>) -> Box<dyn State> { Box::new(Published {}) } } struct Published {} impl State for Published { fn request_review(self: Box<Self>) -> Box<dyn State> { self } fn approve(self: Box<Self>) -> Box<dyn State> { self } } }
Листинг 18-16: Реализация метода approve для Post и трейта State
Мы добавляем метод approve в трейт State и добавляем новую структуру, реализующую State - состояние Published.
Подобно тому, как работает request_review для PendingReview, если мы вызовем метод approve для Draft, это не будет иметь эффекта, потому что approve вернет self. Когда мы вызываем approve для PendingReview, он возвращает новый упакованный экземпляр структуры Published. Структура Published реализует трейт State, и для обоих методов request_review и approve возвращает себя, потому что запись должна оставаться в состоянии Published в этих случаях.
Теперь нам нужно обновить метод content для Post. Мы хотим, чтобы значение, возвращаемое из content, зависело от текущего состояния Post, поэтому мы поручим Post делегировать методу content, определенному в его состоянии, как показано в листинге 18-17.
Файл: src/lib.rs
#![allow(unused)] fn main() { // Этот код не компилируется! impl Post { // --snip-- pub fn content(&self) -> &str { self.state.as_ref().unwrap().content(self) } // --snip-- } }
Листинг 18-17: Обновление метода content в Post для делегирования методу content в State
Поскольку цель состоит в том, чтобы держать все эти правила внутри структур, реализующих State, мы вызываем метод content для значения в state и передаем экземпляр записи (то есть self) в качестве аргумента. Затем мы возвращаем значение, которое возвращается из использования метода content для значения состояния.
Мы вызываем метод as_ref для Option, потому что хотим получить ссылку на значение внутри Option, а не владение значением. Поскольку state имеет тип Option<Box<dyn State>>, когда мы вызываем as_ref, возвращается Option<&Box<dyn State>>. Если бы мы не вызвали as_ref, мы получили бы ошибку, потому что не можем переместить state из заимствованного &self параметра функции.
Затем мы вызываем метод unwrap, который, как мы знаем, никогда не вызовет панику, потому что мы знаем, что методы в Post гарантируют, что state всегда будет содержать значение Some, когда эти методы завершатся. Это один из случаев, о которых мы говорили в разделе "Когда у вас больше информации, чем у компилятора" в Главе 9, когда мы знаем, что значение None никогда невозможно, даже если компилятор не может это понять.
В этот момент, когда мы вызываем content на &Box<dyn State>, приведение разыменования (deref coercion) подействует на & и Box, так что метод content в конечном итоге будет вызван для типа, реализующего трейт State. Это означает, что нам нужно добавить content в определение трейта State, и именно там мы разместим логику для определения того, какой контент возвращать в зависимости от того, какое состояние у нас есть, как показано в листинге 18-18.
Файл: src/lib.rs
#![allow(unused)] fn main() { trait State { // --snip-- fn content<'a>(&self, post: &'a Post) -> &'a str { "" } } // --snip-- struct Published {} impl State for Published { // --snip-- fn content<'a>(&self, post: &'a Post) -> &'a str { &post.content } } }
Листинг 18-18: Добавление метода content в трейт State
Мы добавляем реализацию по умолчанию для метода content, которая возвращает пустой строковый срез. Это означает, что нам не нужно реализовывать content для структур Draft и PendingReview. Структура Published переопределит метод content и вернет значение из post.content. Хотя это удобно, наличие метода content в State, определяющего содержимое Post, размывает границы ответственности между State и Post.
Обратите внимание, что нам нужны аннотации времени жизни для этого метода, как мы обсуждали в Главе 10. Мы берем ссылку на запись в качестве аргумента и возвращаем ссылку на часть этой записи, поэтому время жизни возвращаемой ссылки связано с временем жизни аргумента записи.
И мы закончили - весь листинг 18-11 теперь работает! Мы реализовали шаблон состояния с правилами рабочего процесса записи блога. Логика, связанная с правилами, живет в объектах состояний, а не разбросана по всему Post.
Почему не перечисление?
Вы могли задаться вопросом, почему мы не использовали перечисление с различными возможными состояниями записи в качестве вариантов. Это certainly возможное решение; попробуйте его и сравните конечные результаты, чтобы увидеть, что вам больше нравится! Один недостаток использования перечисления заключается в том, что каждое место, которое проверяет значение перечисления, будет нуждаться в выражении
matchили подобном, чтобы обработать каждый возможный вариант. Это может стать более повторяющимся, чем это решение с трейт-объектами.
Оценка шаблона состояния
Мы показали, что Rust способен реализовать объектно-ориентированный шаблон состояния для инкапсуляции различных видов поведения, которые запись должна иметь в каждом состоянии. Методы в Post ничего не знают о различных поведениях. Благодаря тому, как мы организовали код, нам нужно смотреть только в одно место, чтобы узнать о различных способах поведения опубликованной записи: реализацию трейта State для структуры Published.
Если бы мы создали альтернативную реализацию, которая не использует шаблон состояния, мы могли бы вместо этого использовать выражения match в методах Post или даже в основном коде, который проверяет состояние записи и изменяет поведение в этих местах. Это означало бы, что нам пришлось бы смотреть в несколько мест, чтобы понять все последствия нахождения записи в опубликованном состоянии.
С шаблоном состояния методы Post и места, где мы используем Post, не нуждаются в выражениях match, и чтобы добавить новое состояние, нам нужно только добавить новую структуру и реализовать методы трейта для этой одной структуры в одном месте.
Реализация с использованием шаблона состояния легко расширяется для добавления дополнительной функциональности. Чтобы увидеть простоту поддержки кода, использующего шаблон состояния, попробуйте несколько из этих предложений:
- Добавьте метод
reject, который изменяет состояние записи сPendingReviewобратно наDraft. - Требуйте два вызова
approveперед тем, как состояние может быть изменено наPublished. - Разрешите пользователям добавлять текстовое содержимое только тогда, когда запись находится в состоянии
Draft. Подсказка: пусть объект состояния отвечает за то, что может измениться в содержимом, но не отвечает за изменениеPost.
Один недостаток шаблона состояния заключается в том, что, поскольку состояния реализуют переходы между состояниями, некоторые состояния связаны друг с другом. Если мы добавим другое состояние между PendingReview и Published, такое как Scheduled, нам придется изменить код в PendingReview для перехода к Scheduled вместо этого. Было бы меньше работы, если бы PendingReview не нужно было изменять с добавлением нового состояния, но это означало бы переход к другому шаблону проектирования.
Другой недостаток заключается в том, что мы продублировали некоторую логику. Чтобы устранить некоторое дублирование, мы могли бы попытаться сделать реализации по умолчанию для методов request_review и approve в трейте State, которые возвращают self. Однако это не сработает: при использовании State как трейт-объекта, трейт не знает, каким именно будет конкретный self, поэтому тип возвращаемого значения неизвестен во время компиляции. (Это одно из правил совместимости с dyn, упомянутых ранее.)
Другое дублирование включает похожие реализации методов request_review и approve в Post. Оба метода используют Option::take с полем state структуры Post, и если state является Some, они делегируют реализации того же метода в обернутом значении и устанавливают новое значение поля state в результат. Если бы у нас было много методов в Post, которые следуют этому шаблону, мы могли бы рассмотреть возможность определения макроса для устранения повторения (см. раздел "Макросы" в Главе 20).
Реализуя шаблон состояния точно так, как он определен для объектно-ориентированных языков, мы не используем все преимущества Rust в полной мере. Давайте посмотрим на некоторые изменения, которые мы можем внести в крейт blog, чтобы сделать недопустимые состояния и переходы ошибками времени компиляции.
Кодирование состояний и поведения как типов
Мы покажем вам, как переосмыслить шаблон состояния, чтобы получить другой набор компромиссов. Вместо того чтобы полностью инкапсулировать состояния и переходы, чтобы внешний код не имел о них знаний, мы закодируем состояния в разные типы. Следовательно, система проверки типов Rust предотвратит попытки использования черновиков записей там, где разрешены только опубликованные записи, выдавая ошибку компилятора.
Давайте рассмотрим первую часть main из листинга 18-11:
Файл: src/main.rs
fn main() { let mut post = Post::new(); post.add_text("I ate a salad for lunch today"); assert_eq!("", post.content()); }
Мы все еще разрешаем создание новых записей в состоянии черновика с помощью Post::new и возможность добавлять текст в содержимое записи. Но вместо того, чтобы иметь метод content для черновика записи, который возвращает пустую строку, мы сделаем так, чтобы черновики записей вообще не имели метода content. Таким образом, если мы попытаемся получить содержимое черновика записи, мы получим ошибку компилятора, сообщающую, что метод не существует. В результате мы не сможем случайно отобразить содержимое черновика записи в рабочей среде, потому что этот код даже не скомпилируется. Листинг 18-19 показывает определение структуры Post и структуры DraftPost, а также методы для каждой.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct Post { content: String, } pub struct DraftPost { content: String, } impl Post { pub fn new() -> DraftPost { DraftPost { content: String::new(), } } pub fn content(&self) -> &str { &self.content } } impl DraftPost { pub fn add_text(&mut self, text: &str) { self.content.push_str(text); } } }
Листинг 18-19: Post с методом content и DraftPost без метода content
И структура Post, и структура DraftPost имеют приватное поле content, в котором хранится текст записи блога. Структуры больше не имеют поля state, потому что мы перемещаем кодирование состояния в типы структур. Структура Post будет представлять опубликованную запись и имеет метод content, который возвращает содержимое.
У нас все еще есть функция Post::new, но вместо возврата экземпляра Post она возвращает экземпляр DraftPost. Поскольку content является приватным и нет никаких функций, возвращающих Post, сейчас невозможно создать экземпляр Post.
Структура DraftPost имеет метод add_text, поэтому мы можем добавлять текст в content как и раньше, но обратите внимание, что в DraftPost не определен метод content! Теперь программа гарантирует, что все записи начинаются как черновики, и черновики записей не имеют доступного для отображения содержимого. Любая попытка обойти эти ограничения приведет к ошибке компилятора.
Итак, как мы получаем опубликованную запись? Мы хотим обеспечить правило, что черновик записи должен быть рецензирован и утвержден перед публикацией. Запись в состоянии ожидания рецензии все еще не должна отображать какое-либо содержимое. Давайте реализуем эти ограничения, добавив еще одну структуру PendingReviewPost, определив метод request_review в DraftPost для возврата PendingReviewPost и определив метод approve в PendingReviewPost для возврата Post, как показано в листинге 18-20.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl DraftPost { // --snip-- pub fn request_review(self) -> PendingReviewPost { PendingReviewPost { content: self.content, } } } pub struct PendingReviewPost { content: String, } impl PendingReviewPost { pub fn approve(self) -> Post { Post { content: self.content, } } } }
Листинг 18-20: PendingReviewPost, создаваемый вызовом request_review на DraftPost, и метод approve, превращающий PendingReviewPost в опубликованный Post
Методы request_review и approve принимают владение self, таким образом потребляя экземпляры DraftPost и PendingReviewPost и преобразуя их в PendingReviewPost и опубликованный Post соответственно. Таким образом, у нас не останется никаких экземпляров DraftPost после вызова request_review на них и так далее. Для структуры PendingReviewPost не определен метод content, поэтому попытка прочитать его содержимое приводит к ошибке компилятора, как и с DraftPost. Поскольку единственный способ получить экземпляр опубликованного Post, у которого определен метод content, - это вызвать метод approve на PendingReviewPost, а единственный способ получить PendingReviewPost - это вызвать метод request_review на DraftPost, мы теперь закодировали рабочий процесс записи блога в систему типов.
Но мы также должны внести некоторые небольшие изменения в main. Методы request_review и approve возвращают новые экземпляры, а не изменяют структуру, для которой они вызываются, поэтому нам нужно добавить больше переназначающих let post = присваиваний для сохранения возвращенных экземпляров. Мы также не можем иметь утверждения о том, что содержимое черновиков и записей на рецензии являются пустыми строками, и нам это не нужно: мы больше не можем компилировать код, который пытается использовать содержимое записей в этих состояниях. Обновленный код в main показан в листинге 18-21.
Файл: src/main.rs
use blog::Post; fn main() { let mut post = Post::new(); post.add_text("I ate a salad for lunch today"); let post = post.request_review(); let post = post.approve(); assert_eq!("I ate a salad for lunch today", post.content()); }
Листинг 18-21: Изменения в main для использования новой реализации рабочего процесса записи блога
Изменения, которые нам нужно было внести в main для переназначения post, означают, что эта реализация больше не совсем следует объектно-ориентированному шаблону состояния: преобразования между состояниями больше не инкапсулированы полностью внутри реализации Post. Однако наша выгода в том, что недопустимые состояния теперь невозможны благодаря системе типов и проверке типов, которая происходит во время компиляции! Это гарантирует, что определенные ошибки, такие как отображение содержимого неопубликованной записи, будут обнаружены до того, как они попадут в рабочую среду.
Попробуйте выполнить задачи, предложенные в начале этого раздела, для крейта blog в том виде, в котором он находится после листинга 18-21, чтобы понять, что вы думаете о дизайне этой версии кода. Обратите внимание, что некоторые задачи могут быть уже выполнены в этом дизайне.
Мы видели, что даже though Rust способен реализовать объектно-ориентированные шаблоны проектирования, другие шаблоны, такие как кодирование состояния в систему типов, также доступны в Rust. Эти шаблоны имеют разные компромиссы. Хотя вы можете быть очень familiar с объектно-ориентированными шаблонами, переосмысление проблемы для использования преимуществ функций Rust может предоставить benefits, такие как предотвращение некоторых ошибок во время компиляции. Объектно-ориентированные шаблоны не всегда будут лучшим решением в Rust из-за определенных функций, таких как владение, которых нет в объектно-ориентированных языках.
Итоги
Независимо от того, считаете ли вы Rust объектно-ориентированным языком после прочтения этой главы, вы теперь знаете, что можете использовать трейт-объекты для получения некоторых объектно-ориентированных функций в Rust. Динамическая диспетчеризация может дать вашему коду некоторую гибкость в обмен на небольшую потерю производительности во время выполнения. Вы можете использовать эту гибкость для реализации объектно-ориентированных шаблонов, которые могут помочь поддерживаемости вашего кода. У Rust также есть другие функции, такие как владение, которых нет в объектно-ориентированных языках. Объектно-ориентированный шаблон не всегда будет лучшим способом использовать сильные стороны Rust, но это доступная опция.
Далее мы рассмотрим шаблоны (patterns), которые являются еще одной особенностью Rust, обеспечивающей большую гибкость. Мы кратко рассматривали их на протяжении всей книги, но еще не видели их полную возможность. Начнем!
Глава 19
Паттерны и сопоставление
Паттерны — это специальный синтаксис в Rust для сопоставления со структурой типов, как сложных, так и простых. Использование паттернов вместе с выражениями match и другими конструкциями даёт вам больше контроля над потоком управления программы. Паттерн состоит из комбинации следующих элементов:
- Литералы
- Деструктурированные массивы, перечисления, структуры или кортежи
- Переменные
- Подстановочные знаки (wildcards)
- Заполнители (placeholders)
Некоторые примеры паттернов включают x, (a, 3) и Some(Color::Red). В контекстах, где паттерны допустимы, эти компоненты описышают форму данных. Затем наша программа сопоставляет значения с паттернами, чтобы определить, соответствуют ли данные требуемой форме для продолжения выполнения определённого фрагмента кода.
Чтобы использовать паттерн, мы сравниваем его с некоторым значением. Если паттерн совпадает со значением, мы используем части этого значения в нашем коде. Вспомните выражения match из главы 6, которые использовали паттерны, такие как пример с машиной для сортировки монет. Если значение соответствует форме паттерна, мы можем использовать именованные части. Если нет, код, связанный с паттерном, не выполнится.
Эта глава является справочником по всему, что связано с паттернами. Мы рассмотрим допустимые места для использования паттернов, разницу между опровержимыми и неопровержимыми паттернами и различные виды синтаксиса паттернов, которые вы можете встретить. К концу главы вы будете знать, как использовать паттерны для ясного выражения множества концепций.
Шаблоны и сопоставления
Шаблоны - это специальный синтаксис в Rust для сопоставления со структурой типов, как сложных, так и простых. Использование шаблонов в сочетании с выражениями match и другими конструкциями даёт вам больший контроль над потоком управления программы.
Шаблон состоит из некоторой комбинации следующего:
- Литералы
- Деструктурированные массивы, перечисления, структуры или кортежи
- Переменные
- Специальные символы
- Заполнители
Чтобы использовать шаблон, мы сравниваем его с некоторым значением. Если шаблон соответствует значению, мы используем части значения в нашем дальнейшем коде.
Все места, где можно использовать паттерны
Паттерны встречаются в нескольких местах в Rust, и вы уже много раз использовали их, не осознавая этого! В этом разделе обсуждаются все места, где допустимо использование паттернов.
Ветки match
Как обсуждалось в главе 6, мы используем паттерны в ветках выражений match. Формально выражения match определяются как ключевое слово match, значение, с которым происходит сопоставление, и одна или несколько веток match, которые состоят из паттерна и выражения, выполняемого в случае, если значение соответствует паттерну этой ветки, как показано ниже:
#![allow(unused)] fn main() { match ЗНАЧЕНИЕ { ПАТТЕРН => ВЫРАЖЕНИЕ, ПАТТЕРН => ВЫРАЖЕНИЕ, ПАТТЕРН => ВЫРАЖЕНИЕ, } }
Например, рассмотрим выражение match из листинга 6-5, которое сопоставляется со значением Option<i32> в переменной x:
#![allow(unused)] fn main() { match x { None => None, Some(i) => Some(i + 1), } }
Паттернами в этом выражении match являются None и Some(i) слева от каждой стрелки.
Одним из требований к выражениям match является то, что они должны быть исчерпывающими (exhaustive), в том смысле, что все возможные варианты значения в выражении match должны быть обработаны. Один из способов обеспечить это — иметь универсальный паттерн для последней ветки: например, имя переменной, которое сопоставляется с любым значением, никогда не может завершиться неудачей и, таким образом, покрывает все оставшиеся случаи.
Конкретный паттерн _ будет соответствовать чему угодно, но он никогда не привязывается к переменной, поэтому его часто используют в последней ветке match. Паттерн _ может быть полезен, когда вы хотите проигнорировать любое значение, не указанное ранее. Мы подробнее рассмотрим паттерн _ далее в этой главе, в разделе «Игнорирование значений в паттерне».
Операторы let
До этой главы мы явно обсуждали использование паттернов только с match и if let, но на самом деле мы также использовали паттерны и в других местах, включая операторы let. Например, рассмотрим простое присваивание переменной с помощью let:
#![allow(unused)] fn main() { let x = 5; }
Каждый раз, когда вы использовали оператор let таким образом, вы использовали паттерны, хотя, возможно, не осознавали этого! Более формально оператор let выглядит так:
#![allow(unused)] fn main() { let ПАТТЕРН = ВЫРАЖЕНИЕ; }
В таких инструкциях, как let x = 5;, где в позиции ПАТТЕРНА находится имя переменной, это имя переменной представляет собой просто особо простую форму паттерна. Rust сравнивает выражение с паттерном и присваивает имена, которые он находит. Таким образом, в примере let x = 5; x — это паттерн, который означает «связать то, что совпадает здесь, с переменной x». Поскольку имя x является целым паттерном, этот паттерн фактически означает «связать всё с переменной x, независимо от значения».
Чтобы более ясно увидеть аспект сопоставления с паттерном в let, рассмотрим листинг 19-1, который использует паттерн с let для деструктуризации кортежа.
#![allow(unused)] fn main() { let (x, y, z) = (1, 2, 3); }
Листинг 19-1: Использование паттерна для деструктуризации кортежа и создания трёх переменных одновременно
Здесь мы сопоставляем кортеж с паттерном. Rust сравнивает значение (1, 2, 3) с паттерном (x, y, z) и видит, что значение соответствует паттерну — то есть видит, что количество элементов в обоих случаях одинаково, — поэтому Rust связывает 1 с x, 2 с y и 3 с z. Вы можете думать об этом паттерне кортежа как о трёх отдельных паттернах переменных, вложенных в него.
Если количество элементов в паттерне не совпадает с количеством элементов в кортеже, общие типы не совпадут, и мы получим ошибку компилятора. Например, в листинге 19-2 показана попытка деструктуризировать кортеж с тремя элементами в две переменные, которая не сработает.
#![allow(unused)] fn main() { // [Этот код не компилируется!] let (x, y) = (1, 2, 3); }
Листинг 19-2: Некорректное построение паттерна, переменные которого не соответствуют количеству элементов в кортеже
Попытка скомпилировать этот код приводит к ошибке типа:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Чтобы исправить ошибку, мы можем проигнорировать одно или несколько значений в кортеже с помощью _ или .., как вы увидите в разделе «Игнорирование значений в паттерне». Если проблема в том, что у нас слишком много переменных в паттерне, решение — привести типы в соответствие, удалив переменные так, чтобы количество переменных равнялось количеству элементов в кортеже.
Условные выражения if let
В главе 6 мы обсуждали, как использовать выражения if let в основном как более краткий способ написания эквивалента match, который обрабатывает только один случай. При необходимости, if let может иметь соответствующий else, содержащий код для выполнения, если паттерн в if let не совпадает.
В листинге 19-3 показано, что также можно комбинировать выражения if let, else if и else if let. Это даёт нам больше гибкости, чем выражение match, в котором мы можем выразить только одно значение для сравнения с паттернами. Кроме того, Rust не требует, чтобы условия в серии из if let, else if и else if let были связаны друг с другом.
Код в листинге 19-3 определяет, какой цвет установить для фона на основе серии проверок нескольких условий. Для этого примера мы создали переменные с жёстко заданными значениями, которые реальная программа могла бы получить из пользовательского ввода.
Файл: src/main.rs
fn main() { let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse(); if let Some(color) = favorite_color { println!("Используем ваш любимый цвет {color} как цвет фона"); } else if is_tuesday { println!("Вторник — день зелёного цвета!"); } else if let Ok(age) = age { if age > 30 { println!("Используем фиолетовый как цвет фона"); } else { println!("Используем оранжевый как цвет фона"); } } else { println!("Используем синий как цвет фона"); } }
Листинг 19-3: Комбинирование if let, else if, else if let и else
Если пользователь указывает любимый цвет, этот цвет используется как фон. Если любимый цвет не указан и сегодня вторник, цвет фона — зелёный. В противном случае, если пользователь указывает свой возраст в виде строки и мы можем успешно распарсить его как число, цвет будет фиолетовым или оранжевым в зависимости от значения числа. Если ни одно из этих условий не применимо, цвет фона — синий.
Такая условная структура позволяет нам поддерживать сложные требования. С имеющимися у нас жёстко заданными значениями этот пример напечатает Используем фиолетовый как цвет фона.
Вы можете видеть, что if let также может вводить новые переменные, которые затеняют существующие переменные, точно так же, как это могут делать ветки match: строка if let Ok(age) = age вводит новую переменную age, которая содержит значение внутри варианта Ok, затеняя существующую переменную age. Это означает, что нам нужно поместить условие if age > 30 внутри этого блока: мы не можем объединить эти два условия в if let Ok(age) = age && age > 30. Новая переменная age, которую мы хотим сравнить с 30, не действительна до начала новой области видимости с фигурной скобкой.
Недостатком использования выражений if let является то, что компилятор не проверяет исчерпываемость (exhaustiveness), в отличие от выражений match. Если бы мы опустили последний блок else и тем самым пропустили обработку некоторых случаев, компилятор не предупредил бы нас о возможной логической ошибке.
Условные циклы while let
По структуре похожий на if let, условный цикл while let позволяет циклу while выполняться до тех пор, пока паттерн продолжает совпадать. В листинге 19-4 мы показываем цикл while let, который ожидает сообщения, отправленные между потоками, но в данном случае проверяет Result, а не Option.
#![allow(unused)] fn main() { let (tx, rx) = std::sync::mpsc::channel(); std::thread::spawn(move || { for val in [1, 2, 3] { tx.send(val).unwrap(); } }); while let Ok(value) = rx.recv() { println!("{value}"); } }
Листинг 19-4: Использование цикла while let для вывода значений, пока rx.recv() возвращает Ok
Этот пример выводит 1, 2, а затем 3. Метод recv извлекает первое сообщение с приёмной стороны канала и возвращает Ok(value). Когда мы впервые увидели recv в главе 16, мы либо напрямую разворачивали ошибку, либо работали с ним как с итератором с помощью цикла for. Однако, как показывает листинг 19-4, мы также можем использовать while let, потому что метод recv возвращает Ok при каждом поступлении сообщения (пока существует отправитель), а затем возвращает Err, когда сторона отправителя отключается.
Циклы for
В цикле for значение, которое следует непосредственно за ключевым словом for, является паттерном. Например, в конструкции for x in y элемент x — это паттерн. В листинге 19-5 показано, как использовать паттерн в цикле for для деструктуризации (или разбора) кортежа как части цикла.
#![allow(unused)] fn main() { let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{value} is at index {index}"); } }
Листинг 19-5: Использование паттерна в цикле for для деструктуризации кортежа
Код из листинга 19-5 выведет следующее:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Мы адаптируем итератор с помощью метода enumerate, чтобы он генерировал значение и индекс для этого значения, помещённые в кортеж. Первое сгенерированное значение — это кортеж (0, 'a'). Когда это значение сопоставляется с паттерном (index, value), index будет равен 0, а value будет 'a', что приводит к выводу первой строки результата.
Параметры функций
Параметры функций также могут быть паттернами. Код в листинге 19-6, который объявляет функцию с именем foo, принимающую один параметр x типа i32, уже должен выглядеть знакомо.
#![allow(unused)] fn main() { fn foo(x: i32) { // код функции } }
Листинг 19-6: Сигнатура функции, использующая паттерны в параметрах
Часть x — это паттерн! Как мы делали с let, мы можем сопоставить кортеж в аргументах функции с паттерном. Листинг 19-7 разделяет значения кортежа при передаче его в функцию.
Файл: src/main.rs
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({x}, {y})"); } fn main() { let point = (3, 5); print_coordinates(&point); }
Листинг 19-7: Функция с параметрами, которые деструктурируют кортеж
Этот код выводит Current location: (3, 5). Значения &(3, 5) соответствуют паттерну &(x, y), поэтому x получает значение 3, а y — значение 5.
Мы также можем использовать паттерны в списках параметров замыканий таким же образом, как и в списках параметров функций, поскольку замыкания похожи на функции, как обсуждалось в главе 13.
На этом этапе вы увидели несколько способов использования паттернов, но паттерны работают не одинаково во всех местах, где мы можем их использовать. В некоторых местах паттерны должны быть неопровержимыми (irrefutable); в других обстоятельствах они могут быть опровержимыми (refutable). Далее мы обсудим эти два понятия.
Опровержимость: может ли паттерн не совпасть
Паттерны бывают двух форм: опровержимые (refutable) и неопровержимые (irrefutable). Паттерны, которые будут совпадать с любым возможным переданным значением, являются неопровержимыми. Примером может служить x в инструкции let x = 5;, потому что x совпадает с чем угодно и, следовательно, не может не совпасть. Паттерны, которые могут не совпасть для некоторых возможных значений, являются опровержимыми. Примером может служить Some(x) в выражении if let Some(x) = a_value, потому что если значение в переменной a_value — None, а не Some, паттерн Some(x) не совпадёт.
Параметры функций, инструкции let и циклы for могут принимать только неопровержимые паттерны, потому что программа не может сделать ничего осмысленного, когда значения не совпадают. Выражения if let и while let, а также инструкция let...else принимают как опровержимые, так и неопровержимые паттерны, но компилятор предупреждает о неопровержимых паттернах, потому что, по определению, они предназначены для обработки возможных неудач: функциональность условной конструкции заключается в её способности действовать по-разному в зависимости от успеха или неудачи.
В общем случае вам не следует беспокоиться о различии между опровержимыми и неопровержимыми паттернами; однако вам нужно быть знакомым с концепцией опровержимости, чтобы вы могли реагировать, когда видите её в сообщении об ошибке. В таких случаях вам нужно будет изменить либо паттерн, либо конструкцию, в которой вы используете паттерн, в зависимости от предполагаемого поведения кода.
Давайте рассмотрим пример того, что происходит, когда мы пытаемся использовать опровержимый паттерн там, где Rust требует неопровержимый паттерн, и наоборот. В листинге 19-8 показана инструкция let, но в качестве паттерна мы указали Some(x) — опровержимый паттерн. Как вы могли ожидать, этот код не скомпилируется.
#![allow(unused)] fn main() { // [Этот код не компилируется!] let Some(x) = some_option_value; }
Листинг 19-8: Попытка использования опровержимого паттерна с let
Если бы some_option_value было значением None, оно не совпало бы с паттерном Some(x), что означает, что паттерн является опровержимым. Однако инструкция let может принимать только неопровержимый паттерн, потому что код не может сделать ничего допустимого со значением None. Во время компиляции Rust пожалуется, что мы попытались использовать опровержимый паттерн там, где требуется неопровержимый паттерн:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Поскольку мы не покрыли (и не могли покрыть!) каждое допустимое значение паттерном Some(x), Rust обоснованно выдаёт ошибку компиляции.
Если у нас есть опровержимый паттерн там, где нужен неопровержимый паттерн, мы можем исправить это, изменив код, который использует паттерн: вместо использования let мы можем использовать let else. Тогда, если паттерн не совпадет, код просто пропустит код в фигурных скобках, предоставив ему возможность продолжить выполнение допустимым образом. Листинг 19-9 показывает, как исправить код из листинга 19-8.
#![allow(unused)] fn main() { let Some(x) = some_option_value else { return; }; }
Листинг 19-9: Использование let...else и блока с опровержимыми паттернами вместо let
Мы предоставили коду запасной выход! Этот код абсолютно корректен, хотя это означает, что мы не можем использовать неопровержимый паттерн без получения предупреждения. Если мы дадим let...else паттерн, который всегда будет совпадать, такой как x, как показано в листинге 19-10, компилятор выдаст предупреждение.
#![allow(unused)] fn main() { let x = 5 else { return; }; }
Листинг 19-10: Попытка использования неопровержимого паттерна с let...else
Rust сообщает, что не имеет смысла использовать let...else с неопровержимым паттерном:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
По этой причине ветки match должны использовать опровержимые паттерны, за исключением последней ветки, которая должна сопоставлять любые оставшиеся значения с неопровержимым паттерном. Rust позволяет нам использовать неопровержимый паттерн в match только с одной веткой, но этот синтаксис не особенно полезен и может быть заменён более простой инструкцией let.
Теперь, когда вы знаете, где использовать паттерны и разницу между опровержимыми и неопровержимыми паттернами, давайте рассмотрим весь синтаксис, который мы можем использовать для создания паттернов.
Синтакс паттернов
В этом разделе мы соберём весь синтаксис, допустимый в паттернах, и обсудим, почему и когда вам может понадобиться использовать каждый из них.
Сопоставление с литералами
Как вы видели в главе 6, вы можете напрямую сопоставлять паттерны с литералами. Следующий код приводит несколько примеров:
#![allow(unused)] fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
Этот код выводит one, потому что значение в x равно 1. Этот синтаксис полезен, когда вы хотите, чтобы ваш код выполнил действие при получении определённого конкретного значения.
Сопоставление с именованными переменными
Именованные переменные — это неопровержимые паттерны, которые совпадают с любым значением, и мы много раз использовали их в этой книге. Однако есть сложность, когда вы используете именованные переменные в выражениях match, if let или while let. Поскольку каждый из этих видов выражений начинает новую область видимости, переменные, объявленные как часть паттерна внутри этих выражений, будут затенять переменные с тем же именем вне этих конструкций, как это бывает со всеми переменными. В листинге 19-11 мы объявляем переменную x со значением Some(5) и переменную y со значением 10. Затем мы создаём выражение match для значения x. Посмотрите на паттерны в ветках match и макрос println! в конце и попробуйте понять, что напечатает код, прежде чем запускать его или читать дальше.
Файл: src/main.rs
#![allow(unused)] fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
Листинг 19-11: Выражение match с веткой, которая вводит новую переменную, затеняющую существующую переменную y
Давайте разберём, что происходит при выполнении выражения match. Паттерн в первой ветке match не совпадает с определённым значением x, поэтому код продолжается.
Паттерн во второй ветке match вводит новую переменную с именем y, которая будет соответствовать любому значению внутри варианта Some. Поскольку мы находимся в новой области видимости внутри выражения match, это новая переменная y, а не та y, которую мы объявили в начале со значением 10. Эта новая привязка y будет соответствовать любому значению внутри Some, что и есть в нашем x. Следовательно, эта новая y связывается с внутренним значением Some в x. Это значение равно 5, поэтому выполняется выражение для этой ветки и выводится Matched, y = 5.
Если бы x было значением None вместо Some(5), паттерны в первых двух ветках не совпали бы, поэтому значение совпало бы с подчёркиванием. Мы не вводили переменную x в паттерне ветки с подчёркиванием, поэтому x в выражении остаётся внешней x, которая не была затенена. В этом гипотетическом случае match напечатал бы Default case, x = None.
Когда выражение match завершается, его область видимости заканчивается, а вместе с ней и область видимости внутренней y. Последний println! выводит at the end: x = Some(5), y = 10.
Чтобы создать выражение match, которое сравнивает значения внешних x и y, вместо введения новой переменной, которая затеняет существующую переменную y, нам нужно использовать вместо этого ограничитель шаблона (match guard). Мы поговорим об ограничителях шаблона позже, в разделе «Добавление условий с помощью ограничителей шаблона».
Сопоставление с несколькими паттернами
В выражениях match вы можете сопоставлять несколько паттернов, используя синтаксис |, который представляет оператор или. Например, в следующем коде мы сопоставляем значение x с ветками match, первая из которых имеет вариант с или, означающий, что если значение x совпадает с любым из значений в этой ветке, код этой ветки выполнится:
#![allow(unused)] fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
Этот код выводит one or two.
Сопоставление с диапазонами значений с помощью ..=
Синтаксис ..= позволяет нам сопоставляться с включительным диапазоном значений. В следующем коде, когда паттерн совпадает с любым из значений в заданном диапазоне, эта ветка выполнится:
#![allow(unused)] fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
Если x равен 1, 2, 3, 4 или 5, первая ветка совпадёт. Этот синтаксис удобнее для нескольких сопоставляемых значений, чем использование оператора | для выражения той же идеи; если бы мы использовали |, нам пришлось бы указать 1 | 2 | 3 | 4 | 5. Указание диапазона намного короче, особенно если мы хотим сопоставить, скажем, любое число от 1 до 1000!
Компилятор проверяет, что диапазон не пуст во время компиляции, и поскольку единственные типы, для которых Rust может определить, пуст диапазон или нет, — это char и числовые значения, диапазоны разрешены только с числовыми или символьными значениями.
Вот пример использования диапазонов символьных значений:
#![allow(unused)] fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust может определить, что 'c' находится в пределах первого диапазона паттерна, и выводит early ASCII letter.
Деструктуризация для разбора значений
Мы также можем использовать паттерны для деструктуризации структур, перечислений и кортежей, чтобы использовать отдельные части этих значений. Давайте рассмотрим каждый тип значений.
Структуры (Structs)
В листинге 19-12 показана структура Point с двумя полями, x и y, которую мы можем разобрать с помощью паттерна в инструкции let.
Файл: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
Листинг 19-12: Деструктуризация полей структуры в отдельные переменные
Этот код создаёт переменные a и b, которые соответствуют значениям полей x и y структуры p. Этот пример показывает, что имена переменных в паттерне не обязаны совпадать с именами полей структуры. Однако обычно имена переменных совпадают с именами полей, чтобы было легче запомнить, какие переменные из каких полей получены. Из-за этого распространённого использования и поскольку запись let Point { x: x, y: y } = p; содержит много дублирования, в Rust есть сокращённая запись для паттернов, сопоставляющихся с полями структур: вам нужно только перечислить имена полей структуры, а создаваемые переменные будут иметь те же имена. Листинг 19-13 ведёт себя так же, как код в листинге 19-12, но переменные, созданные в паттерне let, — это x и y вместо a и b.
Файл: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
Листинг 19-13: Деструктуризация полей структуры с использованием сокращённой записи
Этот код создаёт переменные x и y, которые соответствуют полям x и y переменной p. В результате переменные x и y содержат значения из структуры p.
Мы также можем использовать литеральные значения как часть паттерна структуры вместо создания переменных для всех полей. Это позволяет нам проверить некоторые поля на соответствие определённым значениям, создавая переменные для деструктуризации других полей.
В листинге 19-14 у нас есть выражение match, которое разделяет значения Point на три случая: точки, которые лежат непосредственно на оси x (что верно, когда y = 0), на оси y (x = 0) или ни на одной из осей.
Файл: src/main.rs
fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
Листинг 19-14: Деструктуризация и сопоставление с литеральными значениями в одном паттерне
Первая ветка будет соответствовать любой точке, лежащей на оси x, указывая, что поле y совпадает, если его значение совпадает с литералом 0. Паттерн всё равно создаёт переменную x, которую мы можем использовать в коде этой ветки.
Аналогично, вторая ветка соответствует любой точке на оси y, указывая, что поле x совпадает, если его значение равно 0, и создаёт переменную y для значения поля y. Третья ветка не указывает никаких литералов, поэтому она соответствует любой другой точке Point и создаёт переменные для обоих полей x и y.
В этом примере значение p соответствует второй ветке благодаря тому, что x содержит 0, поэтому этот код напечатает On the y axis at 7.
Помните, что выражение match прекращает проверку веток после нахождения первого совпадающего паттерна, поэтому даже если Point { x: 0, y: 0} находится и на оси x, и на оси y, этот код напечатал бы только On the x axis at 0.
Перечисления (Enums)
Мы деструктуризировали перечисления в этой книге (например, листинг 6-5 в главе 6), но ещё не обсуждали явно, что паттерн для деструктуризации перечисления соответствует способу определения данных, хранящихся внутри перечисления. В качестве примера в листинге 19-15 мы используем перечисление Message из листинга 6-2 и пишем match с паттернами, которые деструктуризируют каждое внутреннее значение.
Файл: src/main.rs
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!("Move in the x direction {x} and in the y direction {y}"); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => { println!("Change color to red {r}, green {g}, and blue {b}"); } } }
Листинг 19-15: Деструктуризация вариантов перечисления, содержащих разные kinds of values
Этот код напечатает Change color to red 0, green 160, and blue 255. Попробуйте изменить значение msg, чтобы увидеть выполнение кода из других веток.
Для вариантов перечисления без данных, таких как Message::Quit, мы не можем деструктуризировать значение дальше. Мы можем только сопоставить с литеральным значением Message::Quit, и в этом паттерне нет переменных.
Для вариантов перечисления, подобных структурам, таких как Message::Move, мы можем использовать паттерн, аналогичный тому, который мы указываем для сопоставления со структурами. После имени варианта мы помещаем фигурные скобки и затем перечисляем поля с переменными, чтобы разобрать части для использования в коде этой ветки. Здесь мы используем сокращённую форму, как мы делали в листинге 19-13.
Для вариантов перечисления, подобных кортежам, таких как Message::Write, который содержит кортеж с одним элементом, и Message::ChangeColor, который содержит кортеж с тремя элементами, паттерн аналогичен тому, который мы указываем для сопоставления с кортежами. Количество переменных в паттерне должно соответствовать количеству элементов в варианте, с которым мы сопоставляем.
Вложенные структуры и перечисления
До сих пор наши примеры сопоставлялись со структурами или перечислениями на одном уровне, но сопоставление может работать и с вложенными элементами! Например, мы можем переработать код из листинга 19-15 для поддержки цветов RGB и HSV в сообщении ChangeColor, как показано в листинге 19-16.
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!("Change color to hue {h}, saturation {s}, value {v}"); } _ => (), } }
Листинг 19-16: Сопоставление с вложенными перечислениями
Паттерн первой ветки в выражении match сопоставляется с вариантом перечисления Message::ChangeColor, который содержит вариант Color::Rgb; затем паттерн связывается с тремя внутренними значениями i32. Паттерн второй ветки также сопоставляется с вариантом Message::ChangeColor, но внутреннее перечисление соответствует Color::Hsv. Мы можем задать эти сложные условия в одном выражении match, даже though задействованы два перечисления.
Структуры и кортежи
Мы можем смешивать, сочетать и вкладывать паттерны деструктуризации ещё более сложными способами. Следующий пример показывает сложную деструктуризацию, где мы вкладываем структуры и кортежи внутри кортежа и извлекаем все примитивные значения:
#![allow(unused)] fn main() { let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
Этот код позволяет нам разбивать сложные типы на их составные части, чтобы мы могли использовать интересующие нас значения по отдельности.
Деструктуризация с помощью паттернов — это удобный способ использовать части значений, такие как значение из каждого поля структуры, по отдельности друг от друга.
Игнорирование значений в паттерне
Вы видели, что иногда полезно игнорировать значения в паттерне, например, в последней ветке match, чтобы получить универсальный обработчик, который ничего не делает, но учитывает все оставшиеся возможные значения. Есть несколько способов игнорировать целые значения или части значений в паттерне: использование паттерна _ (который вы уже видели), использование _ внутри другого паттерна, использование имени, начинающегося с подчёркивания, или использование .. для игнорирования оставшихся частей значения. Давайте рассмотрим, как и почему использовать каждый из этих паттернов.
Игнорирование всего значения с помощью _
Мы использовали подчёркивание как подстановочный паттерн, который будет соответствовать любому значению, но не привязываться к нему. Это особенно полезно в качестве последней ветки в выражении match, но мы также можем использовать его в любом паттерне, включая параметры функций, как показано в листинге 19-17.
Файл: src/main.rs
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {y}"); } fn main() { foo(3, 4); }
Листинг 19-17: Использование _ в сигнатуре функции
Этот код полностью проигнорирует значение 3, переданное в качестве первого аргумента, и напечатает This code only uses the y parameter: 4.
В большинстве случаев, когда вам больше не нужен определённый параметр функции, вы должны изменить сигнатуру, чтобы она не включала неиспользуемый параметр. Игнорирование параметра функции может быть особенно полезно в случаях, когда, например, вы реализуете трейт, требующий определённой сигнатуры типа, но телу функции в вашей реализации не нужен один из параметров. Таким образом вы избежите предупреждения компилятора о неиспользуемых параметрах функции, которое получили бы, если бы использовали имя.
Игнорирование частей значения с помощью вложенного _
Мы также можем использовать _ внутри другого паттерна, чтобы игнорировать только часть значения, например, когда мы хотим проверить только часть значения, но не используем другие части в соответствующем коде. Листинг 19-18 показывает код, отвечающий за управление значением настройки. Бизнес-требования заключаются в том, что пользователю не должно быть разрешено перезаписывать существующую customization настройки, но он может сбросить настройку и задать ей значение, если она в данный момент не установлена.
#![allow(unused)] fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {setting_value:?}"); }
Листинг 19-18: Использование подчёркивания внутри паттернов, соответствующих вариантам Some, когда нам не нужно использовать значение внутри Some
Этот код напечатает Can't overwrite an existing customized value, а затем setting is Some(5). В первой ветке match нам не нужно сопоставлять или использовать значения внутри вариантов Some, но нам нужно проверить случай, когда setting_value и new_setting_value являются вариантом Some. В этом случае мы печатаем причину, по которой не меняем setting_value, и оно не изменяется.
Во всех других случаях (если либо setting_value, либо new_setting_value является None), выраженных паттерном _ во второй ветке, мы хотим разрешить new_setting_value стать setting_value.
Мы также можем использовать подчёркивания в нескольких местах внутри одного паттерна, чтобы игнорировать определённые значения. Листинг 19-19 показывает пример игнорирования второго и четвёртого значений в кортеже из пяти элементов.
#![allow(unused)] fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}"); } } }
Листинг 19-19: Игнорирование нескольких частей кортежа
Этот код напечатает Some numbers: 2, 8, 32, а значения 4 и 16 будут проигнорированы.
Неиспользуемая переменная с именем, начинающимся с _
Если вы создаёте переменную, но нигде её не используете, Rust обычно выдаёт предупреждение, потому что неиспользуемая переменная может быть ошибкой. Однако иногда бывает полезно создать переменную, которую вы ещё не используете, например, при прототипировании или начале проекта. В этой ситуации вы можете сказать Rust не предупреждать вас о неиспользуемой переменной, начав её имя с подчёркивания. В листинге 19-20 мы создаём две неиспользуемые переменные, но при компиляции этого кода мы должны получить предупреждение только об одной из них.
Файл: src/main.rs
fn main() { let _x = 5; let y = 10; }
Листинг 19-20: Начало имени переменной с подчёркивания, чтобы избежать предупреждений о неиспользуемой переменной
Здесь мы получаем предупреждение о неиспользовании переменной y, но не получаем предупреждения о неиспользовании _x.
Обратите внимание, что есть subtle разница между использованием просто _ и использованием имени, начинающегося с подчёркивания. Синтаксис _x всё ещё привязывает значение к переменной, тогда как _ вообще не привязывает. Чтобы показать случай, где это различие важно, листинг 19-21 выдаст нам ошибку.
#![allow(unused)] fn main() { // [Этот код не компилируется!] let s = Some(String::from("Hello!")); if let Some(_s) = s { println!("found a string"); } println!("{s:?}"); }
Листинг 19-21: Неиспользуемая переменная, начинающаяся с подчёркивания, всё равно привязывает значение, что может забрать владение значением.
Мы получим ошибку, потому что значение s будет перемещено в _s, что мешает нам использовать s снова. Однако использование самого подчёркивания никогда не привязывает значение. Листинг 19-22 скомпилируется без ошибок, потому что s не перемещается в _.
#![allow(unused)] fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{s:?}"); }
Листинг 19-22: Использование подчёркивания не привязывает значение.
Этот код работает исправно, потому что мы никогда не привязываем s к чему-либо; оно не перемещается.
Игнорирование оставшихся частей значения с помощью ..
Для значений со многими частями мы можем использовать синтаксис .., чтобы использовать определённые части и игнорировать остальные, избегая необходимости перечислять подчёркивания для каждого игнорируемого значения. Паттерн .. игнорирует любые части значения, которые мы явно не сопоставили в остальной части паттерна. В листинге 19-23 у нас есть структура Point, которая хранит координату в трёхмерном пространстве. В выражении match мы хотим работать только с координатой x и игнорировать значения в полях y и z.
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {x}"), } }
Листинг 19-23: Игнорирование всех полей Point, кроме x, с помощью ..
Мы указываем значение x, а затем просто включаем паттерн ... Это быстрее, чем перечислять y: _ и z: _, особенно когда мы работаем со структурами, имеющими много полей, в ситуациях, где relevant только одно или два поля.
Синтаксис .. будет расширяться на столько значений, сколько нужно. Листинг 19-24 показывает, как использовать .. с кортежем.
Файл: src/main.rs
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
Листинг 19-24: Сопоставление только первого и последнего значений в кортеже и игнорирование всех других значений
В этом коде первое и последнее значения сопоставляются с first и last. .. совпадёт и проигнорирует всё, что находится посередине.
Однако использование .. должно быть однозначным. Если неясно, какие значения предназначены для сопоставления, а какие следует игнорировать, Rust выдаст нам ошибку. Листинг 19-25 показывает пример неоднозначного использования .., поэтому он не скомпилируется.
Файл: src/main.rs
// [Этот код не компилируется!] fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (.., second, ..) => { println!("Some numbers: {second}") }, } }
Листинг 19-25: Попытка использовать .. неоднозначным способом
При компиляции этого примера мы получаем ошибку:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Rust не может определить, сколько значений в кортеже нужно игнорировать перед сопоставлением значения с second, а затем сколько ещё значений игнорировать после этого. Этот код может означать, что мы хотим проигнорировать 2, привязать second к 4, а затем игнорировать 8, 16 и 32; или что мы хотим игнорировать 2 и 4, привязать second к 8, а затем игнорировать 16 и 32; и так далее. Имя переменной second не означает ничего особенного для Rust, поэтому мы получаем ошибку компиляции, поскольку использование .. в двух местах подобным образом неоднозначно.
Добавление условий с помощью ограничителей шаблона (Match Guards)
Ограничитель шаблона (match guard) — это дополнительное условие if, указываемое после паттерна в ветке match, которое также должно выполняться для выбора этой ветки. Ограничители шаблона полезны для выражения более сложных идей, чем позволяет один только паттерн. Однако обратите внимание, что они доступны только в выражениях match, а не в выражениях if let или while let.
Условие может использовать переменные, созданные в паттерне. Листинг 19-26 показывает match, в котором первая ветка имеет паттерн Some(x) и также имеет ограничитель шаблона if x % 2 == 0 (который будет истинным, если число чётное).
#![allow(unused)] fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {x} is even"), Some(x) => println!("The number {x} is odd"), None => (), } }
Листинг 19-26: Добавление ограничителя шаблона к паттерну
Этот пример напечатает The number 4 is even. Когда num сравнивается с паттерном в первой ветке, он совпадает, потому что Some(4) соответствует Some(x). Затем ограничитель шаблона проверяет, равен ли остаток от деления x на 2 нулю, и поскольку это так, выбирается первая ветка.
Если бы num было Some(5), ограничитель шаблона в первой ветке был бы ложным, потому что остаток от деления 5 на 2 равен 1, что не равно 0. Rust тогда перешёл бы ко второй ветке, которая совпала бы, потому что у второй ветки нет ограничителя шаблона и, следовательно, она соответствует любому варианту Some.
Невозможно выразить условие if x % 2 == 0 внутри паттерна, поэтому ограничитель шаблона даёт нам возможность выразить эту логику. Недостатком этой дополнительной выразительности является то, что компилятор не пытается проверять исчерпываемость, когда задействованы выражения ограничителей шаблона.
Обсуждая листинг 19-11, мы упомянули, что можем использовать ограничители шаблона для решения нашей проблемы затенения паттерна. Напомним, что мы создали новую переменную внутри паттерна в выражении match вместо использования переменной вне match. Эта новая переменная означала, что мы не могли проверить значение внешней переменной. Листинг 19-27 показывает, как мы можем использовать ограничитель шаблона, чтобы исправить эту проблему.
Файл: src/main.rs
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
Листинг 19-27: Использование ограничителя шаблона для проверки равенства с внешней переменной
Теперь этот код напечатает Default case, x = Some(5). Паттерн во второй ветке match не вводит новую переменную y, которая затеняла бы внешнюю y, meaning мы можем использовать внешнюю y в ограничителе шаблона. Вместо того чтобы указывать паттерн как Some(y), который затенял бы внешнюю y, мы указываем Some(n). Это создаёт новую переменную n, которая ничего не затеняет, поскольку вне match нет переменной n.
Ограничитель шаблона if n == y не является паттерном и, следовательно, не вводит новые переменные. Этот y — внешний y, а не новый y, затеняющий его, и мы можем искать значение, которое имеет то же значение, что и внешний y, сравнивая n с y.
Вы также можете использовать оператор или (|) в ограничителе шаблона для указания нескольких паттернов; условие ограничителя шаблона будет применяться ко всем паттернам. Листинг 19-28 показывает приоритет при комбинировании паттерна, использующего |, с ограничителем шаблона. Важная часть этого примера заключается в том, что ограничитель if y применяется к 4, 5 и 6, даже though может показаться, что if y применяется только к 6.
#![allow(unused)] fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
Листинг 19-28: Комбинирование нескольких паттернов с ограничителем шаблона
Условие сопоставления гласит, что ветка совпадает только если значение x равно 4, 5 или 6 И если y истинно. При выполнении этого кода паттерн первой ветки совпадает, потому что x равно 4, но ограничитель шаблона if y ложен, поэтому первая ветка не выбирается. Код переходит ко второй ветке, которая совпадает, и эта программа печатает no. Причина в том, что условие if применяется ко всему паттерну 4 | 5 | 6, а не только к последнему значению 6. Другими словами, приоритет ограничителя шаблона по отношению к паттерну ведёт себя так:
#![allow(unused)] fn main() { (4 | 5 | 6) if y => ... }
а не так:
#![allow(unused)] fn main() { 4 | 5 | (6 if y) => ... }
После выполнения кода поведение приоритета становится очевидным: если бы ограничитель шаблона применялся только к конечному значению в списке значений, указанном с помощью оператора |, ветка совпала бы, и программа напечатала бы yes.
Использование привязок @
Оператор @ (at) позволяет нам создать переменную, которая хранит значение, в то же время проверяя это значение на соответствие паттерну. В листинге 19-29 мы хотим проверить, что поле id в Message::Hello находится в диапазоне 3..=7. Мы также хотим привязать значение к переменной id_variable, чтобы использовать его в коде, связанном с веткой.
#![allow(unused)] fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7 } => { println!("Found an id in range: {id_variable}") } Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {id}"), } }
Листинг 19-29: Использование @ для привязки значения в паттерне с одновременной проверкой
Этот пример напечатает Found an id in range: 5. Указывая id_variable @ перед диапазоном 3..=7, мы захватываем любое значение, совпавшее с диапазоном, в переменную id_variable, одновременно проверяя, что значение соответствует паттерну диапазона.
Во второй ветке, где у нас указан только диапазон в паттерне, код, связанный с веткой, не имеет переменной, содержащей фактическое значение поля id. Значение поля id могло быть 10, 11 или 12, но код, соответствующий этому паттерну, не знает, какое именно. Код паттерна не может использовать значение из поля id, потому что мы не сохранили значение id в переменной.
В последней ветке, где мы указали переменную без диапазона, у нас есть значение, доступное для использования в коде ветки в переменной id. Причина в том, что мы использовали сокращённый синтаксис полей структуры. Но мы не применили никакой проверки к значению поля id в этой ветке, как мы это сделали в первых двух ветках: любое значение будет соответствовать этому паттерну.
Использование @ позволяет нам проверить значение и сохранить его в переменной в рамках одного паттерна.
Итог
Паттерны в Rust очень полезны для различения разных видов данных. При использовании в выражениях match Rust гарантирует, что ваши паттерны покрывают все возможные значения, иначе ваша программа не скомпилируется. Паттерны в операторах let и параметрах функций делают эти конструкции более полезными, позволяя деструктуризировать значения на более мелкие части и присваивать эти части переменным. Мы можем создавать простые или сложные паттерны в соответствии с нашими потребностями.
Далее, в предпоследней главе книги, мы рассмотрим некоторые продвинутые аспекты различных возможностей Rust.
Расширенные функции Rust
К этому моменту вы уже изучили наиболее часто используемые части языка программирования Rust. Прежде чем мы перейдём к очередному проекту в главе 21, мы рассмотрим некоторые аспекты языка, с которыми вы можете сталкиваться время от времени, но, возможно, не используете каждый день. Вы можете использовать эту главу в качестве справочника, когда столкнётесь с чем-то неизвестным. Возможности, рассматриваемые здесь, полезны в очень специфических ситуациях. Хотя вы, возможно, будете прибегать к ним нечасто, мы хотим убедиться, что вы понимаете все возможности, которые Rust может предложить.
В этой главе мы рассмотрим:
- Небезопасный Rust: Как отказаться от некоторых гарантий Rust и взять на себя ответственность за ручное обеспечение этих гарантий
- Продвинутые трейты: Ассоциированные типы, параметры типа по умолчанию, полностью квалифицированный синтаксис, супертрейты и шаблон "newtype" применительно к трейтам
- Продвинутые типы: Подробнее о шаблоне "newtype", псевдонимах типов, типе
neverи динамически sized типах (типах с динамическим размером) - Продвинутые функции и замыкания: Указатели на функции и возвращение замыканий
- Макросы: Способы определения кода, который генерирует больше кода во время компиляции
Здесь представлена целая панорама возможностей Rust, где каждый найдёт что-то для себя! Давайте начнём!
Небезопасный Rust
Весь код, который мы обсуждали до сих пор, имел гарантии безопасности памяти Rust, обеспечиваемые во время компиляции. Однако в Rust скрыт второй язык, который не обеспечивает эти гарантии безопасности памяти: он называется небезопасный Rust и работает так же, как обычный Rust, но даёт нам дополнительные сверхспособности.
Небезопасный Rust существует потому, что по своей природе статический анализ консервативен. Когда компилятор пытается определить, соблюдает ли код гарантии, лучше отклонить некоторые допустимые программы, чем принять некоторые некорректные. Хотя код может быть в порядке, если у компилятора Rust недостаточно информации для уверенности, он отклонит код. В таких случаях вы можете использовать небезопасный код, чтобы сказать компилятору: «Доверься мне, я знаю, что делаю». Однако будьте осторожны: вы используете небезопасный Rust на свой страх и риск: если вы используете небезопасный код неправильно, могут возникнуть проблемы due to нарушения безопасности памяти, такие как разыменование нулевого указателя.
Другая причина существования небезопасной alter ego в Rust заключается в том, что базовое компьютерное оборудование по своей природе небезопасно. Если бы Rust не позволял вам выполнять небезопасные операции, вы не могли бы выполнять определённые задачи. Rust должен позволять вам заниматься низкоуровневым системным программированием, таким как прямое взаимодействие с операционной системой или даже написание собственной операционной системы. Работа с низкоуровневым системным программированием является одной из целей языка. Давайте explore, что мы можем делать с небезопасным Rust и как это делать.
Использование небезопасных сверхспособностей
Чтобы переключиться на небезопасный Rust, используйте ключевое слово unsafe и затем начните новый блок, содержащий небезопасный код. Вы можете выполнять пять действий в небезопасном Rust, которые нельзя делать в безопасном Rust, и мы называем их небезопасными сверхспособностями. Эти сверхспособности включают возможность:
- Разыменовывать сырой указатель (raw pointer)
- Вызывать небезопасную функцию или метод
- Получать доступ или изменять изменяемую статическую переменную (mutable static variable)
- Реализовывать небезопасный трейт (unsafe trait)
- Получать доступ к полям объединений (unions)
Важно понимать, что unsafe не отключает проверку заимствований (borrow checker) и не отключает какие-либо другие проверки безопасности Rust: если вы используете ссылку в небезопасном коде, она всё равно будет проверяться. Ключевое слово unsafe только даёт вам доступ к этим пяти возможностям, которые затем не проверяются компилятором на безопасность памяти. Вы всё равно получите некоторую степень безопасности внутри небезопасного блока.
Кроме того, unsafe не означает, что код внутри блока обязательно опасен или что он точно будет иметь проблемы с безопасностью памяти: цель в том, что вы, как программист, обеспечите, чтобы код внутри небезопасного блока обращался к памяти допустимым образом.
Люди подвержены ошибкам, и ошибки будут происходить, но благодаря требованию размещать эти пять небезопасных операций внутри блоков с пометкой unsafe, вы будете знать, что любые ошибки, связанные с безопасностью памяти, должны находиться внутри небезопасного блока. Держите небезопасные блоки небольшими; вы будете благодарны позже, когда будете исследовать ошибки памяти.
Чтобы максимально изолировать небезопасный код, лучше всего заключать такой код в безопасную абстракцию и предоставлять безопасный API, что мы обсудим позже в главе при рассмотрении небезопасных функций и методов. Части стандартной библиотеки реализованы как безопасные абстракции над проверенным небезопасным кодом. Обёртывание небезопасного кода в безопасную абстракцию предотвращает распространение использования unsafe во все места, где вы или ваши пользователи можете захотеть использовать функциональность, реализованную с помощью небезопасного кода, поскольку использование безопасной абстракции является безопасным.
Давайте рассмотрим каждую из пяти небезопасных сверхспособностей по очереди. Мы также рассмотрим некоторые абстракции, которые предоставляют безопасный интерфейс для небезопасного кода.
Разыменование сырого указателя (Raw Pointer)
В главе 4, в разделе «Висячие ссылки», мы упоминали, что компилятор гарантирует, что ссылки всегда действительны. Небезопасный Rust имеет два новых типа, называемых сырыми указателями (raw pointers), которые похожи на ссылки. Как и ссылки, сырые указатели могут быть неизменяемыми или изменяемыми и записываются как *const T и *mut T соответственно. Звёздочка не является оператором разыменования; это часть имени типа. В контексте сырых указателей «неизменяемый» означает, что указатель не может быть напрямую присвоен после разыменования.
В отличие от ссылок и умных указателей, сырые указатели:
- Могут игнорировать правила заимствования, имея одновременно неизменяемые и изменяемые указатели или несколько изменяемых указателей на одно и то же место
- Не гарантируют, что указывают на допустимую память
- Могут быть null
- Не реализуют автоматическое очищение (automatic cleanup)
Отказываясь от принудительного соблюдения этих гарантий в Rust, вы можете пожертвовать гарантированной безопасностью в обмен на большую производительность или возможность взаимодействия с другим языком или оборудованием, где гарантии Rust не применимы.
В листинге 20-1 показано, как создать неизменяемый и изменяемый сырой указатель.
#![allow(unused)] fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; }
Листинг 20-1: Создание сырых указателей с помощью операторов сырого заимствования
Обратите внимание, что мы не включаем ключевое слово unsafe в этот код. Мы можем создавать сырые указатели в безопасном коде; мы просто не можем разыменовывать сырые указатели вне небезопасного блока, как вы увидите далее.
Мы создали сырые указатели, используя операторы сырого заимствования: &raw const num создаёт неизменяемый сырой указатель *const i32, а &raw mut num создаёт изменяемый сырой указатель *mut i32. Поскольку мы создали их непосредственно из локальной переменной, мы знаем, что эти конкретные сырые указатели действительны, но мы не можем делать такое предположение о любом произвольном сыром указателе.
Чтобы продемонстрировать это, далее мы создадим сырой указатель, в достоверности которого мы не можем быть так уверены, используя ключевое слово as для приведения значения вместо использования оператора сырого заимствования. В листинге 20-2 показано, как создать сырой указатель на произвольное место в памяти. Попытка использования произвольной памяти является неопределённым поведением: по этому адресу могут быть данные или нет, компилятор может оптимизировать код так, что доступ к памяти не произойдёт, или программа может завершиться с ошибкой сегментации. Обычно нет веской причины писать такой код, особенно в случаях, когда вместо этого можно использовать оператор сырого заимствования, но это возможно.
#![allow(unused)] fn main() { let address = 0x012345usize; let r = address as *const i32; }
Листинг 20-2: Создание сырого указателя на произвольный адрес памяти
Напомним, что мы можем создавать сырые указатели в безопасном коде, но мы не можем разыменовывать сырые указатели и читать данные, на которые они указывают. В листинге 20-3 мы используем оператор разыменования * на сыром указателе, что требует небезопасного блока.
#![allow(unused)] fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
Листинг 20-3: Разыменование сырых указателей внутри небезопасного блока
Создание указателя не приносит вреда; только когда мы пытаемся получить доступ к значению, на которое он указывает, мы можем столкнуться с недопустимым значением.
Также обратите внимание, что в листингах 20-1 и 20-3 мы создали сырые указатели *const i32 и *mut i32, которые оба указывают на одно и то же место в памяти, где хранится num. Если бы мы попытались создать неизменяемую и изменяемую ссылку на num, код не скомпилировался бы, потому что правила владения Rust не позволяют изменяемую ссылку одновременно с любыми неизменяемыми ссылками. С сырыми указателями мы можем создать изменяемый указатель и неизменяемый указатель на одно и то же место и изменять данные через изменяемый указатель, потенциально создавая состояние гонки данных (data race). Будьте осторожны!
Со всеми этими опасностями, зачем вообще использовать сырые указатели? Один из основных случаев использования — при взаимодействии с кодом на C, как вы увидите в следующем разделе. Другой случай — при построении безопасных абстракций, которые проверщик заимствований не понимает. Мы представим небезопасные функции, а затем рассмотрим пример безопасной абстракции, которая использует небезопасный код.
Вызов небезопасной функции или метода
Второй тип операции, который можно выполнять в небезопасном блоке, — вызов небезопасных функций. Небезопасные функции и методы выглядят точно так же, как обычные функции и методы, но у них есть дополнительное ключевое слово unsafe перед остальной частью определения. Ключевое слово unsafe в этом контексте указывает, что функция имеет требования, которые мы должны соблюдать при её вызове, потому что Rust не может гарантировать, что мы выполнили эти требования. Вызывая небезопасную функцию внутри небезопасного блока, мы заявляем, что прочитали документацию этой функции и берём на себя ответственность за соблюдение контракта функции.
Вот небезопасная функция с именем dangerous, которая ничего не делает в своём теле:
#![allow(unused)] fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
Мы должны вызывать функцию dangerous в отдельном небезопасном блоке. Если мы попытаемся вызвать dangerous без небезопасного блока, мы получим ошибку:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
С небезопасным блоком мы утверждаем Rust, что прочитали документацию функции, понимаем, как её правильно использовать, и проверили, что выполняем контракт функции.
Для выполнения небезопасных операций в теле небезопасной функции вам всё равно нужно использовать небезопасный блок, так же как в обычной функции, и компилятор предупредит вас, если вы забудете. Это помогает нам сохранять небезопасные блоки как можно меньше, поскольку небезопасные операции могут быть нужны не во всём теле функции.
Создание безопасной абстракции над небезопасным кодом
Тот факт, что функция содержит небезопасный код, не означает, что нам нужно помечать всю функцию как unsafe. На самом деле, обёртывание небезопасного кода в безопасную функцию является распространённой абстракцией. В качестве примера давайте изучим функцию split_at_mut из стандартной библиотеки, которая требует некоторого небезопасного кода. Мы исследуем, как мы могли бы её реализовать. Этот безопасный метод определён для изменяемых срезов: он берёт один срез и разделяет его на два, разбивая срез по индексу, заданному в качестве аргумента. В листинге 20-4 показано, как использовать split_at_mut.
#![allow(unused)] fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
Листинг 20-4: Использование безопасной функции split_at_mut
Мы не можем реализовать эту функцию, используя только безопасный Rust. Попытка может выглядеть примерно как в листинге 20-5, который не скомпилируется. Для простоты мы реализуем split_at_mut как функцию, а не метод, и только для срезов значений i32, а не для обобщённого типа T.
#![allow(unused)] fn main() { // [Этот код не компилируется!] fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); assert!(mid <= len); (&mut values[..mid], &mut values[mid..]) } }
Листинг 20-5: Попытка реализации split_at_mut с использованием только безопасного Rust
Эта функция сначала получает общую длину среза. Затем она проверяет, что индекс, заданный в качестве параметра, находится within среза, проверяя, меньше ли он или равен длине. Проверка означает, что если мы передадим индекс, превышающий длину для разделения среза, функция вызовет панику до попытки использования этого индекса.
Затем мы возвращаем два изменяемых среза в кортеже: один от начала исходного среза до индекса mid и другой от mid до конца среза.
Когда мы пытаемся скомпилировать код из листинга 20-5, мы получаем ошибку:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Проверщик заимствований Rust не может понять, что мы заимствуем разные части среза; он знает только, что мы заимствуем из одного и того же среза дважды. Заимствование разных частей среза fundamentally допустимо, потому что два среза не перекрываются, но Rust недостаточно умен, чтобы это знать. Когда мы знаем, что код корректен, но Rust — нет, настало время обратиться к небезопасному коду.
В листинге 20-6 показано, как использовать небезопасный блок, сырой указатель и некоторые вызовы небезопасных функций, чтобы реализовать split_at_mut.
#![allow(unused)] fn main() { use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } }
Листинг 20-6: Использование небезопасного кода в реализации функции split_at_mut
Вспомните из раздела «Тип срез» в главе 4, что срез — это указатель на некоторые данные и длина среза. Мы используем метод len для получения длины среза и метод as_mut_ptr для доступа к сырому указателю среза. В этом случае, поскольку у нас есть изменяемый срез значений i32, as_mut_ptr возвращает сырой указатель типа *mut i32, который мы сохранили в переменной ptr.
Мы сохраняем проверку, что индекс mid находится within среза. Затем мы переходим к небезопасному коду: функция slice::from_raw_parts_mut принимает сырой указатель и длину и создаёт срез. Мы используем эту функцию для создания среза, который начинается с ptr и имеет длину mid элементов. Затем мы вызываем метод add на ptr с аргументом mid, чтобы получить сырой указатель, начинающийся с mid, и создаём срез, используя этот указатель и оставшееся количество элементов после mid в качестве длины.
Функция slice::from_raw_parts_mut является небезопасной, потому что она принимает сырой указатель и должна доверять, что этот указатель действителен. Метод add для сырых указателей также небезопасен, потому что он должен доверять, что смещённое расположение также является действительным указателем. Поэтому нам пришлось поместить небезопасный блок вокруг наших вызовов slice::from_raw_parts_mut и add, чтобы мы могли их вызвать. Глядя на код и добавляя проверку, что mid должен быть меньше или равен len, мы можем сказать, что все сырые указатели, используемые в небезопасном блоке, будут действительными указателями на данные within среза. Это допустимое и уместное использование unsafe.
Обратите внимание, что нам не нужно помечать результирующую функцию split_at_mut как unsafe, и мы можем вызывать эту функцию из безопасного Rust. Мы создали безопасную абстракцию для небезопасного кода с реализацией функции, которая использует небезопасный код безопасным образом, потому что она создаёт только действительные указатели из данных, к которым эта функция имеет доступ.
В отличие от этого, использование slice::from_raw_parts_mut в листинге 20-7, вероятно, приведёт к сбою при использовании среза. Этот код берёт произвольное место в памяти и создаёт срез длиной 10 000 элементов.
#![allow(unused)] fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Листинг 20-7: Создание среза из произвольного места в памяти
Мы не владеем памятью по этому произвольному адресу, и нет гарантии, что срез, созданный этим кодом, содержит действительные значения i32. Попытка использовать values как будто это действительный срез приводит к неопределённому поведению.
Использование внешних функций для вызова внешнего кода
Иногда вашему коду на Rust может потребоваться взаимодействовать с кодом, написанным на другом языке. Для этого в Rust есть ключевое слово extern, которое облегчает создание и использование внешнего функционального интерфейса (Foreign Function Interface, FFI) — это способ для языка программирования определять функции и позволять другому (внешнему) языку программирования вызывать эти функции.
В листинге 20-8 демонстрируется, как настроить интеграцию с функцией abs из стандартной библиотеки C. Функции, объявленные внутри блоков extern, как правило, небезопасно вызывать из кода Rust, поэтому блоки extern также должны быть помечены как unsafe. Причина в том, что другие языки не применяют правила и гарантии Rust, и Rust не может их проверить, поэтому ответственность за обеспечение безопасности ложится на программиста.
Файл: src/main.rs
unsafe extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
Листинг 20-8: Объявление и вызов внешней функции, определённой на другом языке
Внутри блока unsafe extern "C" мы перечисляем имена и сигнатуры внешних функций из другого языка, которые хотим вызывать. Часть "C" определяет, какой двоичный интерфейс приложения (application binary interface, ABI) использует внешняя функция: ABI определяет, как вызывать функцию на уровне ассемблера. ABI "C" является наиболее распространённым и следует ABI языка программирования C. Информация обо всех ABI, которые поддерживает Rust, доступна в Rust Reference.
Каждый элемент, объявленный внутри блока unsafe extern, неявно является небезопасным. Однако некоторые FFI-функции безопасно вызывать. Например, функция abs из стандартной библиотеки C не имеет каких-либо соображений безопасности памяти, и мы знаем, что её можно вызывать с любым i32. В таких случаях мы можем использовать ключевое слово safe, чтобы указать, что эту конкретную функцию безопасно вызывать, даже если она находится в небезопасном блоке extern. После этого изменения её вызов больше не требует небезопасного блока, как показано в листинге 20-9.
Файл: src/main.rs
unsafe extern "C" { safe fn abs(input: i32) -> i32; } fn main() { println!("Absolute value of -3 according to C: {}", abs(-3)); }
Листинг 20-9: Явное помечение функции как безопасной внутри небезопасного блока extern и её безопасный вызов
Помечение функции как safe не делает её по своей природе безопасной! Вместо этого это похоже на обещание, которое вы даёте Rust, что она безопасна. Всё равно ваша ответственность — убедиться, что это обещание выполняется!
Вызов функций Rust из других языков
Мы также можем использовать extern для создания интерфейса, который позволяет другим языкам вызывать функции Rust. Вместо создания целого блока extern мы добавляем ключевое слово extern и указываем ABI непосредственно перед ключевым словом fn для соответствующей функции. Нам также нужно добавить аннотацию #[unsafe(no_mangle)], чтобы сообщить компилятору Rust не искажать имя этой функции. Искажение имён (mangling) — это когда компилятор изменяет данное нами имя функции на другое имя, которое содержит больше информации для использования другими частями процесса компиляции, но является менее читаемым для человека.
Каждый компилятор языка программирования слегка по-разному искажает имена, поэтому чтобы функция Rust могла быть вызвана из других языков, мы должны отключить искажение имён в компиляторе Rust. Это небезопасно, потому что без встроенного искажения имён могут возникать конфликты имён между библиотеками, поэтому наша ответственность — убедиться, что выбранное нами имя безопасно для экспорта без искажения.
В следующем примере мы делаем функцию call_from_c доступной для вызова из кода на C после её компиляции в shared library и линковки из C:
#![allow(unused)] fn main() { #[unsafe(no_mangle)] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }
Это использование extern требует unsafe только в атрибуте, а не в блоке extern.
Доступ или изменение изменяемой статической переменной
В этой книге мы ещё не говорили о глобальных переменных, которые Rust поддерживает, но которые могут быть проблематичными с точки зрения правил владения Rust. Если два потока обращаются к одной и той же изменяемой глобальной переменной, это может вызвать состояние гонки данных (data race).
В Rust глобальные переменные называются статическими переменными (static variables). В листинге 20-10 показан пример объявления и использования статической переменной со строковым срезом в качестве значения.
Файл: src/main.rs
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("value is: {HELLO_WORLD}"); }
Листинг 20-10: Определение и использование неизменяемой статической переменной
Статические переменные похожи на константы, которые мы обсуждали в разделе «Объявление констант» в главе 3. Имена статических переменных по соглашению записываются в SCREAMING_SNAKE_CASE. Статические переменные могут хранить только ссылки с временем жизни 'static, что означает, что компилятор Rust может определить время жизни самостоятельно, и нам не требуется аннотировать его явно. Доступ к неизменяемой статической переменной является безопасным.
Тонкое различие между константами и неизменяемыми статическими переменными заключается в том, что значения в статической переменной имеют фиксированный адрес в памяти. Использование значения всегда будет обращаться к одним и тем же данным. Константы, с другой стороны, могут дублировать свои данные при каждом использовании. Другое отличие состоит в том, что статические переменные могут быть изменяемыми. Доступ и изменение изменяемых статических переменных является небезопасным. В листинге 20-11 показано, как объявить, получить доступ и изменить изменяемую статическую переменную с именем COUNTER.
Файл: src/main.rs
static mut COUNTER: u32 = 0; /// БЕЗОПАСНОСТЬ: Вызов этой функции более чем из одного потока одновременно /// является неопределённым поведением, поэтому вы *должны* гарантировать, /// что вызываете её только из одного потока за раз. unsafe fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { unsafe { // БЕЗОПАСНОСТЬ: Эта функция вызывается только из одного потока в `main`. add_to_count(3); println!("COUNTER: {}", *(&raw const COUNTER)); } }
Листинг 20-11: Чтение или запись в изменяемую статическую переменную является небезопасным
Как и с обычными переменными, мы указываем изменяемость с помощью ключевого слова mut. Любой код, который читает или записывает в COUNTER, должен находиться в небезопасном блоке. Код в листинге 20-11 компилируется и выводит COUNTER: 3, как мы и ожидали, потому что он однопоточный. Если бы несколько потоков обращались к COUNTER, это, вероятно, привело бы к состоянию гонки данных, что является неопределённым поведением. Поэтому нам нужно пометить всю функцию как unsafe и задокументировать ограничения безопасности, чтобы любой, кто вызывает функцию, знал, что можно и что нельзя делать безопасно.
Каждый раз, когда мы пишем небезопасную функцию, принято писать комментарий, начинающийся с БЕЗОПАСНОСТЬ и объясняющий, что вызывающая сторона должна сделать для безопасного вызова функции. Аналогично, при выполнении небезопасной операции принято писать комментарий, начинающийся с БЕЗОПАСНОСТЬ, чтобы объяснить, как соблюдаются правила безопасности.
Кроме того, компилятор по умолчанию запрещает любые попытки создания ссылок на изменяемую статическую переменную через линту компилятора. Вы должны либо явно отказаться от защиты этой линты, добавив аннотацию #[allow(static_mut_refs)], либо обращаться к изменяемой статической переменной через сырой указатель, созданный с помощью одного из операторов сырого заимствования. Это включает случаи, когда ссылка создаётся неявно, как при использовании в макросе println! в этом примере кода. Требование создавать ссылки на статические изменяемые переменные через сырые указатели помогает сделать требования безопасности для их использования более очевидными.
При работе с изменяемыми данными, которые доступны глобально, трудно обеспечить отсутствие состояний гонки данных, поэтому Rust считает изменяемые статические переменные небезопасными. По возможности предпочтительнее использовать методы конкурентности и потокобезопасные умные указатели, которые мы обсуждали в главе 16, чтобы компилятор проверял, что доступ к данным из разных потоков осуществляется безопасно.
Реализация небезопасного трейта
Мы можем использовать unsafe для реализации небезопасного трейта. Трейт является небезопасным, когда по крайней мере один из его методов имеет некоторую инварианту, которую компилятор не может проверить. Мы объявляем трейт небезопасным, добавляя ключевое слово unsafe перед trait, и также помечаем реализацию этого трейта как unsafe, как показано в листинге 20-12.
#![allow(unused)] fn main() { unsafe trait Foo { // методы здесь } unsafe impl Foo for i32 { // реализации методов здесь } }
Листинг 20-12: Определение и реализация небезопасного трейта
Используя unsafe impl, мы гарантируем, что будем соблюдать инварианты, которые компилятор не может проверить.
В качестве примера вспомните маркерные трейты Send и Sync, которые мы обсуждали в разделе «Расширяемая конкурентность с Send и Sync» в главе 16: компилятор автоматически реализует эти трейты, если наши типы полностью состоят из других типов, которые реализуют Send и Sync. Если мы реализуем тип, который содержит тип, не реализующий Send или Sync, такой как сырые указатели, и мы хотим пометить этот тип как Send или Sync, мы должны использовать unsafe. Rust не может проверить, что наш тип соблюдает гарантии того, что его можно безопасно передавать между потоками или обращаться к нему из нескольких потоков; следовательно, нам нужно выполнить эти проверки вручную и указать это с помощью unsafe.
Доступ к полям объединения (Union)
Последнее действие, которое работает только с unsafe, — это доступ к полям объединения (union). Объединение похоже на структуру, но в конкретном экземпляре в один момент времени используется только одно объявленное поле. Объединения в основном используются для взаимодействия с объединениями в коде C. Доступ к полям объединения небезопасен, потому что Rust не может гарантировать тип данных, хранящихся в данный момент в экземпляре объединения. Вы можете узнать больше об объединениях в Rust Reference.
Использование Miri для проверки небезопасного кода
При написании небезопасного кода вы можете захотеть проверить, что написанный код действительно безопасен и корректен. Один из лучших способов сделать это — использовать Miri, официальный инструмент Rust для обнаружения неопределённого поведения. В то время как проверщик заимствований (borrow checker) — это статический инструмент, работающий во время компиляции, Miri — это динамический инструмент, работающий во время выполнения. Он проверяет ваш код, запуская вашу программу или её тестовый набор, и обнаруживает случаи, когда вы нарушаете правила, которые он понимает о том, как должен работать Rust.
Использование Miri требует ночной сборки Rust (о которой мы подробнее рассказываем в Приложении G: «Как создаётся Rust и „Ночной Rust“»). Вы можете установить как ночную версию Rust, так и инструмент Miri, набрав rustup +nightly component add miri. Это не изменяет версию Rust, которую использует ваш проект; это только добавляет инструмент в вашу систему, чтобы вы могли использовать его, когда захотите. Вы можете запустить Miri для проекта, набрав cargo +nightly miri run или cargo +nightly miri test.
В качестве примера полезности этого инструмента рассмотрим, что происходит, когда мы запускаем его для листинга 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri правильно предупреждает нас, что мы преобразуем целое число в указатель, что может быть проблемой, но Miri не может определить, существует ли проблема, потому что он не знает, как возник указатель. Затем Miri возвращает ошибку, где листинг 20-7 имеет неопределённое поведение, потому что у нас висячий указатель (dangling pointer). Благодаря Miri мы теперь знаем, что существует риск неопределённого поведения, и можем подумать о том, как сделать код безопасным. В некоторых случаях Miri может даже давать рекомендации по исправлению ошибок.
Miri не обнаруживает всё, что может быть неправильно в небезопасном коде. Miri — это инструмент динамического анализа, поэтому он обнаруживает только проблемы в коде, который фактически выполняется. Это означает, что вам нужно использовать его в сочетании с хорошими методами тестирования, чтобы повысить уверенность в написанном небезопасном коде. Miri также не охватывает все возможные способы, которыми ваш код может быть некорректным.
Другими словами: если Miri обнаруживает проблему, вы знаете, что есть ошибка, но если Miri не обнаруживает ошибку, это не значит, что проблемы нет. Тем не менее, он может обнаружить многое. Попробуйте запустить его на других примерах небезопасного кода в этой главе и посмотрите, что он скажет!
Вы можете узнать больше о Miri в его репозитории на GitHub.
Правильное использование небезопасного кода
Использование unsafe для применения одной из пяти рассмотренных сверхспособностей не является неправильным или даже порицаемым, но написание корректного небезопасного кода сложнее, потому что компилятор не может помочь обеспечить безопасность памяти. Когда у вас есть причина использовать небезопасный код, вы можете это делать, и явная аннотация unsafe облегчает отслеживание источника проблем, когда они возникают. Каждый раз, когда вы пишете небезопасный код, вы можете использовать Miri, чтобы быть более уверенным в том, что написанный код соблюдает правила Rust.
Для более глубокого изучения эффективной работы с небезопасным Rust прочитайте официальное руководство Rust по небезопасному коду — The Rustonomicon.
Продвинутые Traits
Мы впервые рассмотрели трейты в разделе «Определение общего поведения с помощью трейтов» в главе 10, но не обсуждали более продвинутые детали. Теперь, когда вы знаете больше о Rust, мы можем углубиться в подробности.
Определение трейтов с ассоциированными типами
Ассоциированные типы связывают тип-заполнитель с трейтом таким образом, что определения методов трейта могут использовать эти типы-заполнители в своих сигнатурах. Реализатор трейта укажет конкретный тип, который будет использоваться вместо типа-заполнителя для конкретной реализации. Таким образом, мы можем определить трейт, который использует некоторые типы, без необходимости точно знать, что это за типы, пока трейт не будет реализован.
Мы описали большинство продвинутых возможностей в этой главе как редко необходимые. Ассоциированные типы находятся где-то посередине: они используются реже, чем возможности, объяснённые в остальной части книги, но чаще, чем многие другие возможности, обсуждаемые в этой главе.
Одним из примеров трейта с ассоциированным типом является трейт Iterator, предоставляемый стандартной библиотекой. Ассоциированный тип называется Item и заменяет тип значений, которые тип, реализующий трейт Iterator, перебирает. Определение трейта Iterator показано в листинге 20-13.
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; } }
Листинг 20-13: Определение трейта Iterator с ассоциированным типом Item
Тип Item является заполнителем, и определение метода next показывает, что он будет возвращать значения типа Option<Self::Item>. Реализаторы трейта Iterator укажут конкретный тип для Item, и метод next будет возвращать Option, содержащий значение этого конкретного типа.
Ассоциированные типы могут показаться похожими на обобщённые типы (generics), поскольку последние позволяют нам определить функцию без указания типов, с которыми она может работать. Чтобы исследовать разницу между этими двумя концепциями, рассмотрим реализацию трейта Iterator для типа с именем Counter, который указывает, что тип Item — это u32:
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { // --пропуск-- }
Этот синтаксис кажется сопоставимым с синтаксисом обобщённых типов. Так почему бы просто не определить трейт Iterator с обобщёнными типами, как показано в листинге 20-14?
#![allow(unused)] fn main() { pub trait Iterator<T> { fn next(&mut self) -> Option<T>; } }
Листинг 20-14: Гипотетическое определение трейта Iterator с использованием обобщённых типов
Разница заключается в том, что при использовании обобщённых типов, как в листинге 20-14, мы должны аннотировать типы в каждой реализации; поскольку мы также можем реализовать Iterator<String> для Counter или любого другого типа, у нас может быть несколько реализаций Iterator для Counter. Другими словами, когда трейт имеет обобщённый параметр, он может быть реализован для типа несколько раз, каждый раз изменяя конкретные типы параметров обобщённого типа. Когда мы используем метод next на Counter, нам пришлось бы предоставлять аннотации типов, чтобы указать, какую реализацию Iterator мы хотим использовать.
С ассоциированными типами нам не нужно аннотировать типы, потому что мы не можем реализовать трейт для типа несколько раз. В листинге 20-13 с определением, использующим ассоциированные типы, мы можем выбрать, каким будет тип Item, только один раз, потому что может быть только одна реализация impl Iterator for Counter. Нам не нужно указывать, что мы хотим итератор значений u32 везде, где мы вызываем next на Counter.
Ассоциированные типы также становятся частью контракта трейта: реализаторы трейта должны предоставить тип, который заменит ассоциированный тип-заполнитель. Ассоциированные типы часто имеют имя, которое описывает, как тип будет использоваться, и документирование ассоциированного типа в документации API является хорошей практикой.
Использование параметров обобщённого типа по умолчанию и перегрузка операторов
При использовании параметров обобщённого типа мы можем указать конкретный тип по умолчанию для обобщённого типа. Это устраняет необходимость для реализаторов трейта указывать конкретный тип, если тип по умолчанию подходит. Вы указываете тип по умолчанию при объявлении обобщённого типа с помощью синтаксиса <PlaceholderType=ConcreteType>.
Отличным примером ситуации, где полезна эта техника, является перегрузка операторов (operator overloading), когда вы настраиваете поведение оператора (например, +) в определённых ситуациях.
Rust не позволяет создавать собственные операторы или перегружать произвольные операторы. Но вы можете перегружать операции и соответствующие трейты, перечисленные в std::ops, реализуя трейты, связанные с оператором. Например, в листинге 20-15 мы перегружаем оператор + для сложения двух экземпляров Point. Мы делаем это, реализуя трейт Add для структуры Point.
Файл: src/main.rs
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
Листинг 20-15: Реализация трейта Add для перегрузки оператора + для экземпляров Point
Метод add складывает значения x двух экземпляров Point и значения y двух экземпляров Point, чтобы создать новый Point. Трейт Add имеет ассоциированный тип с именем Output, который определяет тип, возвращаемый методом add.
Параметр обобщённого типа по умолчанию в этом коде находится внутри трейта Add. Вот его определение:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
Этот код должен выглядеть в целом знакомо: трейт с одним методом и ассоциированным типом. Новая часть — это Rhs=Self: этот синтаксис называется параметрами типа по умолчанию (default type parameters). Параметр обобщённого типа Rhs (сокращение от «right-hand side») определяет тип параметра rhs в методе add. Если мы не укажем конкретный тип для Rhs при реализации трейта Add, тип Rhs по умолчанию будет Self, которым будет тип, для которого мы реализуем Add.
Когда мы реализовали Add для Point, мы использовали значение по умолчанию для Rhs, потому что хотели сложить два экземпляра Point. Давайте рассмотрим пример реализации трейта Add, где мы хотим настроить тип Rhs вместо использования значения по умолчанию.
У нас есть две структуры, Millimeters и Meters, содержащие значения в разных единицах измерения. Такая тонкая обёртка существующего типа в другую структуру известна как шаблон «newtype», который мы подробнее опишем в разделе «Реализация внешних трейтов с помощью шаблона Newtype». Мы хотим добавить значения в миллиметрах к значениям в метрах и хотим, чтобы реализация Add правильно выполняла преобразование. Мы можем реализовать Add для Millimeters с Meters в качестве Rhs, как показано в листинге 20-16.
Файл: src/lib.rs
#![allow(unused)] fn main() { use std::ops::Add; struct Millimeters(u32); struct Meters(u32); impl Add<Meters> for Millimeters { type Output = Millimeters; fn add(self, other: Meters) -> Millimeters { Millimeters(self.0 + (other.0 * 1000)) } } }
Листинг 20-16: Реализация трейта Add для Millimeters для сложения Millimeters и Meters
Чтобы сложить Millimeters и Meters, мы указываем impl Add<Meters>, чтобы установить значение параметра типа Rhs вместо использования значения по умолчанию Self.
Вы будете использовать параметры типа по умолчанию двумя основными способами:
- Для расширения типа без нарушения существующего кода
- Чтобы разрешить настройку в конкретных случаях, которые большинству пользователей не понадобятся
Трейт Add из стандартной библиотеки является примером второй цели: обычно вы складываете два одинаковых типа, но трейт Add предоставляет возможность настройки beyond этого. Использование параметра типа по умолчанию в определении трейта Add означает, что в большинстве случаев вам не нужно указывать дополнительный параметр. Другими словами, не требуется немного шаблонного кода реализации, что упрощает использование трейта.
Первая цель похожа на вторую, но наоборот: если вы хотите добавить параметр типа к существующему трейту, вы можете задать для него значение по умолчанию, чтобы позволить расширение функциональности трейта без нарушения существующего кода реализации.
Разрешение неоднозначности между методами с одинаковыми именами
Ничто в Rust не мешает трейту иметь метод с тем же именем, что и метод другого трейта, и Rust не мешает вам реализовать оба трейта на одном типе. Также возможно реализовать метод непосредственно на типе с тем же именем, что и методы из трейтов.
При вызове методов с одинаковыми именами вам нужно указать Rust, какой из них вы хотите использовать. Рассмотрим код в листинге 20-17, где мы определили два трейта, Pilot и Wizard, оба с методом fly. Затем мы реализуем оба трейта на типе Human, у которого уже реализован метод fly. Каждый метод fly делает что-то разное.
Файл: src/main.rs
#![allow(unused)] fn main() { trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } }
Листинг 20-17: Два трейта с методом fly реализованы на типе Human, и метод fly также реализован непосредственно на Human
Когда мы вызываем fly на экземпляре Human, компилятор по умолчанию вызывает метод, непосредственно реализованный на типе, как показано в листинге 20-18.
Файл: src/main.rs
fn main() { let person = Human; person.fly(); }
Листинг 20-18: Вызов fly на экземпляре Human
Запуск этого кода выведет *waving arms furiously*, показывая, что Rust вызвал метод fly, реализованный непосредственно на Human.
Чтобы вызвать методы fly из трейта Pilot или Wizard, нам нужно использовать более явный синтаксис для указания, какой метод fly мы имеем в виду. Листинг 20-19 демонстрирует этот синтаксис.
Файл: src/main.rs
fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
Листинг 20-19: Указание, какой метод fly из трейта мы хотим вызвать
Указание имени трейта перед именем метода проясняет Rust, какую реализацию fly мы хотим вызвать. Мы также могли бы написать Human::fly(&person), что эквивалентно person.fly(), который мы использовали в листинге 20-19, но это писать немного дольше, если нам не нужно разрешать неоднозначность.
Запуск этого кода выводит следующее:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Поскольку метод fly принимает параметр self, если бы у нас было два типа, которые оба реализуют один трейт, Rust мог бы определить, какую реализацию трейта использовать, на основе типа self.
Однако ассоциированные функции, которые не являются методами, не имеют параметра self. Когда есть несколько типов или трейтов, определяющих функции-не-методы с одинаковым именем, Rust не всегда знает, какой тип вы имеете в виду, если вы не используете полностью квалифицированный синтаксис. Например, в листинге 20-20 мы создаём трейт для приюта животных, который хочет называть всех щенков Spot. Мы создаём трейт Animal с ассоциированной функцией-не-методом baby_name. Трейт Animal реализован для структуры Dog, для которой мы также предоставляем ассоциированную функцию-не-метод baby_name непосредственно.
Файл: src/main.rs
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
Листинг 20-20: Трейт с ассоциированной функцией и тип с ассоциированной функцией того же имени, который также реализует трейт
Мы реализуем код для именования всех щенков Spot в ассоциированной функции baby_name, определённой на Dog. Тип Dog также реализует трейт Animal, который описывает характеристики, присущие всем животным. Детёныши собак называются щенками (puppies), и это выражено в реализации трейта Animal для Dog в функции baby_name, связанной с трейтом Animal.
В main мы вызываем функцию Dog::baby_name, которая вызывает ассоциированную функцию, определённую непосредственно на Dog. Этот код выводит следующее:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Этот вывод не тот, который мы хотели. Мы хотим вызвать функцию baby_name, которая является частью трейта Animal, который мы реализовали на Dog, чтобы код вывел A baby dog is called a puppy. Техника указания имени трейта, которую мы использовали в листинге 20-19, здесь не помогает; если мы изменим main на код в листинге 20-21, мы получим ошибку компиляции.
Файл: src/main.rs
// [Этот код не компилируется!] fn main() { println!("A baby dog is called a {}", Animal::baby_name()); }
Листинг 20-21: Попытка вызвать функцию baby_name из трейта Animal, но Rust не знает, какую реализацию использовать
Поскольку Animal::baby_name не имеет параметра self и могут быть другие типы, реализующие трейт Animal, Rust не может определить, какую реализацию Animal::baby_name мы хотим. Мы получим эту ошибку компилятора:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Чтобы разрешить неоднозначность и сказать Rust, что мы хотим использовать реализацию Animal для Dog, а не реализацию Animal для какого-либо другого типа, нам нужно использовать полностью квалифицированный синтаксис. Листинг 20-22 демонстрирует, как использовать полностью квалифицированный синтаксис.
Файл: src/main.rs
fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
Листинг 20-22: Использование полностью квалифицированного синтаксиса для указания, что мы хотим вызвать функцию baby_name из трейта Animal, реализованного на Dog
Мы предоставляем Rust аннотацию типа в угловых скобках, которая указывает, что мы хотим вызвать метод baby_name из трейта Animal, реализованного на Dog, говоря, что мы хотим рассматривать тип Dog как Animal для этого вызова функции. Теперь этот код выведет то, что мы хотим:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
В общем случае полностью квалифицированный синтаксис определяется следующим образом:
#![allow(unused)] fn main() { <Type as Trait>::function(receiver_if_method, next_arg, ...); }
Для ассоциированных функций, которые не являются методами, не будет получателя (receiver): будет только список других аргументов. Вы можете использовать полностью квалифицированный синтаксис везде, где вы вызываете функции или методы. Однако вам разрешено опускать любую часть этого синтаксиса, которую Rust может определить из другой информации в программе. Вам нужно использовать этот более многословный синтаксис только в случаях, когда есть несколько реализаций, использующих одно и то же имя, и Rust нужна помощь, чтобы определить, какую реализацию вы хотите вызвать.
Использование супертрейтов
Иногда вы можете написать определение трейта, которое зависит от другого трейта: для того чтобы тип реализовал первый трейт, вы хотите потребовать, чтобы этот тип также реализовал второй трейт. Вы делаете это, чтобы ваше определение трейта могло использовать ассоциированные элементы второго трейта. Трейт, от которого зависит ваше определение трейта, называется супертрейтом (supertrait) вашего трейта.
Например, предположим, что мы хотим создать трейт OutlinePrint с методом outline_print, который будет выводить заданное значение в формате, обрамлённом звёздочками. То есть, для структуры Point, которая реализует трейт Display из стандартной библиотеки с результатом (x, y), когда мы вызываем outline_print на экземпляре Point со значениями x = 1 и y = 3, должно быть выведено следующее:
**********
* *
* (1, 3) *
* *
**********
В реализации метода outline_print мы хотим использовать функциональность трейта Display. Поэтому нам нужно указать, что трейт OutlinePrint будет работать только для типов, которые также реализуют Display и предоставляют функциональность, необходимую OutlinePrint. Мы можем сделать это в определении трейта, указав OutlinePrint: Display. Этот метод аналогичен добавлению ограничения трейта (trait bound) к трейту. Листинг 20-23 показывает реализацию трейта OutlinePrint.
Файл: src/main.rs
#![allow(unused)] fn main() { use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } }
Листинг 20-23: Реализация трейта OutlinePrint, который требует функциональность из Display
Поскольку мы указали, что OutlinePrint требует трейт Display, мы можем использовать функцию to_string, которая автоматически реализуется для любого типа, реализующего Display. Если бы мы попытались использовать to_string без добавления двоеточия и указания трейта Display после имени трейта, мы получили бы ошибку о том, что метод to_string не найден для типа &Self в текущей области видимости.
Давайте посмотрим, что произойдёт, если мы попытаемся реализовать OutlinePrint для типа, который не реализует Display, например, для структуры Point:
Файл: src/main.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} }
Мы получаем ошибку о том, что Display требуется, но не реализован:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Чтобы исправить это, мы реализуем Display для Point и удовлетворим ограничение, которое требует OutlinePrint, следующим образом:
Файл: src/main.rs
#![allow(unused)] fn main() { use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } }
Тогда реализация трейта OutlinePrint для Point будет успешно компилироваться, и мы сможем вызвать outline_print на экземпляре Point, чтобы отобразить его в рамке из звёздочек.
Реализация внешних трейтов с помощью шаблона Newtype
В разделе «Реализация трейта для типа» в главе 10 мы упоминали правило сироты (orphan rule), которое гласит, что мы можем реализовать трейт для типа только если либо трейт, либо тип, либо оба являются локальными для нашего крейта. Можно обойти это ограничение с помощью шаблона newtype, который предполагает создание нового типа в виде кортежной структуры. (Мы рассматривали кортежные структуры в разделе «Создание различных типов с помощью кортежных структур» в главе 5.) Кортежная структура будет иметь одно поле и представлять собой тонкую обёртку вокруг типа, для которого мы хотим реализовать трейт. Тогда тип-обёртка является локальным для нашего крейта, и мы можем реализовать трейт для обёртки. Термин «newtype» происходит из языка программирования Haskell. Использование этого шаблона не влечёт накладных расходов во время выполнения, и тип-обёртка устраняется во время компиляции.
В качестве примера предположим, что мы хотим реализовать Display для Vec<T>, что запрещено правилом сироты, поскольку трейт Display и тип Vec<T> определены вне нашего крейта. Мы можем создать структуру Wrapper, которая содержит экземпляр Vec<T>; затем мы можем реализовать Display для Wrapper и использовать значение Vec<T>, как показано в листинге 20-24.
Файл: src/main.rs
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {w}"); }
Листинг 20-24: Создание типа Wrapper вокруг Vec
Реализация Display использует self.0 для доступа к внутреннему Vec<T>, потому что Wrapper является кортежной структурой и Vec<T> — это элемент с индексом 0 в кортеже. Затем мы можем использовать функциональность трейта Display на Wrapper.
Недостаток этого подхода в том, что Wrapper — это новый тип, поэтому он не имеет методов содержащегося в нём значения. Нам пришлось бы реализовать все методы Vec<T> непосредственно для Wrapper таким образом, чтобы методы делегировали вызовы self.0, что позволило бы нам обращаться с Wrapper точно так же, как с Vec<T>. Если бы мы хотели, чтобы новый тип имел все методы внутреннего типа, решением была бы реализация трейта Deref для Wrapper с возвратом внутреннего типа (мы обсуждали реализацию трейта Deref в разделе «Обращение с умными указателями как с обычными ссылками» в главе 15). Если бы мы не хотели, чтобы тип Wrapper имел все методы внутреннего типа — например, чтобы ограничить поведение типа Wrapper — нам пришлось бы вручную реализовать только те методы, которые нам нужны.
Шаблон newtype также полезен даже когда трейты не задействованы. Давайте переключим фокус и рассмотрим некоторые продвинутые способы взаимодействия с системой типов Rust.
Продвинутые Types
В системе типов Rust есть некоторые возможности, которые мы уже упоминали, но ещё не обсуждали. Мы начнём с обсуждения newtypes в целом, чтобы понять, почему они полезны как типы. Затем мы перейдём к псевдонимам типов — возможности, похожей на newtypes, но с несколько иной семантикой. Мы также обсудим тип ! и типы с динамическим размером.
Типобезопасность и абстракция с помощью шаблона Newtype
Этот раздел предполагает, что вы прочитали предыдущий раздел «Реализация внешних трейтов с помощью шаблона Newtype». Шаблон newtype также полезен для задач, выходящих за рамки уже рассмотренных, включая статическое обеспечение того, что значения никогда не перепутываются, и указание единиц измерения значения. Вы видели пример использования newtypes для указания единиц измерения в листинге 20-16: вспомните, что структуры Millimeters и Meters оборачивали значения u32 в newtype. Если бы мы написали функцию с параметром типа Millimeters, мы не смогли бы скомпилировать программу, которая случайно попыталась бы вызвать эту функцию со значением типа Meters или простым u32.
Мы также можем использовать шаблон newtype для абстрагирования некоторых деталей реализации типа: новый тип может предоставлять публичный API, отличающийся от API приватного внутреннего типа.
Newtypes также могут скрывать внутреннюю реализацию. Например, мы могли бы предоставить тип People для обёртки HashMap<i32, String>, которая хранит ID человека, связанный с его именем. Код, использующий People, будет взаимодействовать только с предоставляемым нами публичным API, например, с методом для добавления строки имени в коллекцию People; этому коду не нужно будет знать, что мы внутренне назначаем ID i32 именам. Шаблон newtype — это лёгкий способ достижения инкапсуляции для сокрытия деталей реализации, что мы обсуждали в разделе «Инкапсуляция, скрывающая детали реализации» в главе 18.
Псевдонимы типов (Type Aliases)
Rust предоставляет возможность объявлять псевдонимы типов, чтобы дать существующему типу другое имя. Для этого мы используем ключевое слово type. Например, мы можем создать псевдоним Kilometers для i32 следующим образом:
#![allow(unused)] fn main() { type Kilometers = i32; }
Теперь псевдоним Kilometers является синонимом для i32; в отличие от типов Millimeters и Meters, которые мы создали в листинге 20-16, Kilometers не является отдельным новым типом. Значения, имеющие тип Kilometers, будут обрабатываться так же, как значения типа i32:
#![allow(unused)] fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Поскольку Kilometers и i32 — это один и тот же тип, мы можем складывать значения обоих типов и передавать значения Kilometers в функции, которые принимают параметры i32. Однако при использовании этого метода мы не получаем преимуществ проверки типов, которые даёт шаблон newtype, рассмотренный ранее. Другими словами, если мы где-то перепутаем значения Kilometers и i32, компилятор не выдаст нам ошибку.
Основной случай использования псевдонимов типов — сокращение повторений. Например, у нас может быть длинный тип, такой как:
#![allow(unused)] fn main() { Box<dyn Fn() + Send + 'static> }
Написание этого длинного типа в сигнатурах функций и в аннотациях типов по всему коду может быть утомительным и подверженным ошибкам. Представьте проект, полный кода, как в листинге 20-25.
#![allow(unused)] fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --пропуск-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --пропуск-- } }
Листинг 20-25: Использование длинного типа во многих местах
Псевдоним типа делает этот код более управляемым за счёт сокращения повторений. В листинге 20-26 мы ввели псевдоним с именем Thunk для многословного типа и можем заменить все использования типа на более короткий Thunk.
#![allow(unused)] fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --пропуск-- } fn returns_long_type() -> Thunk { // --пропуск-- } }
Листинг 20-26: Введение псевдонима типа Thunk для сокращения повторений
Этот код намного легче читать и писать! Выбор содержательного имени для псевдонима типа также помогает передать ваши намерения (thunk — это слово для кода, который должен быть выполнен позже, поэтому это подходящее имя для замыкания, которое сохраняется).
Псевдонимы типов также часто используются с типом Result<T, E> для сокращения повторений. Рассмотрим модуль std::io в стандартной библиотеке. Операции ввода-вывода часто возвращают Result<T, E> для обработки ситуаций, когда операции не выполняются. Эта библиотека имеет структуру std::io::Error, которая представляет все возможные ошибки ввода-вывода. Многие функции в std::io возвращают Result<T, E>, где E — это std::io::Error, например, эти функции в трейте Write:
#![allow(unused)] fn main() { use std::fmt; use std::io::Error; pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize, Error>; fn flush(&mut self) -> Result<(), Error>; fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>; fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>; } }
Result<..., Error> повторяется много раз. Поэтому в std::io есть такое объявление псевдонима типа:
#![allow(unused)] fn main() { type Result<T> = std::result::Result<T, std::io::Error>; }
Поскольку это объявление находится в модуле std::io, мы можем использовать полностью квалифицированный псевдоним std::io::Result<T>; то есть Result<T, E> с E, заполненным как std::io::Error. Сигнатуры функций трейта Write в итоге выглядят так:
#![allow(unused)] fn main() { pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; fn write_all(&mut self, buf: &[u8]) -> Result<()>; fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>; } }
Псевдоним типа помогает двумя способами: он упрощает написание кода и предоставляет нам единообразный интерфейс во всём std::io. Поскольку это псевдоним, это просто другой Result<T, E>, что означает, что мы можем использовать любые методы, работающие с Result<T, E>, с ним, а также специальный синтаксис, такой как оператор ?.
Тип Never, который никогда не возвращается
В Rust есть специальный тип !, известный в терминологии теории типов как пустой тип, поскольку у него нет значений. Мы предпочитаем называть его типом never, потому что он выступает в качестве типа возвращаемого значения, когда функция никогда не возвращается. Вот пример:
#![allow(unused)] fn main() { fn bar() -> ! { // --пропуск-- } }
Этот код читается как «функция bar возвращает never». Функции, которые возвращают never, называются расходящимися функциями (diverging functions). Мы не можем создавать значения типа !, поэтому bar никогда не может вернуть значение.
Но какой смысл в типе, для которого нельзя создать значения? Вспомните код из листинга 2-5, части игры в угадывание числа; мы воспроизвели его фрагмент здесь в листинге 20-27.
#![allow(unused)] fn main() { let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; }
Листинг 20-27: Выражение match с веткой, которая заканчивается на continue
В свое время мы упустили некоторые детали в этом коде. В разделе «Конструкция управления потоком match» в главе 6 мы обсуждали, что все ветки match должны возвращать один и тот же тип. Так, например, следующий код не работает:
#![allow(unused)] fn main() { // [Этот код не компилируется!] let guess = match guess.trim().parse() { Ok(_) => 5, Err(_) => "hello", }; }
Тип guess в этом коде должен был бы быть одновременно целым числом и строкой, а Rust требует, чтобы guess имел только один тип. Так что же возвращает continue? Как нам было разрешено возвращать u32 из одной ветки и иметь другую ветку, заканчивающуюся continue в листинге 20-27?
Как вы могли догадаться, continue имеет значение !. То есть, когда Rust вычисляет тип guess, он смотрит на обе ветки match: первая со значением u32, а вторая со значением !. Поскольку ! никогда не может иметь значения, Rust определяет, что тип guess — это u32.
Формальный способ описания этого поведения заключается в том, что выражения типа ! могут быть приведены к любому другому типу. Нам разрешено заканчивать эту ветку match оператором continue, потому что continue не возвращает значение; вместо этого он передаёт управление обратно в начало цикла, поэтому в случае Err мы никогда не присваиваем значение guess.
Тип never также полезен с макросом panic!. Вспомните функцию unwrap, которую мы вызываем для значений Option<T>, чтобы получить значение или вызвать панику с таким определением:
#![allow(unused)] fn main() { impl<T> Option<T> { pub fn unwrap(self) -> T { match self { Some(val) => val, None => panic!("called `Option::unwrap()` on a `None` value"), } } } }
В этом коде происходит то же самое, что и в выражении match в листинге 20-27: Rust видит, что val имеет тип T, а panic! имеет тип !, поэтому результат всего выражения match — T. Этот код работает, потому что panic! не производит значение; он завершает программу. В случае None мы не будем возвращать значение из unwrap, поэтому этот код корректен.
Ещё одно выражение, которое имеет тип ! — это loop:
#![allow(unused)] fn main() { print!("forever "); loop { print!("and ever "); } }
Здесь цикл никогда не заканчивается, поэтому ! является значением выражения. Однако это было бы неверно, если бы мы включили break, потому что цикл завершился бы при достижении break.
Типы с динамическим размером и трейт Sized
Rust необходимо знать определённые детали о своих типах, например, сколько памяти выделить для значения конкретного типа. Это создаёт некоторую путаницу в одной из областей системы типов: концепция типов с динамическим размером. Иногда называемые DST или unsized types, эти типы позволяют нам писать код, используя значения, размер которых мы можем узнать только во время выполнения.
Давайте углубимся в детали типа с динамическим размером под названием str, который мы использовали на протяжении всей книги. Да, именно так, не &str, а сам str является DST. Во многих случаях, например, при хранении текста, введённого пользователем, мы не можем узнать длину строки до момента выполнения. Это означает, что мы не можем создать переменную типа str и не можем принимать аргумент типа str. Рассмотрим следующий код, который не работает:
#![allow(unused)] fn main() { // [Этот код не компилируется!] let s1: str = "Hello there!"; let s2: str = "How's it going?"; }
Rust необходимо знать, сколько памяти выделить для любого значения конкретного типа, и все значения типа должны использовать одинаковый объём памяти. Если бы Rust разрешил нам написать этот код, эти два значения str должны были бы занимать одинаковое место. Но они имеют разную длину: s1 требует 12 байт памяти, а s2 — 15. Вот почему невозможно создать переменную, содержащую тип с динамическим размером.
Так что же нам делать? В этом случае вы уже знаете ответ: мы делаем тип s1 и s2 строковым срезом (&str), а не str. Вспомните из раздела «Строковые срезы» в главе 4, что структура данных среза хранит только начальную позицию и длину среза. Таким образом, хотя &T — это единственное значение, хранящее адрес памяти, где находится T, строковый срез — это два значения: адрес str и его длина. Как следствие, мы можем узнать размер значения строкового среза во время компиляции: это удвоенная длина usize. То есть мы всегда знаем размер строкового среза, независимо от длины строки, на которую он ссылается. В общем случае, именно так типы с динамическим размером используются в Rust: у них есть дополнительный бит метаданных, хранящий размер динамической информации. Золотое правило типов с динамическим размером заключается в том, что мы всегда должны помещать значения таких типов за указателем какого-либо вида.
Мы можем комбинировать str с различными видами указателей: например, Box<str> или Rc<str>. На самом деле, вы уже видели это ранее, но с другим типом с динамическим размером: трейтами. Каждый трейт — это тип с динамическим размером, на который мы можем ссылаться, используя имя трейта. В разделе «Использование трейт-объектов для абстрагирования общего поведения» в главе 18 мы упоминали, что для использования трейтов в качестве трейт-объектов мы должны помещать их за указателем, таким как &dyn Trait или Box<dyn Trait> (Rc<dyn Trait> тоже подойдёт).
Для работы с DST Rust предоставляет трейт Sized для определения, известен ли размер типа во время компиляции. Этот трейт автоматически реализуется для всего, чей размер известен во время компиляции. Кроме того, Rust неявно добавляет ограничение Sized для каждой обобщённой функции. То есть, определение обобщённой функции like this:
#![allow(unused)] fn main() { fn generic<T>(t: T) { // --пропуск-- } }
фактически обрабатывается так, как если бы мы написали:
#![allow(unused)] fn main() { fn generic<T: Sized>(t: T) { // --пропуск-- } }
По умолчанию обобщённые функции будут работать только с типами, имеющими известный размер во время компиляции. Однако вы можете использовать следующий специальный синтаксис, чтобы ослабить это ограничение:
#![allow(unused)] fn main() { fn generic<T: ?Sized>(t: &T) { // --пропуск-- } }
Ограничение трейта ?Sized означает «T может быть Sized или нет», и эта нотация переопределяет значение по умолчанию, согласно которому обобщённые типы должны иметь известный размер во время компиляции. Синтаксис ?Trait с таким значением доступен только для Sized, а не для любых других трейтов.
Также обратите внимание, что мы изменили тип параметра t с T на &T. Поскольку тип может не быть Sized, нам нужно использовать его за каким-либо указателем. В данном случае мы выбрали ссылку.
Далее мы поговорим о функциях и замыканиях!
Продвинутые функции и замыкания
Этот раздел исследует некоторые продвинутые возможности, связанные с функциями и замыканиями, включая указатели на функции и возвращение замыканий.
Указатели на функции
Мы говорили о том, как передавать замыкания в функции; вы также можете передавать обычные функции в функции! Этот приём полезен, когда вы хотите передать уже определённую функцию вместо создания нового замыкания. Функции приводятся к типу fn (со строчной f), не путать с трейтом замыкания Fn. Тип fn называется указателем на функцию. Передача функций с помощью указателей на функции позволяет использовать функции в качестве аргументов других функций.
Синтаксис указания, что параметр является указателем на функцию, похож на синтаксис для замыканий, как показано в листинге 20-28, где мы определили функцию add_one, которая добавляет 1 к своему параметру. Функция do_twice принимает два параметра: указатель на функцию для любой функции, которая принимает параметр i32 и возвращает i32, и одно значение i32. Функция do_twice вызывает функцию f дважды, передавая ей значение arg, затем складывает результаты двух вызовов функции. Функция main вызывает do_twice с аргументами add_one и 5.
Файл: src/main.rs
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {answer}"); }
Листинг 20-28: Использование типа fn для принятия указателя на функцию в качестве аргумента
Этот код выводит The answer is: 12. Мы указываем, что параметр f в do_twice — это fn, который принимает один параметр типа i32 и возвращает i32. Затем мы можем вызвать f в теле do_twice. В main мы можем передать имя функции add_one в качестве первого аргумента в do_twice.
В отличие от замыканий, fn — это тип, а не трейт, поэтому мы указываем fn как тип параметра напрямую, а не объявляем параметр обобщённого типа с одним из трейтов Fn в качестве ограничения трейта.
Указатели на функции реализуют все три трейта замыканий (Fn, FnMut и FnOnce), что означает, что вы всегда можете передать указатель на функцию в качестве аргумента для функции, которая ожидает замыкание. Лучше писать функции, используя обобщённый тип и один из трейтов замыканий, чтобы ваши функции могли принимать как функции, так и замыкания.
Тем не менее, пример ситуации, где вы хотели бы принимать только fn, а не замыкания — это взаимодействие с внешним кодом, который не имеет замыканий: функции C могут принимать функции в качестве аргументов, но в C нет замыканий.
В качестве примера, где вы могли бы использовать либо замыкание, определённое inline, либо именованную функцию, рассмотрим использование метода map, предоставляемого трейтом Iterator в стандартной библиотеке. Чтобы использовать метод map для превращения вектора чисел в вектор строк, мы могли бы использовать замыкание, как в листинге 20-29.
#![allow(unused)] fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect(); }
Листинг 20-29: Использование замыкания с методом map для преобразования чисел в строки
Или мы могли бы указать именованную функцию в качестве аргумента для map вместо замыкания. Листинг 20-30 показывает, как это выглядит.
#![allow(unused)] fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect(); }
Листинг 20-30: Использование функции String::to_string с методом map для преобразования чисел в строки
Обратите внимание, что мы должны использовать полностью квалифицированный синтаксис, о котором мы говорили в разделе «Продвинутые трейты», потому что доступно несколько функций с именем to_string.
Здесь мы используем функцию to_string, определённую в трейте ToString, которую стандартная библиотека реализовала для любого типа, реализующего Display.
Вспомните из раздела «Значения перечислений» в главе 6, что имя каждого варианта перечисления, которое мы определяем, также становится функцией-инициализатором. Мы можем использовать эти функции-инициализаторы как указатели на функции, которые реализуют трейты замыканий, что означает, что мы можем указывать функции-инициализаторы в качестве аргументов для методов, принимающих замыкания, как показано в листинге 20-31.
#![allow(unused)] fn main() { enum Status { Value(u32), Stop, } let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect(); }
Листинг 20-31: Использование инициализатора перечисления с методом map для создания экземпляров Status из чисел
Здесь мы создаём экземпляры Status::Value, используя каждое значение u32 в диапазоне, для которого вызывается map, с помощью функции-инициализатора Status::Value. Некоторые предпочитают этот стиль, а некоторые предпочитают использовать замыкания. Они компилируются в один и тот же код, поэтому используйте тот стиль, который вам понятнее.
Возвращение замыканий
Замыкания представлены трейтами, что означает, что вы не можете возвращать замыкания напрямую. В большинстве случаев, когда вы хотите вернуть трейт, вы можете вместо этого использовать конкретный тип, реализующий трейт, в качестве возвращаемого значения функции. Однако с замыканиями это обычно невозможно, поскольку у них нет возвращаемого конкретного типа; вам не разрешено использовать указатель на функцию fn в качестве возвращаемого типа, если замыкание захватывает какие-либо значения из своей области видимости.
Вместо этого вы обычно будете использовать синтаксис impl Trait, который мы изучили в главе 10. Вы можете возвращать любой тип функции, используя Fn, FnOnce и FnMut. Например, код в листинге 20-32 скомпилируется без проблем.
#![allow(unused)] fn main() { fn returns_closure() -> impl Fn(i32) -> i32 { |x| x + 1 } }
Листинг 20-32: Возвращение замыкания из функции с использованием синтаксиса impl Trait
Однако, как мы отмечали в разделе «Выведение и аннотирование типов замыканий» в главе 13, каждое замыкание также является своим собственным уникальным типом. Если вам нужно работать с несколькими функциями, которые имеют одинаковую сигнатуру, но разные реализации, вам нужно будет использовать для них трейт-объект. Рассмотрим, что произойдёт, если вы напишете код, показанный в листинге 20-33.
Файл: src/main.rs
// [Этот код не компилируется!] fn main() { let handlers = vec![returns_closure(), returns_initialized_closure(123)]; for handler in handlers { let output = handler(5); println!("{output}"); } } fn returns_closure() -> impl Fn(i32) -> i32 { |x| x + 1 } fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 { move |x| x + init }
Листинг 20-33: Создание Vec
Здесь у нас есть две функции, returns_closure и returns_initialized_closure, которые обе возвращают impl Fn(i32) -> i32. Обратите внимание, что замыкания, которые они возвращают, различны, даже though они реализуют один и тот же тип. Если мы попытаемся скомпилировать это, Rust сообщит нам, что это не сработает:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32` (opaque type at <src/main.rs:9:25>)
found opaque type `impl Fn(i32) -> i32` (opaque type at <src/main.rs:13:46>)
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Сообщение об ошибке говорит нам, что каждый раз, когда мы возвращаем impl Trait, Rust создаёт уникальный непрозрачный тип (opaque type) — тип, в детали которого мы не можем заглянуть, и не можем угадать, какой тип сгенерирует Rust, чтобы написать его самим. Поэтому, даже though эти функции возвращают замыкания, реализующие один и тот же трейт Fn(i32) -> i32, непрозрачные типы, которые Rust генерирует для каждого, различны. (Это похоже на то, как Rust создаёт разные конкретные типы для различных async-блоков, даже когда они имеют один и тот же выходной тип, как мы видели в разделе «Тип Pin и трейт Unpin» в главе 17.) Мы уже видели решение этой проблемы несколько раз: мы можем использовать трейт-объект, как в листинге 20-34.
#![allow(unused)] fn main() { fn returns_closure() -> Box<dyn Fn(i32) -> i32> { Box::new(|x| x + 1) } fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> { Box::new(move |x| x + init) } }
Листинг 20-34: Создание Vec
Этот код скомпилируется без проблем. Для получения дополнительной информации о трейт-объектах обратитесь к разделу «Использование трейт-объектов для абстрагирования общего поведения» в главе 18.
Далее давайте посмотрим на макросы!
Макросы
Мы использовали макросы, такие как println!, на протяжении всей этой книги, но мы не полностью исследовали, что такое макрос и как он работает. Термин «макрос» относится к семейству возможностей в Rust — декларативные макросы с macro_rules! и три вида процедурных макросов:
- Пользовательские
#[derive]макросы, которые определяют код, добавляемый с помощью атрибутаderive, используемого на структурах и перечислениях - Макросы, похожие на атрибуты, которые определяют пользовательские атрибуты, применимые к любому элементу
- Макросы, похожие на функции, которые выглядят как вызовы функций, но работают с токенами, указанными в качестве их аргумента
Мы поговорим о каждом из них по очереди, но сначала давайте посмотрим, зачем вообще нужны макросы, когда у нас уже есть функции.
Разница между макросами и функциями
По своей сути, макросы — это способ написания кода, который пишет другой код, что известно как метапрограммирование. В Приложении C мы обсуждаем атрибут derive, который генерирует реализацию различных трейтов для вас. Мы также использовали макросы println! и vec! на протяжении всей книги. Все эти макросы раскрываются, чтобы произвести больше кода, чем код, который вы написали вручную.
Метапрограммирование полезно для сокращения объёма кода, который вам приходится писать и поддерживать, что также является одной из ролей функций. Однако макросы обладают некоторыми дополнительными возможностями, которых нет у функций.
Сигнатура функции должна объявлять количество и тип параметров функции. Макросы, с другой стороны, могут принимать переменное количество параметров: мы можем вызвать println!("hello") с одним аргументом или println!("hello {}", name) с двумя аргументами. Кроме того, макросы раскрываются до того, как компилятор интерпретирует значение кода, поэтому макрос может, например, реализовать трейт для данного типа. Функция не может, потому что она вызывается во время выполнения, а трейт должен быть реализован во время компиляции.
Недостаток реализации макроса вместо функции заключается в том, что определения макросов более сложны, чем определения функций, потому что вы пишете код на Rust, который пишет код на Rust. Из-за этой косвенности определения макросов обычно сложнее читать, понимать и поддерживать, чем определения функций.
Ещё одно важное различие между макросами и функциями заключается в том, что вы должны определить макросы или внести их в область видимости до их вызова в файле, в отличие от функций, которые вы можете определять где угодно и вызывать где угодно.
Декларативные макросы для общего метапрограммирования
Наиболее широко используемой формой макросов в Rust являются декларативные макросы. Их иногда также называют «макросами по примеру», «макросами macro_rules!» или просто «макросами». В своей основе декларативные макросы позволяют вам написать нечто похожее на выражение match в Rust. Как обсуждалось в главе 6, выражения match — это конструкции управления потоком, которые принимают выражение, сравнивают результирующее значение выражения с образцами и затем выполняют код, связанный с подходящим образцом. Макросы также сравнивают значение с образцами, связанными с определённым кодом: в этой ситуации значением является литеральный исходный код Rust, переданный макросу; образцы сравниваются со структурой этого исходного кода; и код, связанный с каждым образцом, при совпадении заменяет код, переданный макросу. Всё это происходит во время компиляции.
Чтобы определить макрос, вы используете конструкцию macro_rules!. Давайте explore, как использовать macro_rules!, посмотрев на то, как определён макрос vec!. В главе 8 рассказывалось, как мы можем использовать макрос vec! для создания нового вектора с определёнными значениями. Например, следующий макрос создаёт новый вектор, содержащий три целых числа:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
Мы также могли бы использовать макрос vec! для создания вектора из двух целых чисел или вектора из пяти строковых срезов. Мы не смогли бы использовать функцию для того же самого, потому что мы не знали бы количество или тип значений заранее.
Листинг 20-35 показывает слегка упрощённое определение макроса vec!.
Файл: src/lib.rs
#![allow(unused)] fn main() { #[macro_export] macro_rules! vec { ( $( $x:expr ),* ) => { { let mut temp_vec = Vec::new(); $( temp_vec.push($x); )* temp_vec } }; } }
Листинг 20-35: Упрощённая версия определения макроса vec!
Примечание: фактическое определение макроса vec! в стандартной библиотеке включает код для предварительного выделения правильного количества памяти. Этот код является оптимизацией, которую мы не включаем здесь, чтобы упростить пример.
Аннотация #[macro_export] указывает, что этот макрос должен быть доступен всякий раз, когда крейт, в котором определён макрос, вносится в область видимости. Без этой аннотации макрос не может быть внесён в область видимости.
Затем мы начинаем определение макроса с macro_rules! и имени определяемого макроса без восклицательного знака. Имя, в данном случае vec, следует за фигурными скобками, обозначающими тело определения макроса.
Структура в теле vec! похожа на структуру выражения match. Здесь у нас есть одна ветка с образцом ( $( $x:expr ),* ), за которой следует => и блок кода, связанный с этим образцом. Если образец совпадает, будет создан связанный блок кода. Учитывая, что это единственный образец в этом макросе, есть только один допустимый способ совпадения; любой другой образец приведёт к ошибке. Более сложные макросы будут иметь более одной ветки.
Допустимый синтаксис образцов в определениях макросов отличается от синтаксиса образцов, рассмотренного в главе 19, потому что образцы макросов сопоставляются со структурой кода Rust, а не со значениями. Давайте разберём, что означают части образца в листинге 20-35; для полного синтаксиса образцов макросов см. Rust Reference.
Сначала мы используем набор круглых скобок, чтобы охватить весь образец. Мы используем знак доллара ($), чтобы объявить переменную в системе макросов, которая будет содержать код Rust, соответствующий образцу. Знак доллара делает ясным, что это переменная макроса, в отличие от обычной переменной Rust. Далее следует набор круглых скобок, который захватывает значения, соответствующие образцу внутри скобок, для использования в заменяющем коде. Внутри $() находится $x:expr, который соответствует любому выражению Rust и даёт выражению имя $x.
Запятая после $() указывает, что литеральный символ-разделитель запятой должен появляться между каждым экземпляром кода, который соответствует коду в $(). * указывает, что образец соответствует нулю или более того, что предшествует *.
Когда мы вызываем этот макрос с vec![1, 2, 3];, образец $x совпадает три раза с тремя выражениями 1, 2 и 3.
Теперь посмотрим на образец в теле кода, связанного с этой веткой: temp_vec.push() внутри $()* генерируется для каждой части, которая соответствует $() в образце, ноль или более раз в зависимости от того, сколько раз образец совпадает. $x заменяется каждым совпавшим выражением. Когда мы вызываем этот макрос с vec![1, 2, 3];, сгенерированный код, который заменяет этот вызов макроса, будет следующим:
#![allow(unused)] fn main() { { let mut temp_vec = Vec::new(); temp_vec.push(1); temp_vec.push(2); temp_vec.push(3); temp_vec } }
Мы определили макрос, который может принимать любое количество аргументов любого типа и может генерировать код для создания вектора, содержащего указанные элементы.
Чтобы узнать больше о том, как писать макросы, обратитесь к онлайн-документации или другим ресурсам, таким как «The Little Book of Rust Macros», начатый Дэниелом Кипом и продолженный Лукасом Виртом.
Процедурные макросы для генерации кода из атрибутов
Вторая форма макросов — это процедурные макросы, которые действуют более подобно функциям (и являются разновидностью процедур). Процедурные макросы принимают некоторый код в качестве входных данных, работают с этим кодом и производят некоторый код в качестве выходных данных, вместо сопоставления с образцами и замены кода другим кодом, как это делают декларативные макросы. Три вида процедурных макросов — это пользовательские derive-макросы, макросы, похожие на атрибуты, и макросы, похожие на функции, и все они работают схожим образом.
При создании процедурных макросов их определения должны находиться в собственном крейте со специальным типом крейта. Это связано со сложными техническими причинами, которые мы надеемся устранить в будущем. В листинге 20-36 мы показываем, как определить процедурный макрос, где some_attribute является заполнителем для использования конкретной разновидности макроса.
Файл: src/lib.rs
#![allow(unused)] fn main() { use proc_macro::TokenStream; #[some_attribute] pub fn some_name(input: TokenStream) -> TokenStream { } }
Листинг 20-36: Пример определения процедурного макроса
Функция, определяющая процедурный макрос, принимает TokenStream в качестве входных данных и производит TokenStream в качестве выходных данных. Тип TokenStream определяется крейтом proc_macro, который включён в Rust, и представляет последовательность токенов. Это ядро макроса: исходный код, с которым работает макрос, составляет входной TokenStream, а код, который производит макрос, — это выходной TokenStream. Функция также имеет attached к ней атрибут, который указывает, какой вид процедурного макроса мы создаём. Мы можем иметь несколько видов процедурных макросов в одном крейте.
Давайте рассмотрим различные виды процедурных макросов. Мы начнём с пользовательского derive-макроса, а затем объясним небольшие различия, которые делают другие формы отличными.
Пользовательские derive-макросы
Давайте создадим крейт с именем hello_macro, который определяет трейт HelloMacro с одной ассоциированной функцией hello_macro. Вместо того чтобы заставлять наших пользователей реализовывать трейт HelloMacro для каждого из их типов, мы предоставим процедурный макрос, чтобы пользователи могли аннотировать свой тип с помощью #[derive(HelloMacro)] и получить реализацию по умолчанию функции hello_macro. Реализация по умолчанию будет выводить Hello, Macro! My name is TypeName!, где TypeName — это имя типа, для которого определён этот трейт. Другими словами, мы напишем крейт, который позволит другому программисту писать код, как в листинге 20-37, используя наш крейт.
Файл: src/main.rs
// [Этот код не компилируется!] use hello_macro::HelloMacro; use hello_macro_derive::HelloMacro; #[derive(HelloMacro)] struct Pancakes; fn main() { Pancakes::hello_macro(); }
Листинг 20-37: Код, который пользователь нашего крейта сможет написать при использовании нашего процедурного макроса
Этот код выведет Hello, Macro! My name is Pancakes!, когда мы закончим. Первый шаг — создать новый библиотечный крейт, вот так:
$ cargo new hello_macro --lib
Далее, в листинге 20-38, мы определим трейт HelloMacro и его ассоциированную функцию.
Файл: src/lib.rs
#![allow(unused)] fn main() { pub trait HelloMacro { fn hello_macro(); } }
Листинг 20-38: Простой трейт, который мы будем использовать с derive-макросом
У нас есть трейт и его функция. На этом этапе пользователь нашего крейта мог бы реализовать трейт для достижения желаемой функциональности, как в листинге 20-39.
Файл: src/main.rs
use hello_macro::HelloMacro; struct Pancakes; impl HelloMacro for Pancakes { fn hello_macro() { println!("Hello, Macro! My name is Pancakes!"); } } fn main() { Pancakes::hello_macro(); }
Листинг 20-39: Как это выглядело бы, если бы пользователи писали ручную реализацию трейта HelloMacro
Однако им пришлось бы писать блок реализации для каждого типа, который они хотели бы использовать с hello_macro; мы хотим избавить их от этой работы.
Кроме того, мы пока не можем предоставить функцию hello_macro с реализацией по умолчанию, которая будет выводить имя типа, для которого реализован трейт: в Rust нет возможностей рефлексии, поэтому он не может найти имя типа во время выполнения. Нам нужен макрос для генерации кода во время компиляции.
Следующий шаг — определить процедурный макрос. На момент написания процедурные макросы должны находиться в собственном крейте. В конечном счёте это ограничение может быть снято. Соглашение для структурирования крейтов и макрос-крейтов следующее: для крейта с именем foo пользовательский derive процедурный макрос-крейт называется foo_derive. Давайте начнём новый крейт с именем hello_macro_derive внутри нашего проекта hello_macro:
$ cargo new hello_macro_derive --lib
Наши два крейта тесно связаны, поэтому мы создаём крейт процедурного макроса внутри директории нашего крейта hello_macro. Если мы изменим определение трейта в hello_macro, нам также придётся изменить реализацию процедурного макроса в hello_macro_derive. Эти два крейта нужно будет публиковать отдельно, и программисты, использующие эти крейты, должны будут добавить оба как зависимости и внести оба в область видимости. Мы могли бы вместо этого заставить крейт hello_macro использовать hello_macro_derive как зависимость и реэкспортировать код процедурного макроса. Однако то, как мы структурировали проект, позволяет программистам использовать hello_macro, даже если они не хотят функциональность derive.
Нам нужно объявить крейт hello_macro_derive как крейт процедурного макроса. Нам также понадобится функциональность из крейтов syn и quote, как вы скоро увидите, поэтому нам нужно добавить их как зависимости. Добавьте следующее в файл Cargo.toml для hello_macro_derive:
Файл: hello_macro_derive/Cargo.toml
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Чтобы начать определение процедурного макроса, поместите код из листинга 20-40 в ваш файл src/lib.rs для крейта hello_macro_derive. Обратите внимание, что этот код не скомпилируется, пока мы не добавим определение для функции impl_hello_macro.
Файл: hello_macro_derive/src/lib.rs
#![allow(unused)] fn main() { // [Этот код не компилируется!] use proc_macro::TokenStream; use quote::quote; #[proc_macro_derive(HelloMacro)] pub fn hello_macro_derive(input: TokenStream) -> TokenStream { // Строим представление кода Rust в виде синтаксического дерева, // которым мы можем манипулировать. let ast = syn::parse(input).unwrap(); // Строим реализацию трейта. impl_hello_macro(&ast) } }
Листинг 20-40: Код, который потребуется большинству крейтов процедурных макросов для обработки кода Rust
Обратите внимание, что мы разделили код на функцию hello_macro_derive, которая отвечает за разбор TokenStream, и функцию impl_hello_macro, которая отвечает за преобразование синтаксического дерева: это делает написание процедурного макроса более удобным. Код во внешней функции (hello_macro_derive в данном случае) будет одинаковым для почти каждого крейта процедурного макроса, который вы увидите или создадите. Код, который вы укажете в теле внутренней функции (impl_hello_macro в данном случае), будет разным в зависимости от цели вашего процедурного макроса.
Мы представили три новых крейта: proc_macro, syn и quote. Крейт proc_macro поставляется с Rust, поэтому нам не нужно было добавлять его в зависимости в Cargo.toml. Крейт proc_macro — это API компилятора, который позволяет нам читать и манипулировать кодом Rust из нашего кода.
Крейт syn разбирает код Rust из строки в структуру данных, над которой мы можем выполнять операции. Крейт quote превращает структуры данных syn обратно в код Rust. Эти крейты значительно упрощают разбор любого вида кода Rust, с которым мы можем захотеть работать: написание полного парсера для кода Rust — непростая задача.
Функция hello_macro_derive будет вызываться, когда пользователь нашей библиотеки укажет #[derive(HelloMacro)] на типе. Это возможно, потому что мы аннотировали функцию hello_macro_derive здесь с помощью proc_macro_derive и указали имя HelloMacro, которое совпадает с именем нашего трейта; это соглашение, которому следуют большинство процедурных макросов.
Функция hello_macro_derive сначала преобразует входные данные из TokenStream в структуру данных, которую мы затем можем интерпретировать и выполнять операции. Здесь в игру вступает syn. Функция parse в syn принимает TokenStream и возвращает структуру DeriveInput, представляющую разобранный код Rust. Листинг 20-41 показывает соответствующие части структуры DeriveInput, которую мы получаем при разборе строки struct Pancakes;.
#![allow(unused)] fn main() { DeriveInput { // --пропуск-- ident: Ident { ident: "Pancakes", span: #0 bytes(95..103) }, data: Struct( DataStruct { struct_token: Struct, fields: Unit, semi_token: Some( Semi ) } ) } }
Листинг 20-41: Экземпляр DeriveInput, который мы получаем при разборе кода с атрибутом макроса из листинга 20-37
Поля этой структуры показывают, что разобранный нами код Rust — это unit-структура с ident (идентификатором, то есть именем) Pancakes. В этой структуре есть больше полей для описания всех видов кода Rust; проверьте документацию syn для DeriveInput для получения дополнительной информации.
Вскоре мы определим функцию impl_hello_macro, где мы будем строить новый код Rust, который хотим включить. Но прежде чем мы это сделаем, обратите внимание, что вывод для нашего derive-макроса также является TokenStream. Возвращённый TokenStream добавляется к коду, который пишут пользователи нашего крейта, поэтому когда они компилируют свой крейт, они получат дополнительную функциональность, которую мы предоставляем в изменённом TokenStream.
Вы могли заметить, что мы вызываем unwrap, чтобы заставить функцию hello_macro_derive паниковать, если вызов функции syn::parse завершится неудачей. Необходимо, чтобы наш процедурный макрос паниковал при ошибках, потому что функции proc_macro_derive должны возвращать TokenStream, а не Result, чтобы соответствовать API процедурных макросов. Мы упростили этот пример, используя unwrap; в рабочем коде вы должны предоставлять более конкретные сообщения об ошибках о том, что пошло не так, используя panic! или expect.
Теперь, когда у нас есть код для превращения аннотированного кода Rust из TokenStream в экземпляр DeriveInput, давайте сгенерируем код, который реализует трейт HelloMacro на аннотированном типе, как показано в листинге 20-42.
Файл: hello_macro_derive/src/lib.rs
#![allow(unused)] fn main() { fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream { let name = &ast.ident; let generated = quote! { impl HelloMacro for #name { fn hello_macro() { println!("Hello, Macro! My name is {}!", stringify!(#name)); } } }; generated.into() } }
Листинг 20-42: Реализация трейта HelloMacro с использованием разобранного кода Rust
Мы получаем экземпляр структуры Ident, содержащий имя (идентификатор) аннотированного типа, используя ast.ident. Структура в листинге 20-41 показывает, что когда мы запускаем функцию impl_hello_macro на коде из листинга 20-37, полученный ident будет иметь поле ident со значением "Pancakes". Таким образом, переменная name в листинге 20-42 будет содержать экземпляр структуры Ident, который при печати будет строкой "Pancakes", именем структуры из листинга 20-37.
Макрос quote! позволяет нам определить код Rust, который мы хотим вернуть. Компилятор ожидает нечто иное от прямого результата выполнения макроса quote!, поэтому нам нужно преобразовать его в TokenStream. Мы делаем это, вызывая метод into, который потребляет это промежуточное представление и возвращает значение требуемого типа TokenStream.
Макрос quote! также предоставляет некоторые очень крутые механизмы шаблонизации: мы можем ввести #name, и quote! заменит его значением из переменной name. Вы даже можете делать некоторое повторение, подобно тому, как работают обычные макросы. Ознакомьтесь с документацией крейта quote для полного введения.
Мы хотим, чтобы наш процедурный макрос генерировал реализацию нашего трейта HelloMacro для типа, который пользователь аннотировал, который мы можем получить, используя #name. Реализация трейта имеет одну функцию hello_macro, тело которой содержит функциональность, которую мы хотим предоставить: вывод Hello, Macro! My name is и затем имени аннотированного типа.
Используемый здесь макрос stringify! встроен в Rust. Он принимает выражение Rust, такое как 1 + 2, и во время компиляции превращает выражение в строковый литерал, такой как "1 + 2". Это отличается от format! или println!, которые являются макросами, вычисляющими выражение и затем превращающими результат в String. Есть вероятность, что вход #name может быть выражением для буквального вывода, поэтому мы используем stringify!. Использование stringify! также сохраняет выделение памяти, преобразуя #name в строковый литерал во время компиляции.
На этом этапе cargo build должен успешно завершиться в обоих hello_macro и hello_macro_derive. Давайте подключим эти крейты к коду из листинга 20-37, чтобы увидеть процедурный макрос в действии! Создайте новый бинарный проект в вашей директории projects с помощью cargo new pancakes. Нам нужно добавить hello_macro и hello_macro_derive как зависимости в Cargo.toml крейта pancakes. Если вы публикуете свои версии hello_macro и hello_macro_derive на crates.io, они будут обычными зависимостями; если нет, вы можете указать их как зависимости по пути следующим образом:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Поместите код из листинга 20-37 в src/main.rs и запустите cargo run: он должен вывести Hello, Macro! My name is Pancakes!. Реализация трейта HelloMacro из процедурного макроса была включена без необходимости реализации в крейте pancakes; #[derive(HelloMacro)] добавил реализацию трейта.
Далее давайте explore, чем другие виды процедурных макросов отличаются от пользовательских derive-макросов.
Макросы, похожие на атрибуты
Макросы, похожие на атрибуты, аналогичны пользовательским derive-макросам, но вместо генерации кода для атрибута derive они позволяют создавать новые атрибуты. Они также более гибкие: derive работает только для структур и перечислений; атрибуты могут применяться и к другим элементам, таким как функции. Вот пример использования макроса, похожего на атрибут. Допустим, у вас есть атрибут с именем route, который аннотирует функции при использовании веб-фреймворка:
#![allow(unused)] fn main() { #[route(GET, "/")] fn index() { }
Этот атрибут #[route] был бы определён фреймворком как процедурный макрос. Сигнатура функции определения макроса выглядела бы так:
#![allow(unused)] fn main() { #[proc_macro_attribute] pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream { }
Здесь у нас два параметра типа TokenStream. Первый — для содержимого атрибута: часть GET, "/". Второй — тело элемента, к которому прикреплён атрибут: в данном случае fn index() {} и остальная часть тела функции.
Кроме этого, макросы, похожие на атрибуты, работают так же, как пользовательские derive-макросы: вы создаёте крейт с типом proc-macro и реализуете функцию, которая генерирует нужный вам код!
Макросы, похожие на функции
Макросы, похожие на функции, определяют макросы, которые выглядят как вызовы функций. Подобно макросам macro_rules!, они более гибкие, чем функции; например, они могут принимать неизвестное количество аргументов. Однако макросы macro_rules! могут быть определены только с использованием похожего на match синтаксиса, который мы обсуждали ранее в разделе «Декларативные макросы для общего метапрограммирования». Макросы, похожие на функции, принимают параметр TokenStream, и их определение манипулирует этим TokenStream с использованием кода Rust, как это делают два других типа процедурных макросов. Примером макроса, похожего на функцию, является макрос sql!, который может вызываться так:
#![allow(unused)] fn main() { let sql = sql!(SELECT * FROM posts WHERE id=1); }
Этот макрос будет разбирать SQL-запрос внутри него и проверять его синтаксическую корректность, что является гораздо более сложной обработкой, чем может выполнить макрос macro_rules!. Макрос sql! был бы определён так:
#![allow(unused)] fn main() { #[proc_macro] pub fn sql(input: TokenStream) -> TokenStream { }
Это определение похоже на сигнатуру пользовательского derive-макроса: мы получаем токены внутри скобок и возвращаем код, который хотели сгенерировать.
Заключение
Фух! Теперь у вас в инструментарии есть некоторые возможности Rust, которые вы, вероятно, не будете использовать часто, но вы будете знать, что они доступны в очень particular обстоятельствах. Мы представили несколько сложных тем, чтобы, когда вы столкнётесь с ними в предложениях сообщений об ошибках или в чужом коде, вы сможете распознать эти концепции и синтаксис. Используйте эту главу как справочник, который направит вас к решениям.
Далее мы применим всё, что обсуждали на протяжении книги, на практике и выполним ещё один проект!
Финальный проект создания Веб-сервера
Это был долгий путь, но мы достигли конца книги. В этой главе мы вместе создадим ещё один проект, чтобы продемонстрировать некоторые концепции, рассмотренные в финальных главах, а также повторим некоторые предыдущие уроки.
Для нашего финального проекта мы создадим веб-сервер, который говорит «Привет!» и выглядит в веб-браузере как на Рисунке 21-1.
Вот наш план по созданию веб-сервера:
- Изучим основы TCP и HTTP.
- Организуем прослушивание TCP-подключений на сокете.
- Реализуем разбор небольшого количества HTTP-запросов.
- Создадим корректный HTTP-ответ.
- Увеличим пропускную способность нашего сервера с помощью пула потоков.
Рисунок 21-1: Наш финальный совместный проект
Прежде чем мы начнём, следует упомянуть два момента. Во-первых, метод, который мы будем использовать, не является оптимальным способом создания веб-сервера на Rust. Участники сообщества опубликовали ряд готовых к использованию крейтов на crates.io, которые предоставляют более завершённые реализации веб-сервера и пула потоков, чем та, которую мы построим. Однако наша цель в этой главе — помочь вам учиться, а не пойти по лёгкому пути. Поскольку Rust является языком системного программирования, мы можем выбирать уровень абстракции, на котором хотим работать, и можем опуститься на более низкий уровень, чем это возможно или практично в других языках.
Во-вторых, мы не будем здесь использовать async и await. Создание пула потоков само по себе является достаточно сложной задачей без дополнительной необходимости создавать асинхронную среду выполнения! Однако мы отметим, как async и await могут быть применимы к некоторым проблемам, которые мы увидим в этой главе. В конечном счёте, как мы отмечали в Главе 17, многие асинхронные среды выполнения используют пулы потоков для управления работой.
Таким образом, мы напишем базовый HTTP-сервер и пул потоков вручную, чтобы вы могли изучить общие идеи и методы, лежащие в основе крейтов, которые вы, возможно, будете использовать в будущем.
Создание однопоточного веб-сервера
Мы начнём с создания работающего однопоточного веб-сервера. Прежде чем мы начнём, давайте кратко рассмотрим протоколы, участвующие в создании веб-серверов. Детали этих протоколов выходят за рамки данной книги, но краткий обзор даст вам необходимую информацию.
Два основных протокола, используемых в веб-серверах — это Hypertext Transfer Protocol (HTTP) и Transmission Control Protocol (TCP). Оба протокола работают по схеме «запрос-ответ», что означает, что клиент инициирует запросы, а сервер прослушивает эти запросы и предоставляет ответ клиенту. Содержимое этих запросов и ответов определяется протоколами.
TCP — это низкоуровневый протокол, который описывает детали передачи информации от одного сервера к другому, но не определяет, что представляет собой эта информация. HTTP строится поверх TCP, определяя содержимое запросов и ответов. Технически возможно использовать HTTP с другими протоколами, но в подавляющем большинстве случаев HTTP передаёт свои данные через TCP. Мы будем работать с сырыми байтами TCP- и HTTP-запросов и ответов.
Прослушивание TCP-подключения
Наш веб-сервер должен прослушивать TCP-подключения, поэтому с этого мы и начнём. Стандартная библиотека предоставляет модуль std::net, который позволяет нам это сделать. Давайте создадим новый проект обычным способом:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Теперь введите код из Листинга 21-1 в файл src/main.rs. Этот код будет прослушивать входящие TCP-потоки по локальному адресу 127.0.0.1:7878. Когда он получает входящий поток, он выводит сообщение "Connection established!".
Файл: src/main.rs
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }
Листинг 21-1: Прослушивание входящих потоков и вывод сообщения при получении потока
Используя TcpListener, мы можем прослушивать TCP-подключения по адресу 127.0.0.1:7878. В этом адресе часть перед двоеточием — это IP-адрес, представляющий ваш компьютер (этот адрес одинаков на каждом компьютере и не относится конкретно к компьютеру авторов), а 7878 — это порт. Мы выбрали этот порт по двум причинам: HTTP обычно не принимается на этом порту, поэтому наш сервер вряд ли конфликтует с любым другим веб-сервером, который может быть запущен на вашей машине, и потому что 7878 набирается как "rust" на телефонной клавиатуре.
Функция bind в этом сценарии работает подобно функции new в том смысле, что она возвращает новый экземпляр TcpListener. Функция называется bind (привязать), потому что в сетевых технологиях подключение к порту для прослушивания известно как «привязка к порту».
Функция bind возвращает Result<T, E>, что указывает на возможность неудачи привязки, например, если мы запустили два экземпляра нашей программы и thus имеем две программы, прослушивающие один и тот же порт. Поскольку мы пишем базовый сервер только в учебных целях, мы не будем беспокоиться об обработке подобных ошибок; вместо этого мы используем unwrap, чтобы остановить программу при возникновении ошибок.
Метод incoming у TcpListener возвращает итератор, который предоставляет нам последовательность потоков (точнее, потоков типа TcpStream). Один поток представляет открытое соединение между клиентом и сервером. Соединение — это название полного процесса запроса и ответа, в котором клиент подключается к серверу, сервер генерирует ответ и сервер закрывает соединение. Таким образом, мы будем читать из TcpStream, чтобы увидеть, что отправил клиент, а затем записывать наш ответ в поток, чтобы отправить данные обратно клиенту. В целом, этот цикл for будет обрабатывать каждое соединение по очереди и производить серию потоков для обработки.
На данный момент наша обработка потока состоит в вызове unwrap для завершения программы, если в потоке есть ошибки; если ошибок нет, программа выводит сообщение. Мы добавим больше функциональности для случая успеха в следующем листинге. Причина, по которой мы можем получать ошибки от метода incoming при подключении клиента к серверу, заключается в том, что мы на самом деле итерируем не по соединениям, а по попыткам соединения. Соединение может не состояться по множеству причин, многие из которых специфичны для операционной системы. Например, многие операционные системы имеют ограничение на количество одновременных открытых соединений, которые они могут поддерживать; новые попытки соединения сверх этого числа будут производить ошибку, пока некоторые из открытых соединений не будут закрыты.
Давайте попробуем запустить этот код! Вызовите cargo run в терминале, а затем загрузите 127.0.0.1:7878 в веб-браузере. Браузер должен показать сообщение об ошибке, например «Сброс соединения», потому что сервер в настоящее время не отправляет обратно никаких данных. Но если вы посмотрите на ваш терминал, вы должны увидеть несколько сообщений, которые были напечатаны, когда браузер подключился к серверу!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Иногда вы будете видеть несколько сообщений, напечатанных для одного запроса браузера; причина может быть в том, что браузер делает запрос для страницы, а также запрос для других ресурсов, таких как иконка favicon.ico, которая появляется на вкладке браузера.
Также может быть, что браузер пытается подключиться к серверу несколько раз, потому что сервер не отвечает никакими данными. Когда stream выходит из области видимости и уничтожается в конце цикла, соединение закрывается как часть реализации деструктора. Браузеры иногда обрабатывают закрытые соединения повторными попытками, потому что проблема может быть временной.
Браузеры также иногда открывают несколько соединений с сервером без отправки каких-либо запросов, чтобы если они позже отправят запросы, эти запросы могли бы обрабатываться быстрее. Когда это происходит, наш сервер будет видеть каждое соединение, независимо от того, есть ли какие-либо запросы через это соединение. Многие версии браузеров на основе Chrome делают это, например; вы можете отключить эту оптимизацию, используя режим инкогнито или другой браузер.
Важный факт заключается в том, что мы успешно получили обработчик TCP-соединения!
Не забудьте остановить программу, нажав Ctrl-C, когда закончите запуск конкретной версии кода. Затем перезапустите программу, вызвав команду cargo run после каждого набора изменений кода, чтобы убедиться, что вы запускаете самую новую версию.
Чтение запроса
Давайте реализуем функциональность для чтения запроса из браузера! Чтобы разделить ответственность между получением соединения и выполнением действий с этим соединением, мы начнём новую функцию для обработки соединений. В этой новой функции handle_connection мы будем читать данные из TCP-потока и выводить их, чтобы мы могли видеть данные, отправляемые из браузера. Измените код, чтобы он выглядел как в Листинге 21-2.
Файл: src/main.rs
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {http_request:#?}"); }
Листинг 21-2: Чтение из TcpStream и вывод данных
Мы добавляем в область видимости std::io::BufReader и std::io::prelude, чтобы получить доступ к трейтам и типам, которые позволяют нам читать из потока и записывать в него. В цикле for в функции main вместо вывода сообщения о том, что мы установили соединение, мы теперь вызываем новую функцию handle_connection и передаём ей поток.
В функции handle_connection мы создаём новый экземпляр BufReader, который оборачивает ссылку на поток. BufReader добавляет буферизацию, управляя вызовами методов трейта std::io::Read за нас.
Мы создаём переменную http_request для сбора строк запроса, которые браузер отправляет на наш сервер. Мы указываем, что хотим собрать эти строки в вектор, добавляя аннотацию типа Vec<_>.
BufReader реализует трейт std::io::BufRead, который предоставляет метод lines. Метод lines возвращает итератор Result<String, std::io::Error>, разделяя поток данных при каждом обнаружении байта новой строки. Чтобы получить каждую String, мы преобразуем и разворачиваем каждый Result с помощью map и unwrap. Result может содержать ошибку, если данные не являются валидной UTF-8 или если возникла проблема при чтении из потока. Опять же, производственная программа должна обрабатывать эти ошибки более грациозно, но мы выбираем остановку программы в случае ошибки для простоты.
Браузер сигнализирует о завершении HTTP-запроса, отправляя два символа новой строки подряд, поэтому чтобы получить один запрос из потока, мы берём строки до тех пор, пока не получим пустую строку. После того как мы собрали строки в вектор, мы выводим их с помощью форматирования отладки, чтобы мы могли взглянуть на инструкции, которые веб-браузер отправляет на наш сервер.
Давайте попробуем этот код! Запустите программу и снова сделайте запрос в веб-браузере. Обратите внимание, что мы всё ещё получим страницу с ошибкой в браузере, но вывод нашей программы в терминале теперь будет выглядеть примерно так:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
В зависимости от вашего браузера, вы можете получить немного другой вывод. Теперь, когда мы выводим данные запроса, мы можем понять, почему мы получаем несколько соединений от одного запроса браузера, посмотрев на путь после GET в первой строке запроса. Если повторяющиеся соединения все запрашивают /, мы знаем, что браузер пытается получить / повторно, потому что он не получает ответа от нашей программы.
Давайте разберём эти данные запроса, чтобы понять, что браузер просит у нашей программы.
Более детальный взгляд на HTTP-запрос
HTTP — это текстовый протокол, и запрос имеет следующий формат:
Метод URI-запроса Версия-HTTP CRLF
заголовки CRLF
тело-сообщения
Первая строка — это строка запроса, которая содержит информацию о том, что запрашивает клиент. Первая часть строки запроса указывает используемый метод, такой как GET или POST, который описывает, как клиент делает этот запрос. Наш клиент использовал GET-запрос, что означает, что он запрашивает информацию.
Следующая часть строки запроса — это /, который указывает унифицированный идентификатор ресурса (URI), который запрашивает клиент. URI почти, но не совсем, то же самое, что и унифицированный указатель ресурса (URL). Разница между URI и URL не важна для наших целей в этой главе, но спецификация HTTP использует термин URI, поэтому мы можем мысленно подставить URL вместо URI здесь.
Последняя часть — это версия HTTP, которую использует клиент, а затем строка запроса заканчивается последовательностью CRLF. (CRLF означает carriage return и line feed — термины из времён печатных машинок!) Последовательность CRLF также может быть записана как \r\n, где \r — это возврат каретки, а \n — перевод строки. Последовательность CRLF отделяет строку запроса от остальных данных запроса. Обратите внимание, что когда CRLF выводится на печать, мы видим начало новой строки, а не \r\n.
Глядя на данные строки запроса, которые мы получили при запуске нашей программы, мы видим, что GET — это метод, / — это URI запроса, а HTTP/1.1 — это версия.
После строки запроса оставшиеся строки, начиная с Host:, являются заголовками. GET-запросы не имеют тела.
Попробуйте сделать запрос из другого браузера или запросить другой адрес, например 127.0.0.1:7878/test, чтобы увидеть, как изменяются данные запроса.
Теперь, когда мы знаем, что запрашивает браузер, давайте отправим обратно некоторые данные!
Написание ответа
Мы собираемся реализовать отправку данных в ответ на запрос клиента. Ответы имеют следующий формат:
Версия-HTTP Код-статуса Пояснение-статуса CRLF
заголовки CRLF
тело-сообщения
Первая строка — это строка статуса, которая содержит версию HTTP, используемую в ответе, числовой код статуса, который суммирует результат запроса, и поясняющую фразу, которая предоставляет текстовое описание кода статуса. После последовательности CRLF идут любые заголовки, другая последовательность CRLF и тело ответа.
Вот пример ответа, который использует HTTP версию 1.1, имеет код статуса 200, поясняющую фразу OK, без заголовков и без тела:
HTTP/1.1 200 OK\r\n\r\n
Код статуса 200 — это стандартный успешный ответ. Этот текст представляет собой крошечный успешный HTTP-ответ. Давайте запишем это в поток как наш ответ на успешный запрос! Из функции handle_connection удалите println!, который выводил данные запроса, и замените его кодом из Листинга 21-3.
Файл: src/main.rs
#![allow(unused)] fn main() { fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); } }
Листинг 21-3: Запись крошечного успешного HTTP-ответа в поток
Первая новая строка определяет переменную response, которая содержит данные сообщения об успехе. Затем мы вызываем as_bytes для нашего ответа, чтобы преобразовать строковые данные в байты. Метод write_all у потока принимает &[u8] и отправляет эти байты непосредственно через соединение. Поскольку операция write_all может завершиться неудачей, мы используем unwrap для любого результата с ошибкой, как и раньше. Опять же, в реальном приложении вы должны добавить обработку ошибок здесь.
С этими изменениями давайте запустим наш код и сделаем запрос. Мы больше не выводим никакие данные в терминал, поэтому мы не увидим никакого вывода, кроме вывода от Cargo. Когда вы загрузите 127.0.0.1:7878 в веб-браузере, вы должны получить пустую страницу вместо ошибки. Вы только что вручную закодировали получение HTTP-запроса и отправку ответа!
Возврат реального HTML
Давайте реализуем функциональность для возврата чего-то большего, чем просто пустая страница. Создайте новый файл hello.html в корневой директории вашего проекта, а не в директории src. Вы можете ввести любой HTML-код; Листинг 21-4 показывает один из возможных вариантов.
Файл: hello.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Листинг 21-4: Пример HTML-файла для возврата в ответе
Это минимальный HTML5-документ с заголовком и некоторым текстом. Чтобы возвращать его с сервера при получении запроса, мы изменим handle_connection, как показано в Листинге 21-5, чтобы прочитать HTML-файл, добавить его в ответ в качестве тела и отправить.
Файл: src/main.rs
#![allow(unused)] fn main() { use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; // --пропуск-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); } }
Листинг 21-5: Отправка содержимого hello.html в качестве тела ответа
Мы добавили fs в оператор use, чтобы включить модуль файловой системы стандартной библиотеки в область видимости. Код для чтения содержимого файла в строку должен выглядеть знакомо; мы использовали его, когда читали содержимое файла для нашего I/O-проекта в Листинге 12-4.
Далее мы используем format! для добавления содержимого файла в качестве тела успешного ответа. Чтобы обеспечить валидный HTTP-ответ, мы добавляем заголовок Content-Length, который устанавливается в размер тела нашего ответа — в данном случае, размер hello.html.
Запустите этот код с помощью cargo run и загрузите 127.0.0.1:7878 в вашем браузере; вы должны увидеть ваш отрендеренный HTML!
В настоящее время мы игнорируем данные запроса в http_request и просто без условий возвращаем содержимое HTML-файла. Это означает, что если вы попытаетесь запросить 127.0.0.1:7878/something-else в вашем браузере, вы всё равно получите тот же HTML-ответ. На данный момент наш сервер очень ограничен и не делает того, что делают большинство веб-серверов. Мы хотим настраивать наши ответы в зависимости от запроса и возвращать HTML-файл только для корректного запроса к /.
Проверка запроса и выборочный ответ
Сейчас наш веб-сервер будет возвращать HTML из файла независимо от того, что запросил клиент. Давайте добавим функциональность для проверки, что браузер запрашивает /, перед возвратом HTML-файла, и возвращать ошибку, если браузер запрашивает что-либо ещё. Для этого нам нужно изменить handle_connection, как показано в Листинге 21-6. Этот новый код проверяет содержимое полученного запроса против того, как выглядит запрос для /, и добавляет блоки if и else для обработки запросов по-разному.
Файл: src/main.rs
#![allow(unused)] fn main() { // --пропуск-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // какой-то другой запрос } } }
Листинг 21-6: Обработка запросов к / иначе, чем других запросов
Мы будем смотреть только на первую строку HTTP-запроса, поэтому вместо чтения всего запроса в вектор мы вызываем next, чтобы получить первый элемент из итератора. Первый unwrap обрабатывает Option и останавливает программу, если в итераторе нет элементов. Второй unwrap обрабатывает Result и имеет тот же эффект, что и unwrap, который был в map, добавленном в Листинге 21-2.
Далее мы проверяем request_line, чтобы увидеть, равна ли она строке запроса GET-запроса к пути /. Если это так, блок if возвращает содержимое нашего HTML-файла.
Если request_line не равна GET-запросу к пути /, это означает, что мы получили какой-то другой запрос. Мы добавим код в блок else чуть позже, чтобы отвечать на все другие запросы.
Запустите этот код сейчас и запросите 127.0.0.1:7878; вы должны получить HTML из hello.html. Если вы сделаете любой другой запрос, например 127.0.0.1:7878/something-else, вы получите ошибку соединения, подобную тем, которые вы видели при запуске кода в Листинге 21-1 и Листинге 21-2.
Теперь давайте добавим код из Листинга 21-7 в блок else, чтобы возвращать ответ с кодом статуса 404, который сигнализирует, что содержимое для запроса не найдено. Мы также вернём некоторый HTML для страницы, которая будет отображаться в браузере, указывая на ответ конечному пользователю.
Файл: src/main.rs
#![allow(unused)] fn main() { // --пропуск-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
Листинг 21-7: Ответ с кодом статуса 404 и страницей ошибки, если запрашивается что-либо кроме /
Здесь наш ответ имеет строку статуса с кодом 404 и поясняющей фразой NOT FOUND. Тело ответа будет HTML из файла 404.html. Вам нужно будет создать файл 404.html рядом с hello.html для страницы ошибки; опять же, не стесняйтесь использовать любой HTML, который вы хотите, или используйте пример HTML из Листинга 21-8.
Файл: 404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Листинг 21-8: Пример содержимого для страницы, возвращаемой с любым ответом 404
С этими изменениями снова запустите ваш сервер. Запрос 127.0.0.1:7878 должен возвращать содержимое hello.html, а любой другой запрос, например 127.0.0.1:7878/foo, должен возвращать HTML с ошибкой из 404.html.
Рефакторинг
На данный момент блоки if и else содержат много повторяющегося кода: они оба читают файлы и записывают содержимое файлов в поток. Единственные различия — это строка статуса и имя файла. Давайте сделаем код более лаконичным, вынеся эти различия в отдельные строки if и else, которые будут присваивать значения строки статуса и имени файла переменным; затем мы можем использовать эти переменные безусловно в коде для чтения файла и записи ответа. Листинг 21-9 показывает результирующий код после замены больших блоков if и else.
Файл: src/main.rs
#![allow(unused)] fn main() { // --пропуск-- fn handle_connection(mut stream: TcpStream) { // --пропуск-- let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); } }
Листинг 21-9: Рефакторинг блоков if и else для содержания только кода, который различается между двумя случаями
Теперь блоки if и else только возвращают соответствующие значения для строки статуса и имени файла в кортеже; затем мы используем деструктуризацию, чтобы присвоить эти два значения status_line и filename с помощью шаблона в операторе let, как обсуждалось в Главе 19.
Ранее дублированный код теперь находится вне блоков if и else и использует переменные status_line и filename. Это упрощает понимание различий между двумя случаями и означает, что у нас есть только одно место для обновления кода, если мы хотим изменить работу чтения файлов и записи ответов. Поведение кода в Листинге 21-9 будет таким же, как в Листинге 21-7.
Отлично! Теперь у нас есть простой веб-сервер примерно в 40 строках кода на Rust, который отвечает на один запрос страницей с содержимым и отвечает на все другие запросы ответом 404.
В настоящее время наш сервер работает в одном потоке, что означает, что он может обрабатывать только один запрос за раз. Давайте рассмотрим, как это может стать проблемой, смоделировав несколько медленных запросов. Затем мы исправим это, чтобы наш сервер мог обрабатывать несколько запросов одновременно.
От однопоточного к многопоточному серверу
В настоящее время сервер обрабатывает каждый запрос последовательно, что означает, что он не будет обрабатывать второе соединение, пока не закончится обработка первого. Если сервер получает всё больше и больше запросов, такое последовательное выполнение становится всё менее оптимальным. Если сервер получает запрос, обработка которого занимает много времени, последующие запросы должны будут ждать, пока длинный запрос не завершится, даже если новые запросы могут быть обработаны быстро. Нам нужно это исправить, но сначала мы посмотрим на проблему в действии.
Имитация медленного запроса
Мы посмотрим, как медленно обрабатываемый запрос может повлиять на другие запросы в нашей текущей реализации сервера. Листинг 21-10 реализует обработку запроса к /sleep с имитацией медленного ответа, который заставит сервер спать в течение пяти секунд перед ответом.
Файл: src/main.rs
#![allow(unused)] fn main() { use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --пропуск-- fn handle_connection(mut stream: TcpStream) { // --пропуск-- let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --пропуск-- } }
Листинг 21-10: Имитация медленного запроса с помощью задержки на пять секунд
Мы перешли от if к match, так как теперь у нас три случая. Нам нужно явно сопоставить срез request_line со строковыми литеральными значениями; match не выполняет автоматического взятия ссылки и разыменования, как это делает метод равенства.
Первая ветка такая же, как блок if из Листинга 21-9. Вторая ветка соответствует запросу к /sleep. Когда этот запрос получен, сервер будет спать в течение пяти секунд перед отображением успешной HTML-страницы. Третья ветка такая же, как блок else из Листинга 21-9.
Вы можете видеть, насколько примитивен наш сервер: реальные библиотеки обрабатывали бы распознавание нескольких запросов гораздо менее многословным способом!
Запустите сервер с помощью cargo run. Затем откройте два окна браузера: одно для http://127.0.0.1:7878 и другое для http://127.0.0.1:7878/sleep. Если вы введёте URI / несколько раз, как и раньше, вы увидите, что он быстро отвечает. Но если вы введёте /sleep и затем загрузите /, вы увидите, что / ждёт, пока sleep не проспит свои полные пять секунд, прежде чем загрузиться.
Существует несколько техник, которые мы могли бы использовать, чтобы избежать накопления запросов из-за медленного запроса, включая использование async, как мы делали в Главе 17; та, которую мы реализуем — это пул потоков.
Улучшение пропускной способности с помощью пула потоков
Пул потоков — это группа заранее созданных потоков, которые готовы и ожидают обработки задачи. Когда программа получает новую задачу, она назначает один из потоков в пуле для этой задачи, и этот поток будет обрабатывать задачу. Оставшиеся потоки в пуле доступны для обработки любых других задач, которые поступают, пока первый поток обрабатывает свою задачу. Когда первый поток завершает обработку своей задачи, он возвращается в пул свободных потоков, готовый обработать новую задачу. Пул потоков позволяет обрабатывать соединения параллельно, увеличивая пропускную способность вашего сервера.
Мы ограничим количество потоков в пуле небольшим числом, чтобы защититься от DoS-атак; если бы наша программа создавала новый поток для каждого поступающего запроса, кто-то, делая 10 миллионов запросов к нашему серверу, мог бы устроить хаос, исчерпав все ресурсы нашего сервера и полностью остановив обработку запросов.
Вместо создания неограниченного количества потоков мы будем иметь фиксированное количество потоков, ожидающих в пуле. Поступающие запросы отправляются в пул для обработки. Пул будет поддерживать очередь входящих запросов. Каждый из потоков в пуле будет брать запрос из этой очереди, обрабатывать его, а затем запрашивать следующий запрос из очереди. При такой конструкции мы можем обрабатывать до N запросов одновременно, где N — количество потоков. Если каждый поток обрабатывает долгий запрос, последующие запросы всё равно могут накапливаться в очереди, но мы увеличили количество долгих запросов, которые можем обработать до достижения этой точки.
Эта техника — лишь один из многих способов улучшить пропускную способность веб-сервера. Другие варианты, которые вы можете исследовать, — это модель fork/join, однопоточная модель асинхронного I/O и многопоточная модель асинхронного I/O. Если вам интересна эта тема, вы можете почитать о других решениях и попробовать реализовать их; с низкоуровневым языком вроде Rust все эти варианты возможны.
Прежде чем мы начнём реализацию пула потоков, давайте обсудим, как должно выглядеть использование пула. Когда вы пытаетесь спроектировать код, написание клиентского интерфейса сначала может помочь направлять ваш дизайн. Напишите API кода так, чтобы он был структурирован так, как вы хотите его вызывать; затем реализуйте функциональность внутри этой структуры, вместо того чтобы реализовывать функциональность и затем проектировать публичный API.
Подобно тому, как мы использовали разработку через тестирование в проекте в Главе 12, мы здесь используем разработку через компилятор. Мы напишем код, который вызывает функции, которые мы хотим, а затем посмотрим на ошибки от компилятора, чтобы определить, что нам следует изменить дальше, чтобы код заработал. Однако прежде чем мы сделаем это, мы исследуем технику, которую не будем использовать в качестве отправной точки.
Создание потока для каждого запроса
Сначала давайте исследуем, как мог бы выглядеть наш код, если бы он создавал новый поток для каждого соединения. Как упоминалось ранее, это не наш окончательный план из-за проблем с потенциальным созданием неограниченного количества потоков, но это отправная точка, чтобы сначала получить работающий многопоточный сервер. Затем мы добавим пул потоков как улучшение, и сравнение двух решений будет проще.
Листинг 21-11 показывает изменения, которые нужно внести в main, чтобы создавать новый поток для обработки каждого потока внутри цикла for.
Файл: src/main.rs
fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } }
Листинг 21-11: Создание нового потока для каждого потока соединения
Как вы узнали в Главе 16, thread::spawn создаст новый поток, а затем запустит код в замыкании в новом потоке. Если вы запустите этот код и загрузите /sleep в вашем браузере, а затем / в двух дополнительных вкладках браузера, вы действительно увидите, что запросы к / не должны ждать завершения /sleep. Однако, как мы упоминали, это в конечном итоге перегрузит систему, потому что вы создаёте новые потоки без каких-либо ограничений.
Вы также можете вспомнить из Главы 17, что это именно та ситуация, где async и await действительно сияют! Держите это в уме, пока мы создаём пул потоков, и подумайте о том, как всё будет выглядеть по-другому или так же с использованием async.
Создание ограниченного количества потоков
Мы хотим, чтобы наш пул потоков работал похожим, знакомым образом, чтобы переход от потоков к пулу потоков не требовал больших изменений в коде, использующем наш API. Листинг 21-12 показывает гипотетический интерфейс для структуры ThreadPool, который мы хотим использовать вместо thread::spawn.
Файл: src/main.rs
[Этот код не компилируется!] fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); let pool = ThreadPool::new(4); for stream in listener.incoming() { let stream = stream.unwrap(); pool.execute(|| { handle_connection(stream); }); } }
Листинг 21-12: Наш идеальный интерфейс ThreadPool
Мы используем ThreadPool::new для создания нового пула потоков с настраиваемым количеством потоков, в данном случае четыре. Затем в цикле for pool.execute имеет интерфейс, похожий на thread::spawn, в том смысле, что он принимает замыкание, которое пул должен выполнить для каждого потока. Нам нужно реализовать pool.execute так, чтобы он принимал замыкание и передавал его потоку в пуле для выполнения. Этот код пока не будет компилироваться, но мы попробуем, чтобы компилятор мог направить нас в том, как это исправить.
Создание ThreadPool с помощью разработки через компилятор
Внесите изменения из Листинга 21-12 в src/main.rs, и затем давайте используем ошибки компилятора из cargo check для управления нашей разработкой. Вот первая ошибка, которую мы получаем:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Отлично! Эта ошибка говорит нам, что нам нужен тип или модуль ThreadPool, поэтому мы создадим его сейчас. Наша реализация ThreadPool будет независимой от вида работы, которую выполняет наш веб-сервер. Поэтому давайте переключим крейт hello из бинарного крейта в библиотечный крейт, чтобы разместить нашу реализацию ThreadPool. После изменения на библиотечный крейт мы также могли бы использовать отдельную библиотеку пула потоков для любой работы, которую мы хотим выполнять с использованием пула потоков, а не только для обслуживания веб-запросов.
Создайте файл src/lib.rs, который содержит следующее — это простейшее определение структуры ThreadPool, которое мы можем иметь на данный момент:
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct ThreadPool; }
Затем отредактируйте файл main.rs, чтобы включить ThreadPool в область видимости из библиотечного крейта, добавив следующий код в начало src/main.rs:
Файл: src/main.rs
#![allow(unused)] fn main() { use hello::ThreadPool; }
Этот код всё ещё не будет работать, но давайте проверим его снова, чтобы получить следующую ошибку, которую нам нужно решить:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Эта ошибка указывает, что далее нам нужно создать ассоциированную функцию с именем new для ThreadPool. Мы также знаем, что new должен иметь один параметр, который может принимать 4 в качестве аргумента, и должен возвращать экземпляр ThreadPool. Давайте реализуем простейшую функцию new, которая будет иметь эти характеристики:
Файл: src/lib.rs
#![allow(unused)] fn main() { pub struct ThreadPool; impl ThreadPool { pub fn new(size: usize) -> ThreadPool { ThreadPool } } }
Мы выбрали usize в качестве типа параметра size, потому что знаем, что отрицательное количество потоков не имеет смысла. Мы также знаем, что будем использовать это 4 как количество элементов в коллекции потоков, для чего и предназначен тип usize, как обсуждалось в разделе "Целочисленные типы" в Главе 3.
Давайте проверим код снова:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Теперь ошибка возникает потому, что у нас нет метода execute у ThreadPool. Вспомните из раздела "Создание ограниченного количества потоков", что мы решили, что наш пул потоков должен иметь интерфейс, похожий на thread::spawn. Кроме того, мы реализуем функцию execute так, чтобы она принимала переданное ей замыкание и передавала его свободному потоку в пуле для выполнения.
Мы определим метод execute для ThreadPool, чтобы принимать замыкание в качестве параметра. Вспомните из раздела "Перемещение захваченных значений из замыканий" в Главе 13, что мы можем принимать замыкания в качестве параметров с тремя разными трейтами: Fn, FnMut и FnOnce. Нам нужно решить, какой тип замыкания использовать здесь. Мы знаем, что в конечном итоге мы будем делать что-то похожее на реализацию thread::spawn из стандартной библиотеки, поэтому мы можем посмотреть, какие ограничения имеет сигнатура thread::spawn на её параметр. Документация показывает нам следующее:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
Параметр типа F — это тот, который нас здесь интересует; параметр типа T связан с возвращаемым значением, и он нас не интересует. Мы видим, что spawn использует FnOnce как ограничение трейта для F. Это, вероятно, то, что мы тоже хотим, потому что мы в конечном итоге передадим аргумент, который мы получаем в execute, в spawn. Мы можем быть ещё более уверены, что FnOnce — это трейт, который мы хотим использовать, потому что поток для выполнения запроса будет выполнять замыкание этого запроса только один раз, что соответствует Once в FnOnce.
Параметр типа F также имеет ограничение трейта Send и ограничение времени жизни 'static, которые полезны в нашей ситуации: нам нужен Send для передачи замыкания из одного потока в другой и 'static, потому что мы не знаем, сколько времени потоку потребуется для выполнения. Давайте создадим метод execute для ThreadPool, который будет принимать обобщённый параметр типа F с этими ограничениями:
Файл: src/lib.rs
#![allow(unused)] fn main() { impl ThreadPool { // --пропуск-- pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { } } }
Мы всё ещё используем () после FnOnce, потому что этот FnOnce представляет замыкание, которое не принимает параметров и возвращает тип unit (). Как и в определениях функций, тип возвращаемого значения может быть опущен в сигнатуре, но даже если у нас нет параметров, нам всё ещё нужны круглые скобки.
Опять же, это простейшая реализация метода execute: он ничего не делает, но мы только пытаемся заставить наш код скомпилироваться. Давайте проверим его снова:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Он компилируется! Но обратите внимание, что если вы попробуете cargo run и сделаете запрос в браузере, вы увидите в браузере те же ошибки, которые мы видели в начале главы. Наша библиотека на самом деле ещё не вызывает замыкание, переданное в execute!
Примечание: Вы можете слышать высказывание о языках со строгими компиляторами, таких как Haskell и Rust: «Если код компилируется, он работает». Но это высказывание не всегда верно. Наш проект компилируется, но он абсолютно ничего не делает! Если бы мы строили реальный, законченный проект, сейчас было бы хорошее время начать писать модульные тесты, чтобы проверить, что код компилируется и имеет поведение, которое мы хотим.
Вопрос для размышления: Что бы здесь изменилось, если бы мы собирались выполнить future (футуру) вместо замыкания?
Проверка количества потоков в new
Мы ничего не делаем с параметрами для new и execute. Давайте реализуем тела этих функций с тем поведением, которое мы хотим. Для начала давайте подумаем о new. Ранее мы выбрали беззнаковый тип для параметра size, потому что пул с отрицательным количеством потоков не имеет смысла. Однако пул с нулём потоков также не имеет смысла, но ноль является совершенно допустимым usize. Мы добавим код для проверки, что size больше нуля, прежде чем возвращать экземпляр ThreadPool, и заставим программу паниковать, если она получает ноль, с помощью макроса assert!, как показано в Листинге 21-13.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl ThreadPool { /// Создаёт новый ThreadPool. /// /// Параметр size - количество потоков в пуле. /// /// # Паника /// /// Функция `new` будет паниковать, если size равен нулю. pub fn new(size: usize) -> ThreadPool { assert!(size > 0); ThreadPool } // --пропуск-- } }
Листинг 21-13: Реализация ThreadPool::new с паникой при size = 0
Мы также добавили некоторую документацию для нашего ThreadPool с помощью комментарией документации. Обратите внимание, что мы следовали хорошим практикам документации, добавив раздел, который указывает ситуации, в которых наша функция может паниковать, как обсуждалось в Главе 14. Попробуйте запустить cargo doc --open и нажать на структуру ThreadPool, чтобы посмотреть, как сгенерированная документация для new выглядит!
Вместо добавления макроса assert!, как мы сделали здесь, мы могли бы изменить new на build и возвращать Result, как мы делали с Config::build в I/O-проекте в Листинге 12-9. Но мы решили, что в данном случае попытка создать пул потоков без каких-либо потоков должна быть неустранимой ошибкой. Если вы чувствуете амбиции, попробуйте написать функцию с именем build со следующей сигнатурой для сравнения с функцией new:
#![allow(unused)] fn main() { pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> { }
Создание места для хранения потоков
Теперь, когда у нас есть способ узнать, что у нас есть допустимое количество потоков для хранения в пуле, мы можем создать эти потоки и сохранить их в структуре ThreadPool перед возвратом структуры. Но как мы "храним" поток? Давайте ещё раз посмотрим на сигнатуру thread::spawn:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
Функция spawn возвращает JoinHandle<T>, где T — это тип, который возвращает замыкание. Давайте попробуем тоже использовать JoinHandle и посмотрим, что произойдёт. В нашем случае замыкания, которые мы передаём в пул потоков, будут обрабатывать соединение и ничего не возвращать, поэтому T будет типом unit ().
Код в Листинге 21-14 будет компилироваться, но он пока не создаёт никаких потоков. Мы изменили определение ThreadPool, чтобы он содержал вектор экземпляров thread::JoinHandle<()>, инициализировали вектор с вместимостью size, настроили цикл for, который будет запускать некоторый код для создания потоков, и вернули экземпляр ThreadPool, содержащий их.
Файл: src/lib.rs
#![allow(unused)] fn main() { [Этот код не производит желаемого поведения.] use std::thread; pub struct ThreadPool { threads: Vec<thread::JoinHandle<()>>, } impl ThreadPool { // --пропуск-- pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let mut threads = Vec::with_capacity(size); for _ in 0..size { // создаём некоторые потоки и сохраняем их в векторе } ThreadPool { threads } } // --пропуск-- } }
Листинг 21-14: Создание вектора для ThreadPool для хранения потоков
Мы добавили std::thread в область видимости в библиотечном крейте, потому что мы используем thread::JoinHandle в качестве типа элементов в векторе в ThreadPool.
После получения допустимого размера наш ThreadPool создаёт новый вектор, который может содержать size элементов. Функция with_capacity выполняет ту же задачу, что и Vec::new, но с важным отличием: она предварительно выделяет место в векторе. Поскольку мы знаем, что нам нужно хранить size элементов в векторе, выполнение этого выделения заранее немного более эффективно, чем использование Vec::new, который изменяет свой размер по мере вставки элементов.
Когда вы снова запустите cargo check, он должен завершиться успешно.
Отправка кода из ThreadPool в поток
Мы оставили комментарий в цикле for в Листинге 21-14 относительно создания потоков. Здесь мы рассмотрим, как мы фактически создаём потоки. Стандартная библиотека предоставляет thread::spawn как способ создания потоков, и thread::spawn ожидает получить некоторый код, который поток должен выполнить сразу после создания. Однако в нашем случае мы хотим создать потоки и заставить их ждать код, который мы отправим позже. Реализация потоков в стандартной библиотеке не включает никакого способа сделать это; мы должны реализовать это вручную.
Мы реализуем это поведение, введя новую структуру данных между ThreadPool и потоками, которая будет управлять этим новым поведением. Мы назовём эту структуру данных Worker (Работник), что является распространённым термином в реализациях пулов. Worker получает код, который нужно выполнить, и выполняет этот код в своём потоке.
Представьте себе людей, работающих на кухне ресторана: работники ждут, пока поступят заказы от клиентов, а затем они отвечают за принятие этих заказов и их выполнение.
Вместо хранения вектора экземпляров JoinHandle<()> в пуле потоков мы будем хранить экземпляры структуры Worker. Каждый Worker будет хранить один экземпляр JoinHandle<()>. Затем мы реализуем метод для Worker, который будет принимать замыкание кода для выполнения и отправлять его уже запущенному потоку для выполнения. Мы также дадим каждому Worker идентификатор (id), чтобы мы могли различать различные экземпляры Worker в пуле при логировании или отладке.
Вот новый процесс, который будет происходить при создании ThreadPool. Мы реализуем код, который отправляет замыкание в поток, после того как настроим Worker таким образом:
- Определим структуру
Worker, которая содержитidиJoinHandle<()> - Изменим
ThreadPoolдля хранения вектора экземпляровWorker - Определим функцию
Worker::new, которая принимает номерidи возвращает экземплярWorker, содержащийidи поток, созданный с пустым замыканием - В
ThreadPool::newиспользуем счётчик циклаforдля генерацииid, создадим новогоWorkerс этимidи сохранимWorkerв векторе
Если вы готовы к challenge, попробуйте реализовать эти изменения самостоятельно, прежде чем смотреть на код в Листинге 21-15.
Готовы? Вот Листинг 21-15 с одним из способов внесения указанных изменений.
Файл: src/lib.rs
#![allow(unused)] fn main() { use std::thread; pub struct ThreadPool { workers: Vec<Worker>, } impl ThreadPool { // --пропуск-- pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id)); } ThreadPool { workers } } // --пропуск-- } struct Worker { id: usize, thread: thread::JoinHandle<()>, } impl Worker { fn new(id: usize) -> Worker { let thread = thread::spawn(|| {}); Worker { id, thread } } } }
Листинг 21-15: Изменение ThreadPool для хранения экземпляров Worker вместо прямого хранения потоков
Мы изменили имя поля в ThreadPool с threads на workers, потому что теперь он хранит экземпляры Worker вместо экземпляров JoinHandle<()>. Мы используем счётчик в цикле for в качестве аргумента для Worker::new и сохраняем каждого нового Worker в векторе с именем workers.
Внешний код (например, наш сервер в src/main.rs) не должен знать детали реализации относительно использования структуры Worker внутри ThreadPool, поэтому мы делаем структуру Worker и её функцию new приватными. Функция Worker::new использует переданный ей id и сохраняет экземпляр JoinHandle<()>, который создаётся путём порождения нового потока с использованием пустого замыкания.
Примечание: Если операционная система не может создать поток из-за недостатка системных ресурсов, thread::spawn вызовет панику. Это вызовет панику всего нашего сервера, даже если создание некоторых потоков могло бы завершиться успешно. Для простоты такое поведение приемлемо, но в производственной реализации пула потоков вы, вероятно, захотите использовать std::thread::Builder и его метод spawn, который возвращает Result.
Этот код будет компилироваться и сохранять количество экземпляров Worker, которое мы указали в качестве аргумента для ThreadPool::new. Но мы всё ещё не обрабатываем замыкание, которое получаем в execute. Давайте посмотрим, как это сделать дальше.
Отправка запросов в потоки через каналы
Следующая проблема, которую мы решим, заключается в том, что замыкания, переданные в thread::spawn, абсолютно ничего не делают. В настоящее время мы получаем замыкание, которое хотим выполнить, в методе execute. Но нам нужно передать thread::spawn замыкание для выполнения при создании каждого Worker во время создания ThreadPool.
Мы хотим, чтобы созданные нами структуры Worker получали код для выполнения из очереди, хранящейся в ThreadPool, и отправляли этот код в свой поток для выполнения.
Каналы, которые мы изучили в Главе 16 — простой способ общения между двумя потоками — идеально подходят для этого случая использования. Мы будем использовать канал в качестве очереди заданий, и execute будет отправлять задание из ThreadPool в экземпляры Worker, которые будут отправлять задание в свой поток. Вот план:
ThreadPoolсоздаст канал и будет хранить отправитель (sender)- Каждый
Workerбудет хранить получатель (receiver) - Мы создадим новую структуру
Job, которая будет содержать замыкания, которые мы хотим отправить через канал - Метод
executeбудет отправлять задание, которое он хочет выполнить, через отправитель - В своём потоке
Workerбудет циклически опрашивать свой получатель и выполнять замыкания любых полученных заданий
Давайте начнём с создания канала в ThreadPool::new и хранения отправителя в экземпляре ThreadPool, как показано в Листинге 21-16. Структура Job пока ничего не содержит, но будет типом элемента, который мы отправляем через канал.
Файл: src/lib.rs
#![allow(unused)] fn main() { use std::{sync::mpsc, thread}; pub struct ThreadPool { workers: Vec<Worker>, sender: mpsc::Sender<Job>, } struct Job; impl ThreadPool { // --пропуск-- pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id)); } ThreadPool { workers, sender } } // --пропуск-- } }
Листинг 21-16: Изменение ThreadPool для хранения отправителя канала, передающего экземпляры Job
В ThreadPool::new мы создаём наш новый канал и заставляем пул хранить отправитель. Этот код успешно скомпилируется.
Давайте попробуем передать получатель канала в каждый Worker при создании пула потоков. Мы знаем, что хотим использовать получатель в потоке, который создают экземпляры Worker, поэтому мы будем ссылаться на параметр receiver в замыкании. Код в Листинге 21-17 пока не будет компилироваться.
Файл: src/lib.rs
#![allow(unused)] fn main() { [Этот код не компилируется!] impl ThreadPool { // --пропуск-- pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id, receiver)); } ThreadPool { workers, sender } } // --пропуск-- } // --пропуск-- impl Worker { fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker { let thread = thread::spawn(|| { receiver; }); Worker { id, thread } } } }
Листинг 21-17: Передача получателя каждому Worker
Мы сделали небольшие и простые изменения: мы передаём receiver в Worker::new, а затем используем его внутри замыкания.
Когда мы пытаемся проверить этот код, мы получаем следующую ошибку:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
Код пытается передать receiver нескольким экземплярам Worker. Это не сработает, как вы помните из Главы 16: реализация канала, предоставляемая Rust, имеет тип "множество производителей, один потребитель". Это означает, что мы не можем просто клонировать потребительский конец канала, чтобы исправить этот код. Мы также не хотим отправлять сообщение несколько раз нескольким потребителям; мы хотим один список сообщений с несколькими экземплярами Worker, чтобы каждое сообщение обрабатывалось один раз.
Кроме того, извлечение задания из очереди канала involves изменение receiver, поэтому потокам нужен безопасный способ совместного использования и изменения receiver; в противном случае мы можем получить состояние гонки (как рассматривалось в Главе 16).
Вспомните потокобезопасные умные указатели, обсуждавшиеся в Главе 16: чтобы разделить владение между несколькими потоками и позволить потокам изменять значение, нам нужно использовать Arc<Mutex<T>>. Тип Arc позволит нескольким экземплярам Worker владеть receiver, а Mutex гарантирует, что только один Worker получает задание из receiver в любой момент времени. Листинг 21-18 показывает изменения, которые нам нужно сделать.
Файл: src/lib.rs
#![allow(unused)] fn main() { use std::{ sync::{Arc, Mutex, mpsc}, thread, }; // --пропуск-- impl ThreadPool { // --пропуск-- pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let receiver = Arc::new(Mutex::new(receiver)); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id, Arc::clone(&receiver))); } ThreadPool { workers, sender } } // --пропуск-- } // --пропуск-- impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { // --пропуск-- } } }
Листинг 21-18: Совместное использование получателя среди экземпляров Worker с помощью Arc и Mutex
В ThreadPool::new мы помещаем receiver в Arc и Mutex. Для каждого нового Worker мы клонируем Arc, чтобы увеличить счётчик ссылок, чтобы экземпляры Worker могли совместно владеть receiver.
С этими изменениями код компилируется! Мы почти у цели!
Реализация метода execute
Давайте наконец реализуем метод execute для ThreadPool. Мы также изменим Job из структуры на псевдоним типа для типажа-объекта, который содержит тип замыкания, получаемого execute. Как обсуждалось в разделе "Синонимы типов и псевдонимы типов" в Главе 20, псевдонимы типов позволяют нам делать длинные типы короче для удобства использования. Посмотрите на Листинг 21-19.
Файл: src/lib.rs
#![allow(unused)] fn main() { // --пропуск-- type Job = Box<dyn FnOnce() + Send + 'static>; impl ThreadPool { // --пропуск-- pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.sender.send(job).unwrap(); } } // --пропуск-- }
Листинг 21-19: Создание псевдонима типа Job для Box, содержащего каждое замыкание, и отправка задания через канал
После создания нового экземпляра Job с использованием замыкания, которое мы получаем в execute, мы отправляем это задание через передающий конец канала. Мы вызываем unwrap на send на случай, если отправка не удастся. Это может произойти, если, например, мы остановим выполнение всех наших потоков, что означает, что принимающий конец перестал получать новые сообщения. На данный момент мы не можем остановить выполнение наших потоков: наши потоки продолжают выполняться, пока существует пул. Причина, по которой мы используем unwrap, заключается в том, что мы знаем, что случай неудачи не произойдёт, но компилятор этого не знает.
Но мы ещё не совсем закончили! В Worker наше замыкание, передаваемое в thread::spawn, всё ещё только ссылается на принимающий конец канала. Вместо этого нам нужно, чтобы замыкание работало в бесконечном цикле, запрашивая задание у принимающего конца канала и выполняя задание, когда оно его получает. Давайте внесём изменение, показанное в Листинге 21-20, в Worker::new.
Файл: src/lib.rs
#![allow(unused)] fn main() { // --пропуск-- impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let job = receiver.lock().unwrap().recv().unwrap(); println!("Worker {id} got a job; executing."); job(); } }); Worker { id, thread } } } }
Листинг 21-20: Получение и выполнение заданий в потоке экземпляра Worker
Здесь мы сначала вызываем lock на receiver, чтобы получить мьютекс, а затем вызываем unwrap для паники при любых ошибках. Получение блокировки может завершиться неудачей, если мьютекс находится в "отравленном" состоянии, что может произойти, если какой-либо другой поток запаниковал, удерживая блокировку, вместо того чтобы освободить её. В этой ситуации вызов unwrap для паники этого потока является правильным действием. Не стесняйтесь заменить этот unwrap на expect с сообщением об ошибке, которое имеет для вас смысл.
Если мы получаем блокировку мьютекса, мы вызываем recv, чтобы получить Job из канала. Последний unwrap также игнорирует любые ошибки здесь, которые могут возникнуть, если поток, удерживающий отправитель, завершил работу, аналогично тому, как метод send возвращает Err, если получатель завершает работу.
Вызов recv блокируется, поэтому если задания ещё нет, текущий поток будет ждать, пока задание не станет доступным. Mutex<T> гарантирует, что только один поток Worker в данный момент пытается запросить задание.
Наш пул потоков теперь находится в рабочем состоянии! Запустите его с помощью cargo run и сделайте несколько запросов:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Успех! Теперь у нас есть пул потоков, который асинхронно выполняет соединения. Никогда не создаётся более четырёх потоков, поэтому наша система не будет перегружена, если сервер получит много запросов. Если мы сделаем запрос к /sleep, сервер сможет обслуживать другие запросы, поручив их выполнение другому потоку.
Примечание: Если вы откроете /sleep в нескольких окнах браузера одновременно, они могут загружаться по одному с интервалом в пять секунд. Некоторые веб-браузеры выполняют несколько экземпляров одного и того же запроса последовательно по причинам кэширования. Это ограничение не вызвано нашим веб-сервером.
Это хорошее время, чтобы остановиться и подумать, как код в Листингах 21-18, 21-19 и 21-20 отличался бы, если бы мы использовали future'ы вместо замыкания для выполняемой работы. Какие типы изменились бы? Как изменились бы сигнатуры методов, если вообще изменились? Какие части кода остались бы прежними?
После изучения цикла while let в Главе 17 и Главе 19 вам может быть интересно, почему мы не написали код потока Worker так, как показано в Листинге 21-21.
Файл: src/lib.rs
#![allow(unused)] fn main() { [Этот код не производит желаемого поведения.] // --пропуск-- impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { while let Ok(job) = receiver.lock().unwrap().recv() { println!("Worker {id} got a job; executing."); job(); } }); Worker { id, thread } } } }
Листинг 21-21: Альтернативная реализация Worker::new с использованием while let
Этот код компилируется и запускается, но не приводит к желаемому поведению потоков: медленный запрос всё равно будет заставлять другие запросы ждать обработки. Причина несколько тонкая: структура Mutex не имеет публичного метода unlock, потому что владение блокировкой основано на времени жизни MutexGuard<T> внутри LockResult<MutexGuard<T>>, который возвращает метод lock. Во время компиляции заимствователь может затем обеспечить правило, что ресурс, защищённый Mutex, не может быть доступен, если мы не держим блокировку. Однако эта реализация также может привести к тому, что блокировка удерживается дольше, чем предполагалось, если мы не mindful о времени жизни MutexGuard<T>.
Код в Листинге 21-20, который использует let job = receiver.lock().unwrap().recv().unwrap();, работает, потому что с let любые временные значения, используемые в выражении справа от знака равенства, немедленно уничтожаются, когда оператор let заканчивается. Однако while let (и if let, и match) не уничтожает временные значения до конца связанного блока. В Листинге 21-21 блокировка остаётся удержанной на время вызова job(), что означает, что другие экземпляры Worker не могут получать задания.
Завершение и очистка
Код в Листинге 21-20 отвечает на запросы асинхронно с использованием пула потоков, как мы и планировали. Мы получаем некоторые предупреждения о полях workers, id и thread, которые мы не используем напрямую, что напоминает нам, что мы ничего не очищаем. Когда мы используем менее элегантный метод Ctrl-C для остановки основного потока, все остальные потоки также немедленно останавливаются, даже если они находятся в процессе обслуживания запроса.
Далее мы реализуем трейт Drop для вызова join на каждом потоке в пуле, чтобы они могли завершить запросы, над которыми работают, перед закрытием. Затем мы реализуем способ сообщить потокам, что они должны прекратить принимать новые запросы и завершиться. Чтобы увидеть этот код в действии, мы изменим наш сервер так, чтобы он принимал только два запроса перед грациозным завершением работы своего пула потоков.
Одна вещь, которую стоит заметить: ничто из этого не влияет на части кода, которые обрабатывают выполнение замыканий, поэтому всё здесь было бы таким же, если бы мы использовали пул потоков для асинхронной среды выполнения.
Реализация трейта Drop для ThreadPool
Давайте начнём с реализации Drop для нашего пула потоков. Когда пул уничтожается, все наши потоки должны присоединиться (join), чтобы убедиться, что они завершают свою работу. Листинг 21-22 показывает первую попытку реализации Drop; этот код пока не будет работать.
Файл: src/lib.rs
#![allow(unused)] fn main() { [Этот код не компилируется!] impl Drop for ThreadPool { fn drop(&mut self) { for worker in &mut self.workers { println!("Shutting down worker {}", worker.id); worker.thread.join().unwrap(); } } } }
Листинг 21-22: Присоединение к каждому потоку при выходе пула потоков из области видимости
Сначала мы проходим в цикле по каждому работнику пула потоков. Мы используем &mut для этого, потому что self является изменяемой ссылкой, и нам также нужно иметь возможность изменять worker. Для каждого работника мы печатаем сообщение о том, что этот конкретный экземпляр Worker завершает работу, а затем вызываем join для потока этого экземпляра Worker. Если вызов join завершается неудачей, мы используем unwrap, чтобы Rust запаниковал и перешёл к неграциозному завершению.
Вот ошибка, которую мы получаем при компиляции этого кода:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/4eb161250e340c8f48f66e2b929ef4a5bed7c181/library/std/src/thread/mod.rs:1876:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
Ошибка сообщает нам, что мы не можем вызвать join, потому что у нас есть только изменяемое заимствование каждого работника, а join принимает владение своим аргументом. Чтобы решить эту проблему, нам нужно переместить поток из экземпляра Worker, который владеет thread, чтобы join мог потребить поток. Один из способов сделать это — использовать тот же подход, который мы использовали в Листинге 18-15. Если бы Worker содержал Option<thread::JoinHandle<()>>, мы могли бы вызвать метод take на Option, чтобы переместить значение из варианта Some и оставить вариант None на его месте. Другими словами, работающий Worker имел бы вариант Some в thread, а когда мы хотели бы очистить Worker, мы заменили бы Some на None, чтобы у Worker не было потока для выполнения.
Однако единственный раз, когда это потребовалось бы, — это при уничтожении Worker. В обмен нам пришлось бы иметь дело с Option<thread::JoinHandle<()>> везде, где мы обращаемся к worker.thread. В идиоматичном Rust Option используется довольно часто, но когда вы обнаруживаете, что оборачиваете что-то, что, как вы знаете, всегда будет присутствовать, в Option в качестве обходного пути, как в этом случае, стоит поискать альтернативные подходы, чтобы сделать ваш код чище и менее подверженным ошибкам.
В данном случае существует лучшая альтернатива: метод Vec::drain. Он принимает параметр диапазона, чтобы указать, какие элементы удалить из вектора, и возвращает итератор этих элементов. Передача синтаксиса диапазона .. удалит все значения из вектора.
Итак, нам нужно обновить реализацию drop для ThreadPool следующим образом:
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Drop for ThreadPool { fn drop(&mut self) { for worker in self.workers.drain(..) { println!("Shutting down worker {}", worker.id); worker.thread.join().unwrap(); } } } }
Это решает ошибку компилятора и не требует никаких других изменений в нашем коде. Обратите внимание, что поскольку drop может быть вызван при панике, unwrap также может вызвать панику и привести к двойной панике, что немедленно аварийно завершает программу и прерывает любую выполняющуюся очистку. Это приемлемо для примерной программы, но не рекомендуется для производственного кода.
Сигнализация потокам о прекращении прослушивания заданий
Со всеми внесёнными нами изменениями наш код компилируется без каких-либо предупреждений. Однако плохая новость заключается в том, что этот код пока не функционирует так, как мы хотим. Ключевым моментом является логика в замыканиях, выполняемых потоками экземпляров Worker: в настоящее время мы вызываем join, но это не завершит потоки, потому что они работают в бесконечном цикле, ищущем задания. Если мы попытаемся уничтожить наш ThreadPool с текущей реализацией drop, основной поток заблокируется навсегда, ожидая завершения первого потока.
Чтобы исправить эту проблему, нам нужно изменить реализацию drop для ThreadPool, а затем изменить цикл Worker.
Сначала мы изменим реализацию drop для ThreadPool, чтобы явно уничтожить sender перед ожиданием завершения потоков. Листинг 21-23 показывает изменения в ThreadPool для явного уничтожения sender. В отличие от thread, здесь нам действительно нужно использовать Option, чтобы иметь возможность переместить sender из ThreadPool с помощью Option::take.
Файл: src/lib.rs
#![allow(unused)] fn main() { [Этот код не производит желаемого поведения.] pub struct ThreadPool { workers: Vec<Worker>, sender: Option<mpsc::Sender<Job>>, } // --пропуск-- impl ThreadPool { pub fn new(size: usize) -> ThreadPool { // --пропуск-- ThreadPool { workers, sender: Some(sender), } } pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.sender.as_ref().unwrap().send(job).unwrap(); } } impl Drop for ThreadPool { fn drop(&mut self) { drop(self.sender.take()); for worker in self.workers.drain(..) { println!("Shutting down worker {}", worker.id); worker.thread.join().unwrap(); } } } }
Листинг 21-23: Явное уничтожение sender перед присоединением к потокам Worker
Уничтожение sender закрывает канал, что указывает на то, что больше сообщений отправляться не будет. Когда это происходит, все вызовы recv, которые экземпляры Worker делают в бесконечном цикле, будут возвращать ошибку. В Листинге 21-24 мы изменяем цикл Worker для грациозного выхода из цикла в этом случае, что означает, что потоки завершатся, когда реализация drop для ThreadPool вызовет join для них.
Файл: src/lib.rs
#![allow(unused)] fn main() { impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let message = receiver.lock().unwrap().recv(); match message { Ok(job) => { println!("Worker {id} got a job; executing."); job(); } Err(_) => { println!("Worker {id} disconnected; shutting down."); break; } } } }); Worker { id, thread } } } }
Листинг 21-24: Явный выход из цикла при возврате ошибки recv
Чтобы увидеть этот код в действии, давайте изменим main для принятия только двух запросов перед грациозным завершением работы сервера, как показано в Листинге 21-25.
Файл: src/main.rs
fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); let pool = ThreadPool::new(4); for stream in listener.incoming().take(2) { let stream = stream.unwrap(); pool.execute(|| { handle_connection(stream); }); } println!("Shutting down."); }
Листинг 21-25: Завершение работы сервера после обслуживания двух запросов путём выхода из цикла
Вы не хотели бы, чтобы реальный веб-сервер завершал работу после обслуживания всего двух запросов. Этот код просто демонстрирует, что грациозное завершение работы и очистка функционируют правильно.
Метод take определён в трейте Iterator и ограничивает итерацию максимум первыми двумя элементами. ThreadPool выйдет из области видимости в конце main, и реализация drop будет выполнена.
Запустите сервер с помощью cargo run и сделайте три запроса. Третий запрос должен завершиться ошибкой, и в вашем терминале вы должны увидеть вывод, похожий на этот:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
Вы можете увидеть другой порядок идентификаторов Worker и напечатанных сообщений. Мы можем увидеть, как работает этот код, из сообщений: экземпляры Worker 0 и 3 получили первые два запроса. Сервер перестал принимать соединения после второго соединения, и реализация Drop для ThreadPool начала выполняться до того, как Worker 3 даже начал свою работу. Уничтожение sender отключает все экземпляры Worker и сообщает им о необходимости завершить работу. Экземпляры Worker каждый печатают сообщение при отключении, а затем пул потоков вызывает join для ожидания завершения каждого потока Worker.
Обратите внимание на один интересный аспект этого конкретного выполнения: ThreadPool уничтожил sender, и до того, как какой-либо Worker получил ошибку, мы попытались присоединиться к Worker 0. Worker 0 ещё не получил ошибку от recv, поэтому основной поток заблокировался, ожидая завершения Worker 0. Тем временем Worker 3 получил задание, а затем все потоки получили ошибку. Когда Worker 0 завершился, основной поток ждал завершения остальных экземпляров Worker. В тот момент они все вышли из своих циклов и остановились.
Поздравляем! Мы завершили наш проект; у нас есть базовый веб-сервер, который использует пул потоков для асинхронного ответа. Мы можем выполнить грациозное завершение работы сервера, которое очищает все потоки в пуле.
Вот полный код для справки:
Файл: src/main.rs
use hello::ThreadPool; use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); let pool = ThreadPool::new(4); for stream in listener.incoming().take(2) { let stream = stream.unwrap(); pool.execute(|| { handle_connection(stream); }); } println!("Shutting down."); } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Файл: src/lib.rs
#![allow(unused)] fn main() { use std::{ sync::{Arc, Mutex, mpsc}, thread, }; pub struct ThreadPool { workers: Vec<Worker>, sender: Option<mpsc::Sender<Job>>, } type Job = Box<dyn FnOnce() + Send + 'static>; impl ThreadPool { /// Создаёт новый ThreadPool. /// /// Параметр size - количество потоков в пуле. /// /// # Паника /// /// Функция `new` будет паниковать, если size равен нулю. pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let receiver = Arc::new(Mutex::new(receiver)); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id, Arc::clone(&receiver))); } ThreadPool { workers, sender: Some(sender), } } pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.sender.as_ref().unwrap().send(job).unwrap(); } } impl Drop for ThreadPool { fn drop(&mut self) { drop(self.sender.take()); for worker in &mut self.workers { println!("Shutting down worker {}", worker.id); if let Some(thread) = worker.thread.take() { thread.join().unwrap(); } } } } struct Worker { id: usize, thread: Option<thread::JoinHandle<()>>, } impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let message = receiver.lock().unwrap().recv(); match message { Ok(job) => { println!("Worker {id} got a job; executing."); job(); } Err(_) => { println!("Worker {id} disconnected; shutting down."); break; } } } }); Worker { id, thread: Some(thread), } } } }
Мы могли бы сделать больше! Если вы хотите продолжить улучшение этого проекта, вот несколько идей:
- Добавьте больше документации к
ThreadPoolи его публичным методам - Добавьте тесты функциональности библиотеки
- Замените вызовы
unwrapна более надёжную обработку ошибок - Используйте
ThreadPoolдля выполнения некоторых задач, отличных от обслуживания веб-запросов - Найдите крейт пула потоков на crates.io и реализуйте аналогичный веб-сервер с использованием этого крейта. Затем сравните его API и надёжность с реализованным нами пулом потоков
Итог
Отлично сработано! Вы дошли до конца книги! Мы хотим поблагодарить вас за то, что присоединились к нам в этом туре по Rust. Теперь вы готовы реализовывать свои собственные проекты на Rust и помогать с проектами других людей. Помните, что существует welcoming сообщество других Rustaceans, которые будут рады помочь вам с любыми трудностями, с которыми вы столкнётесь на вашем пути в Rust.
Приложения
Приложение A: Ключевые слова
Следующие списки содержат ключевые слова, зарезервированные для текущего или будущего использования языком Rust. Как таковые, они не могут использоваться в качестве идентификаторов (за исключением сырых идентификаторов, как мы обсуждаем в разделе "Сырые идентификаторы"). Идентификаторы — это имена функций, переменных, параметров, полей структур, модулей, крейтов, констант, макросов, статических значений, атрибутов, типов, трейтов или времён жизни.
Ключевые слова, используемые в настоящее время
Ниже приведён список ключевых слов, используемых в настоящее время, с описанием их функциональности.
as: Выполняет примитивное приведение типов, устраняет неоднозначность конкретного трейта, содержащего элемент, или переименовывает элементы в операторахuse.async: ВозвращаетFutureвместо блокировки текущего потока.await: Приостанавливает выполнение до тех пор, пока результатFutureне будет готов.break: Немедленно выходит из цикла.const: Определяет константные элементы или константные сырые указатели.continue: Переходит к следующей итерации цикла.crate: В пути модуля ссылается на корень крейта.dyn: Динамическая диспетчеризация для трейт-объекта.else: Запасной вариант для конструкций управления потокомifиif let.enum: Определяет перечисление.extern: Связывает внешнюю функцию или переменную.false: Логический литерал "ложь".fn: Определяет функцию или тип указателя на функцию.for: Цикл по элементам из итератора, реализация трейта или указание времени жизни высшего ранга.if: Ветвление на основе результата условного выражения.impl: Реализует собственную или трейтовую функциональность.in: Часть синтаксиса циклаfor.let: Связывает переменную.loop: Безусловный цикл.match: Сопоставляет значение с образцами.mod: Определяет модуль.move: Заставляет замыкание завладеть всеми захваченными значениями.mut: Обозначает изменяемость в ссылках, сырых указателях или привязках образцов.pub: Обозначает публичную видимость в полях структур, блокахimplили модулях.ref: Связывает по ссылке.return: Возвращает из функции.Self: Псевдоним типа для типа, который мы определяем или реализуем.self: Объект метода или текущий модуль.static: Глобальная переменная или время жизни, длящееся в течение всего выполнения программы.struct: Определяет структуру.super: Родительский модуль текущего модуля.trait: Определяет трейт.true: Логический литерал "истина".type: Определяет псевдоним типа или ассоциированный тип.union: Определяет объединение; является ключевым словом только при использовании в объявлении union.unsafe: Обозначает небезопасный код, функции, трейты или реализации.use: Вносит символы в область видимости.where: Обозначает условия, ограничивающие тип.while: Цикл, основанный на результате выражения.
Ключевые слова, зарезервированные для будущего использования
Следующие ключевые слова пока не имеют никакой функциональности, но зарезервированы Rust для потенциального использования в будущем:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Сырые идентификаторы
Сырые идентификаторы — это синтаксис, который позволяет использовать ключевые слова там, где они обычно не разрешены. Вы используете сырой идентификатор, добавляя префикс r# к ключевому слову.
Например, match — это ключевое слово. Если вы попытаетесь скомпилировать следующую функцию, которая использует match в качестве своего имени:
Файл: src/main.rs
#![allow(unused)] fn main() { [Этот код не компилируется!] fn match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } }
вы получите эту ошибку:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Ошибка показывает, что вы не можете использовать ключевое слово match в качестве идентификатора функции. Чтобы использовать match в качестве имени функции, вам нужно использовать синтаксис сырого идентификатора, например:
Файл: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
Этот код скомпилируется без ошибок. Обратите внимание на префикс r# в имени функции как в её определении, так и там, где функция вызывается в main.
Сырые идентификаторы позволяют использовать любое выбранное вами слово в качестве идентификатора, даже если это слово является зарезервированным ключевым словом. Это даёт нам больше свободы в выборе имён идентификаторов, а также позволяет интегрироваться с программами, написанными на языке, где эти слова не являются ключевыми. Кроме того, сырые идентификаторы позволяют использовать библиотеки, написанные в другом издании Rust, отличном от того, которое использует ваш крейт. Например, try не является ключевым словом в издании 2015 года, но является таковым в изданиях 2018, 2021 и 2024 годов. Если вы зависите от библиотеки, написанной с использованием издания 2015 года и имеющей функцию try, вам нужно будет использовать синтаксис сырого идентификатора, в данном случае r#try, чтобы вызвать эту функцию из вашего кода в более поздних изданиях. См. Приложение E для получения дополнительной информации об изданиях.
Приложение B: Операторы и символы
Это приложение содержит глоссарий синтаксиса Rust, включая операторы и другие символы, которые появляются самостоятельно или в контексте путей, обобщённых типов, ограничений трейтов, макросов, атрибутов, комментариев, кортежей и скобок.
Операторы
Таблица B-1 содержит операторы в Rust, пример использования оператора в контексте, краткое объяснение и информацию о том, можно ли перегрузить этот оператор. Если оператор можно перегрузить, указан соответствующий трейт для перегрузки.
Таблица B-1: Операторы
| Оператор | Пример | Объяснение | Перегружаемо? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Раскрытие макроса | |
! | !expr | Побитовое или логическое дополнение | Not |
!= | expr != expr | Сравнение на неравенство | PartialEq |
% | expr % expr | Арифметический остаток от деления | Rem |
%= | var %= expr | Арифметический остаток и присваивание | RemAssign |
& | &expr, &mut expr | Заимствование | |
& | &type, &mut type, &'a type, &'a mut type | Тип заимствованного указателя | |
& | expr & expr | Побитовое И | BitAnd |
&= | var &= expr | Побитовое И и присваивание | BitAndAssign |
&& | expr && expr | Условное логическое И | |
* | expr * expr | Арифметическое умножение | Mul |
*= | var *= expr | Арифметическое умножение и присваивание | MulAssign |
* | *expr | Разыменование | Deref |
* | *const type, *mut type | Сырой указатель | |
+ | trait + trait, 'a + trait | Составное ограничение типа | |
+ | expr + expr | Арифметическое сложение | Add |
+= | var += expr | Арифметическое сложение и присваивание | AddAssign |
, | expr, expr | Разделитель аргументов и элементов | |
- | - expr | Арифметическое отрицание | Neg |
- | expr - expr | Арифметическое вычитание | Sub |
-= | var -= expr | Арифметическое вычитание и присваивание | SubAssign |
-> | fn(...) -> type, |…| -> type | Тип возвращаемого значения функции и замыкания | |
. | expr.ident | Доступ к полю | |
. | expr.ident(expr, ...) | Вызов метода | |
. | expr.0, expr.1 и т.д. | Индексация кортежа | |
.. | .., expr.., ..expr, expr..expr | Литерал диапазона с исключением правой границы | PartialOrd |
..= | ..=expr, expr..=expr | Литерал диапазона с включением правой границы | PartialOrd |
.. | ..expr | Синтаксис обновления литерала структуры | |
.. | variant(x, ..), struct_type { x, .. } | Привязка образца "и остальное" | |
... | expr...expr | (Устарело, используйте ..=) В образце: включающий диапазон | |
/ | expr / expr | Арифметическое деление | Div |
/= | var /= expr | Арифметическое деление и присваивание | DivAssign |
: | pat: type, ident: type | Ограничения | |
: | ident: expr | Инициализатор поля структуры | |
: | 'a: loop {...} | Метка цикла | |
; | expr; | Завершающий символ выражения и элемента | |
; | [...; len] | Часть синтаксиса массива фиксированного размера | |
<< | expr << expr | Сдвиг влево | Shl |
<<= | var <<= expr | Сдвиг влево и присваивание | ShlAssign |
< | expr < expr | Сравнение "меньше" | PartialOrd |
<= | expr <= expr | Сравнение "меньше или равно" | PartialOrd |
= | var = expr, ident = type | Присваивание/эквивалентность | |
== | expr == expr | Сравнение на равенство | PartialEq |
=> | pat => expr | Часть синтаксиса ветки match | |
> | expr > expr | Сравнение "больше" | PartialOrd |
>= | expr >= expr | Сравнение "больше или равно" | PartialOrd |
>> | expr >> expr | Сдвиг вправо | Shr |
>>= | var >>= expr | Сдвиг вправо и присваивание | ShrAssign |
@ | ident @ pat | Привязка образца | |
^ | expr ^ expr | Побитовое исключающее ИЛИ | BitXor |
^= | var ^= expr | Побитовое исключающее ИЛИ и присваивание | BitXorAssign |
| | pat | pat | Альтернативы образцов | |
| | expr | expr | Побитовое ИЛИ | BitOr |
|= | var |= expr | Побитовое ИЛИ и присваивание | BitOrAssign |
|| | expr || expr | Условное логическое ИЛИ | |
? | expr? | Распространение ошибки |
Неоператорные символы
Следующие таблицы содержат все символы, которые не функционируют как операторы; то есть они не ведут себя как вызов функции или метода.
Таблица B-2 показывает символы, которые появляются самостоятельно и допустимы в различных местах.
Таблица B-2: Автономный синтаксис
| Символ | Объяснение |
|---|---|
'ident | Именованное время жизни или метка цикла |
Цифры, за которыми сразу следует u8, i32, f64, usize и т.д. | Числовой литерал конкретного типа |
"..." | Строковый литерал |
r"...", r#"..."#, r##"..."## и т.д. | Сырой строковый литерал; escape-символы не обрабатываются |
b"..." | Байтовый строковый литерал; создаёт массив байтов вместо строки |
br"...", br#"..."#, br##"..."## и т.д. | Сырой байтовый строковый литерал; комбинация сырого и байтового строкового литерала |
'...' | Символьный литерал |
b'...' | ASCII байтовый литерал |
|…| expr | Замыкание |
! | Всегда пустой нижний тип для расходящихся функций |
_ | "Игнорируемая" привязка образца; также используется для читаемости целочисленных литералов |
Таблица B-3 показывает символы, которые появляются в контексте пути через иерархию модулей к элементу.
Таблица B-3: Синтаксис, связанный с путями
| Символ | Объяснение |
|---|---|
ident::ident | Пространство имён пути |
::path | Путь относительно корня крейта (то есть явно абсолютный путь) |
self::path | Путь относительно текущего модуля (то есть явно относительный путь) |
super::path | Путь относительно родителя текущего модуля |
type::ident, <type as trait>::ident | Ассоциированные константы, функции и типы |
<type>::... | Ассоциированный элемент для типа, который нельзя напрямую назвать (например, <&T>::..., <[T]>::... и т.д.) |
trait::method(...) | Устранение неоднозначности вызова метода путём именования трейта, который его определяет |
type::method(...) | Устранение неоднозначности вызова метода путём именования типа, для которого он определён |
<type as trait>::method(...) | Устранение неоднозначности вызова метода путём именования трейта и типа |
Таблица B-4 показывает символы, которые появляются в контексте использования параметров обобщённого типа.
Таблица B-4: Обобщённые типы
| Символ | Объяснение |
|---|---|
path<...> | Задаёт параметры для обобщённого типа в типе (например, Vec<u8>) |
path::<...>, method::<...> | Задаёт параметры для обобщённого типа, функции или метода в выражении; часто называется "турбо-рыбой" (например, "42".parse::<i32>()) |
fn ident<...> ... | Определение обобщённой функции |
struct ident<...> ... | Определение обобщённой структуры |
enum ident<...> ... | Определение обобщённого перечисления |
impl<...> ... | Определение обобщённой реализации |
for<...> type | Ограничения времени жизни высшего ранга |
type<ident=type> | Обобщённый тип, где один или более ассоциированных типов имеют конкретные назначения (например, Iterator<Item=T>) |
Таблица B-5 показывает символы, которые появляются в контексте ограничения параметров обобщённого типа с помощью ограничений трейтов.
Таблица B-5: Ограничения трейтов
| Символ | Объяснение |
|---|---|
T: U | Параметр T ограничен типами, которые реализуют U |
T: 'a | Обобщённый тип T должен переживать время жизни 'a (значит, тип не может транзитивно содержать ссылки с временем жизни короче 'a) |
T: 'static | Обобщённый тип T не содержит заимствованных ссылок, кроме 'static |
'b: 'a | Обобщённое время жизни 'b должно переживать время жизни 'a |
T: ?Sized | Разрешает параметру обобщённого типа быть типом динамического размера |
'a + trait, trait + trait | Составное ограничение типа |
Таблица B-6 показывает символы, которые появляются в контексте вызова или определения макросов и указания атрибутов на элементе.
Таблица B-6: Макросы и атрибуты
| Символ | Объяснение |
|---|---|
#[meta] | Внешний атрибут |
#![meta] | Внутренний атрибут |
$ident | Подстановка макроса |
$ident:kind | Метапеременная макроса |
$(...)... | Повторение макроса |
ident!(...), ident!{...}, ident![...] | Вызов макроса |
Таблица B-7 показывает символы, которые создают комментарии.
Таблица B-7: Комментарии
| Символ | Объяснение |
|---|---|
// | Строчный комментарий |
//! | Внутренний строчный док-комментарий |
/// | Внешний строчный док-комментарий |
/*...*/ | Блочный комментарий |
/*!...*/ | Внутренний блочный док-комментарий |
/**...*/ | Внешний блочный док-комментарий |
Таблица B-8 показывает контексты, в которых используются круглые скобки.
Таблица B-8: Круглые скобки
| Символ | Объяснение |
|---|---|
() | Пустой кортеж (он же unit), как литерал, так и тип |
(expr) | Выражение в круглых скобках |
(expr,) | Выражение одноэлементного кортежа |
(type,) | Тип одноэлементного кортежа |
(expr, ...) | Выражение кортежа |
(type, ...) | Тип кортежа |
expr(expr, ...) | Выражение вызова функции; также используется для инициализации кортежных структур и вариантов перечислений-кортежей |
Таблица B-9 показывает контексты, в которых используются фигурные скобки.
Таблица B-9: Фигурные скобки
| Контекст | Объяснение |
|---|---|
{...} | Блочное выражение |
Type {...} | Литерал структуры |
Таблица B-10 показывает контексты, в которых используются квадратные скобки.
Таблица B-10: Квадратные скобки
| Контекст | Объяснение |
|---|---|
[...] | Литерал массива |
[expr; len] | Литерал массива, содержащий len копий expr |
[type; len] | Тип массива, содержащий len экземпляров type |
expr[expr] | Индексация коллекции; перегружаемо (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Индексация коллекции, притворяющаяся срезом коллекции, с использованием Range, RangeFrom, RangeTo или RangeFull в качестве "индекса" |
Приложение C: Выводимые типажи (Derivable Traits)
В различных разделах книги мы обсуждали атрибут derive, который можно применять к определениям структур или перечислений. Атрибут derive генерирует код, который реализует типаж с его стандартной реализацией для типа, помеченного синтаксисом derive.
В этом приложении мы предоставляем справочник по всем типажам стандартной библиотеки, которые можно использовать с derive. Каждый раздел охватывает:
- Какие операторы и методы становятся доступными при выводе этого типажа
- Что делает реализация типажа, предоставляемая
derive - Что означает реализация типажа для типа
- Условия, при которых разрешена или запрещена реализация типажа
- Примеры операций, которые требуют наличия типажа
Если вам нужно поведение, отличное от предоставляемого атрибутом derive, обратитесь к документации стандартной библиотеки для каждого типажа за подробностями о том, как реализовать их вручную.
Перечисленные здесь типажи — это единственные типажи, определенные стандартной библиотекой, которые могут быть реализованы для ваших типов с помощью derive. Другие типажи, определенные в стандартной библиотеке, не имеют осмысленного поведения по умолчанию, поэтому вам решать, как их реализовать, в зависимости от ваших целей.
Пример типажа, который нельзя вывести — это Display, который обрабатывает форматирование для конечных пользователей. Вы всегда должны продумывать подходящий способ отображения типа для конечного пользователя. Какие части типа должен видеть конечный пользователь? Какие части будут для него релевантны? В каком формате данные будут наиболее полезны? Компилятор Rust не обладает таким пониманием, поэтому не может предоставить вам подходящее поведение по умолчанию.
Список выводимых типажей, приведенный в этом приложении, не является исчерпывающим: библиотеки могут реализовывать derive для своих собственных типажей, делая список типажей, которые можно использовать с derive, практически бесконечным. Реализация derive включает использование процедурных макросов, которые рассматриваются в разделе "Пользовательские процедурные макросы" в Главе 20.
Debug для вывода отладочной информации
Типаж Debug включает форматирование для отладки в строки формата, которое указывается добавлением :? внутри заполнителей {}.
Типаж Debug позволяет вам выводить экземпляры типа для целей отладки, чтобы вы и другие программисты, использующие ваш тип, могли исследовать экземпляр в определенной точке выполнения программы.
Типаж Debug требуется, например, при использовании макроса assert_eq!. Этот макрос выводит значения экземпляров, переданных в качестве аргументов, если проверка на равенство не выполняется, чтобы программисты могли увидеть, почему два экземпляра не равны.
PartialEq и Eq для сравнения на равенство
Типаж PartialEq позволяет сравнивать экземпляры типа для проверки на равенство и enables использование операторов == и !=.
Вывод PartialEq реализует метод eq. Когда PartialEq выводится для структур, два экземпляра равны, только если все поля равны, и экземпляры не равны, если любые поля не равны. При выводе для перечислений каждый вариант равен самому себе и не равен другим вариантам.
Типаж PartialEq требуется, например, при использовании макроса assert_eq!, которому необходимо иметь возможность сравнивать два экземпляра типа на равенство.
У типажа Eq нет методов. Его цель — сигнализировать, что для каждого значения аннотированного типа это значение равно самому себе. Типаж Eq можно применять только к типам, которые также реализуют PartialEq, хотя не все типы, реализующие PartialEq, могут реализовать Eq. Примером этого являются типы чисел с плавающей точкой: реализация для чисел с плавающей точкой указывает, что два экземпляра значения "не число" (NaN) не равны друг другу.
Пример, когда требуется Eq — это для ключей в HashMap<K, V>, чтобы HashMap<K, V> мог определить, являются ли два ключа одинаковыми.
PartialOrd и Ord для сравнения упорядочивания
Типаж PartialOrd позволяет сравнивать экземпляры типа для целей сортировки. Тип, реализующий PartialOrd, может использоваться с операторами <, >, <= и >=. Вы можете применять типаж PartialOrd только к типам, которые также реализуют PartialEq.
Вывод PartialOrd реализует метод partial_cmp, который возвращает Option<Ordering>, который будет None, когда заданные значения не позволяют определить порядок. Пример значения, для которого нельзя определить порядок, даже если большинство значений этого типа можно сравнивать, — это значение NaN с плавающей точкой. Вызов partial_cmp для любого числа с плавающей точкой и значения NaN вернет None.
При выводе для структур PartialOrd сравнивает два экземпляра, сравнивая значения в каждом поле в том порядке, в котором поля появляются в определении структуры. При выводе для перечислений варианты перечисления, объявленные раньше в определении перечисления, считаются меньше, чем варианты, перечисленные позже.
Типаж PartialOrd требуется, например, для метода gen_range из крейта rand, который генерирует случайное значение в диапазоне, указанном выражением диапазона.
Типаж Ord позволяет вам знать, что для любых двух значений аннотированного типа всегда будет существовать допустимый порядок. Типаж Ord реализует метод cmp, который возвращает Ordering, а не Option<Ordering>, потому что допустимый порядок всегда возможен. Вы можете применять типаж Ord только к типам, которые также реализуют PartialOrd и Eq (а Eq требует PartialEq). При выводе для структур и перечислений cmp ведет себя так же, как производная реализация partial_cmp для PartialOrd.
Пример, когда требуется Ord — это при хранении значений в BTreeSet<T>, структуре данных, которая хранит данные на основе порядка сортировки значений.
Clone и Copy для дублирования значений
Типаж Clone позволяет вам явно создавать глубокую копию значения, и процесс дублирования может включать выполнение произвольного кода и копирование данных в куче. См. раздел "Взаимодействие переменных и данных с помощью Clone" в Главе 4 для получения дополнительной информации о Clone.
Вывод Clone реализует метод clone, который при реализации для всего типа вызывает clone для каждой из частей типа. Это означает, что все поля или значения в типе также должны реализовывать Clone, чтобы можно было вывести Clone.
Пример, когда требуется Clone — это при вызове метода to_vec для среза. Срез не владеет экземплярами типов, которые он содержит, но вектор, возвращаемый из to_vec, должен будет владеть своими экземплярами, поэтому to_vec вызывает clone для каждого элемента. Таким образом, тип, хранящийся в срезе, должен реализовывать Clone.
Типаж Copy позволяет вам дублировать значение, просто копируя биты, хранящиеся в стеке; не требуется выполнения произвольного кода. См. раздел "Данные только в стеке: Copy" в Главе 4 для получения дополнительной информации о Copy.
Типаж Copy не определяет никаких методов, чтобы предотвратить перегрузку этих методов программистами и нарушение предположения, что не выполняется произвольный код. Таким образом, все программисты могут предполагать, что копирование значения будет очень быстрым.
Вы можете вывести Copy для любого типа, все части которого реализуют Copy. Тип, реализующий Copy, также должен реализовывать Clone, потому что для типа, реализующего Copy, существует тривиальная реализация Clone, которая выполняет ту же задачу, что и Copy.
Типаж Copy требуется редко; для типов, реализующих Copy, доступны оптимизации, означающие, что вам не нужно вызывать clone, что делает код более кратким.
Все, что можно сделать с Copy, также можно достичь с помощью Clone, но код может быть медленнее или ему придется использовать clone в некоторых местах.
Hash для отображения значения в значение фиксированного размера
Типаж Hash позволяет вам взять экземпляр типа произвольного размера и отобразить этот экземпляр в значение фиксированного размера с использованием хеш-функции. Вывод Hash реализует метод hash. Производная реализация метода hash объединяет результат вызова hash для каждой из частей типа, что означает, что все поля или значения также должны реализовывать Hash, чтобы можно было вывести Hash.
Пример, когда требуется Hash — это при хранении ключей в HashMap<K, V> для эффективного хранения данных.
Default для значений по умолчанию
Типаж Default позволяет вам создать значение по умолчанию для типа. Вывод Default реализует функцию default. Производная реализация функции default вызывает функцию default для каждой части типа, что означает, что все поля или значения в типе также должны реализовывать Default, чтобы можно было вывести Default.
Функция Default::default обычно используется в комбинации с синтаксисом обновления структур, обсуждаемым в разделе "Создание экземпляров из других экземпляров с помощью синтаксиса обновления структур" в Главе 5. Вы можете настроить несколько полей структуры, а затем установить и использовать значение по умолчанию для остальных полей, используя ..Default::default().
Типаж Default требуется, когда вы используете метод unwrap_or_default для экземпляров Option<T>, например. Если Option<T> является None, метод unwrap_or_default вернет результат Default::default() для типа T, хранящегося в Option<T>.
Приложение D: Полезные инструменты для разработки
В этом приложении мы рассмотрим некоторые полезные инструменты для разработки, предоставляемые проектом Rust. Мы изучим автоматическое форматирование, быстрые способы применения исправлений предупреждений, линтер и интеграцию с IDE.
Автоматическое форматирование с помощью rustfmt
Инструмент rustfmt переформатирует ваш код в соответствии с общепринятым стилем сообщества. Многие совместные проекты используют rustfmt, чтобы предотвратить споры о том, какой стиль использовать при написании кода на Rust: каждый форматирует свой код с помощью этого инструмента.
Установки Rust включают rustfmt по умолчанию, поэтому у вас уже должны быть программы rustfmt и cargo-fmt в вашей системе. Эти две команды аналогичны rustc и cargo в том смысле, что rustfmt позволяет более детальный контроль, а cargo-fmt понимает соглашения проектов, использующих Cargo. Чтобы отформатировать любой проект Cargo, введите следующее:
$ cargo fmt
Запуск этой команды переформатирует весь Rust-код в текущем крейте. Это должно изменить только стиль кода, а не его семантику. Для получения дополнительной информации о rustfmt см. его документацию.
Исправление кода с помощью rustfix
Инструмент rustfix входит в состав установки Rust и может автоматически исправлять предупреждения компилятора, для которых существует четкий способ решения проблемы, вероятно соответствующий вашим ожиданиям. Вы, вероятно, уже видели предупреждения компилятора. Например, рассмотрим этот код:
Файл: src/main.rs
fn main() { let mut x = 42; println!("{x}"); }
Здесь мы определяем переменную x как изменяемую, но никогда фактически не изменяем ее. Rust предупреждает нас об этом:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
Предупреждение предлагает нам удалить ключевое слово mut. Мы можем автоматически применить это предложение с помощью инструмента rustfix, выполнив команду cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Когда мы снова посмотрим на src/main.rs, мы увидим, что cargo fix изменил код:
Файл: src/main.rs
fn main() { let x = 42; println!("{x}"); }
Переменная x теперь неизменяема, и предупреждение больше не появляется.
Вы также можете использовать команду cargo fix для перевода вашего кода между различными редакциями Rust. Редакции рассматриваются в Приложении E.
Дополнительные проверки с Clippy
Инструмент Clippy — это набор линт (проверок) для анализа вашего кода, чтобы вы могли находить распространенные ошибки и улучшать свой Rust-код. Clippy входит в стандартную установку Rust.
Чтобы запустить проверки Clippy на любом проекте Cargo, введите следующее:
$ cargo clippy
Например, предположим, вы написали программу, которая использует приближение математической константы, такой как π (пи), как в этой программе:
Файл: src/main.rs
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Запуск cargo clippy для этого проекта приводит к такой ошибке:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Эта ошибка сообщает вам, что в Rust уже определена более точная константа PI, и ваша программа была бы более корректной, если бы вы использовали эту константу. Затем вы должны изменить свой код для использования константы PI.
Следующий код не вызывает ошибок или предупреждений от Clippy:
Файл: src/main.rs
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Для получения дополнительной информации о Clippy см. его документацию.
Интеграция с IDE с помощью rust-analyzer
Для помощи в интеграции с IDE сообщество Rust рекомендует использовать rust-analyzer. Этот инструмент представляет собой набор утилит, ориентированных на компилятор, которые используют Language Server Protocol — спецификацию для взаимодействия IDE и языков программирования друг с другом. Различные клиенты могут использовать rust-analyzer, такие как плагин Rust analyzer для Visual Studio Code.
Посетите домашнюю страницу проекта rust-analyzer для получения инструкций по установке, затем установите поддержку language server в вашей конкретной IDE. Ваша IDE получит такие возможности, как автодополнение, переход к определению и встроенные ошибки.
Приложение E: Редакции (Editions)
В Главе 1 вы видели, что cargo new добавляет немного метаданных в ваш файл Cargo.toml о редакции. Это приложение рассказывает, что это значит!
Язык Rust и компилятор имеют шестинедельный цикл выпуска версий, что означает, что пользователи получают постоянный поток новых функций. Другие языки программирования выпускают более крупные изменения реже; Rust выпускает небольшие обновления чаще. Со временем все эти мелкие изменения накапливаются. Но от выпуска к выпуску может быть трудно оглянуться назад и сказать: «Вау, между Rust 1.10 и Rust 1.31 Rust сильно изменился!»
Примерно раз в три года команда Rust выпускает новую редакцию языка. Каждая редакция объединяет реализованные функции в четкий пакет с полностью обновленной документацией и инструментами. Новые редакции выпускаются как часть обычного шестинедельного процесса выпуска версий.
Редакции служат разным целям для разных людей:
- Для активных пользователей Rust новая редакция объединяет постепенные изменения в удобный для понимания пакет.
- Для тех, кто не использует Rust, новая редакция сигнализирует о том, что произошли некоторые значительные улучшения, которые могут сделать Rust достойным еще одного взгляда.
- Для разработчиков Rust новая редакция предоставляет точку концентрации усилий для проекта в целом.
На момент написания этой книги доступны четыре редакции Rust: Rust 2015, Rust 2018, Rust 2021 и Rust 2024. Эта книга написана с использованием идиом редакции Rust 2024.
Ключ edition в Cargo.toml указывает, какую редакцию компилятор должен использовать для вашего кода. Если ключ не существует, Rust по соображениям обратной совместимости использует значение редакции 2015.
Каждый проект может выбрать редакцию, отличную от редакции по умолчанию 2015. Редакции могут содержать обратно несовместимые изменения, такие как добавление нового ключевого слова, которое конфликтует с идентификаторами в коде. Однако, если вы не согласитесь на эти изменения, ваш код будет продолжать компилироваться даже при обновлении версии компилятора Rust.
Все версии компилятора Rust поддерживают любую редакцию, существовавшую до выпуска этого компилятора, и они могут связывать крейты любых поддерживаемых редакций вместе. Изменения редакции влияют только на то, как компилятор изначально анализирует код. Следовательно, если вы используете Rust 2015, а одна из ваших зависимостей использует Rust 2018, ваш проект будет компилироваться и сможет использовать эту зависимость. Противоположная ситуация, когда ваш проект использует Rust 2018, а зависимость использует Rust 2015, также работает.
Чтобы было понятно: большинство функций будут доступны во всех редакциях. Разработчики, использующие любую редакцию Rust, будут продолжать видеть улучшения по мере выхода новых стабильных версий. Однако в некоторых случаях, в основном когда добавляются новые ключевые слова, некоторые новые функции могут быть доступны только в более поздних редакциях. Вам нужно будет переключить редакцию, если вы хотите воспользоваться такими функциями.
Для получения более подробной информации см. The Rust Edition Guide. Это полная книга, в которой перечислены различия между редакциями и объясняется, как автоматически обновить ваш код до новой редакции с помощью cargo fix.
Установка и обновление RUST
Установка RUST
- Запустить установщик
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
- Добавить в переменную пути
export PATH = $PATH:$HOME/.cargo/bin
- Проверить версию
rustc --version
Обновление RUST
rustup update
Удаление RUST
rustup self uninstall
Установка из исходного кода
git clone https://github.com/rust-lang/rustup.git
Установка последней ночной сборки
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --default-toolchain none -y
Сводная таблица основных команд rustup:
Команды Rustup
| Команда | Пример | Краткое описание |
|---|---|---|
install | rustup install stable | Установка конкретного выпуска Rust |
update | rustup update | Обновление rustup и установленных инструментов |
default | rustup default nightly | Установка выпуска по умолчанию |
toolchain | rustup toolchain list | Управление инструментальными цепочками |
target | rustup target add wasm32-unknown-unknown | Добавление целевой платформы для кросскомпиляции |
component | rustup component add rustfmt | Добавление компонентов (clippy, rustfmt и др.) |
override | rustup override set stable | Установка версии Rust для текущей директории |
which | rustup which rustc | Показывает путь к исполняемому файлу инструмента |
show | rustup show | Показывает активные и установленные инструментальные цепочки |
self | rustup self update | Обновление самого rustup |
uninstall | rustup uninstall nightly | Удаление инструментальной цепочки |
doc | rustup doc | Открывает локальную документацию Rust |
run | rustup run nightly cargo --version | Запускает команду с указанной инструментальной цепочкой |
set | rustup set profile minimal | Настройка профиля установки |
telemetry | rustup telemetry enable | Управление телеметрией |
completions | rustup completions bash | Генерация автодополнения для оболочки |
Основные инструментальные цепочки:
stable- стабильный выпускbeta- бета-выпускnightly- ночная сборка1.70.0- конкретная версия
Cargo
Профили релизов
профили выпуска — это предопределённые и настраиваемые профили с различными конфигурациями, которые позволяют программисту лучше контролировать различные параметры компиляции кода. Каждый профиль настраивается независимо от других.
Cargo имеет два основных профиля: профиль
dev, используемый Cargo при запускеcargo build, и профильrelease, используемый Cargo при запускеcargo build --release.
Файл: Cargo.toml
Настройка количества оптимизаций opt-level
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
cargo --list ✔
Installed Commands:
add Add dependencies to a Cargo.toml manifest file
audit
b alias: build
bench Execute all benchmarks of a local package
build Compile a local package and all of its dependencies
c alias: check
check Check a local package and all of its dependencies for errors
clean Remove artifacts that cargo has generated in the past
clippy Checks a package to catch common mistakes and improve your Rust code.
config Inspect configuration values
d alias: doc
doc Build a package's documentation
fetch Fetch dependencies of a package from the network
fix Automatically fix lint warnings reported by rustc
fmt Formats all bin and lib files of the current crate using rustfmt.
generate-lockfile Generate the lockfile for a package
git-checkout REMOVED: This command has been removed
help Displays help for a cargo subcommand
info Display information about a package
init Create a new cargo package in an existing directory
install Install a Rust binary
locate-project Print a JSON representation of a Cargo.toml file's location
login Log in to a registry.
logout Remove an API token from the registry locally
metadata Output the resolved dependencies of a package, the concrete used versions including overrides, in machine-readable format
miri
new Create a new cargo package at <path>
outdated
owner Manage the owners of a crate on the registry
package Assemble the local package into a distributable tarball
pkgid Print a fully qualified package specification
publish Upload a package to the registry
r alias: run
read-manifest DEPRECATED: Print a JSON representation of a Cargo.toml manifest.
remove Remove dependencies from a Cargo.toml manifest file
report Generate and display various kinds of reports
rm alias: remove
run Run a binary or example of the local package
rustc Compile a package, and pass extra options to the compiler
rustdoc Build a package's documentation, using specified custom flags.
search Search packages in the registry. Default registry is crates.io
t alias: test
test Execute all unit and integration tests and build examples of a local package
tree Display a tree visualization of a dependency graph
uninstall Remove a Rust binary
update Update dependencies as recorded in the local lock file
vendor Vendor all dependencies for a project locally
verify-project DEPRECATED: Check correctness of crate manifest.
version Show version information
yank Remove a pushed crate from the index
cargo --help ✔
Rust's package manager
Usage: cargo [+toolchain] [OPTIONS] [COMMAND]
cargo [+toolchain] [OPTIONS] -Zscript <MANIFEST_RS> [ARGS]...
Options:
-V, --version Print version info and exit
--list List installed commands
--explain <CODE> Provide a detailed explanation of a rustc error message
-v, --verbose... Use verbose output (-vv very verbose/build.rs output)
-q, --quiet Do not print cargo log messages
--color <WHEN> Coloring [possible values: auto, always, never]
-C <DIRECTORY> Change to DIRECTORY before doing anything (nightly-only)
--locked Assert that `Cargo.lock` will remain unchanged
--offline Run without accessing the network
--frozen Equivalent to specifying both --locked and --offline
--config <KEY=VALUE|PATH> Override a configuration value
-Z <FLAG> Unstable (nightly-only) flags to Cargo, see 'cargo -Z help' for details
-h, --help Print help
Commands:
build, b Compile the current package
check, c Analyze the current package and report errors, but don't build object files
clean Remove the target directory
doc, d Build this package's and its dependencies' documentation
new Create a new cargo package
init Create a new cargo package in an existing directory
add Add dependencies to a manifest file
remove Remove dependencies from a manifest file
run, r Run a binary or example of the local package
test, t Run the tests
bench Run the benchmarks
update Update dependencies listed in Cargo.lock
search Search registry for crates
publish Package and upload this package to the registry
install Install a Rust binary
uninstall Uninstall a Rust binary
... See all commands with --list
See 'cargo help <command>' for more information on a specific command.
Публикация библиотеки в Crates.io
Реестр библиотек по адресу crates.io распространяет исходный код ваших пакетов, поэтому он в основном размещает код с открытым исходным кодом.
- Комментарии к документации используют три слеша, /// вместо двух и поддерживают нотацию Markdown для форматирования текста.
- Размещайте комментарии к документации непосредственно перед элементом, который они документируют.
cargo doc --open— откроет документацию в браузереcargo test— запустит примеры как тесты- //! добавит комментарии ко всему документу указать в начале файла
Использование подмодулей
Для удобного документирования в главном модуле используем реэкспорт
#![allow(unused)] fn main() { //! # Art //! //! A library for modeling artistic concepts. pub use self::kinds::PrimaryColor; pub use self::kinds::SecondaryColor; pub use self::utils::mix; pub mod kinds { // --snip-- } pub mod utils { // --snip-- } }
регистрация на Crate.io
- регистрация по GitHub
- Получение токен
cargo login abcdefghijklmnopqrstuvwxyz012345логин и сохранение токен
Публикация crate
- Подобрать уникальное имя crate в файле
crate.toml
[package]
name = "guessing_game"
cargo publish— опубликовать- Перед публикацией вид файла
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
Вычеркивание версии cargo yank
Рабочее пространство
Workspace - это набор пакетов, которые используют один и тот же Cargo.lock и директорию для хранения результатов компиляции.
- Ручками создать главный
Cargo.toml - Прописать в нем пути к бинарному крейту и библиотечным крейтам
[workspace]
resolver = "3"
members = ["adder", "add_one"]
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
- Во внутренних крейтах прописать зависимости к библиотекам Workspace
[dependencies]
add_one = { path = "../add_one" }
- Использование функций в коде
fn main() { let num = 10; println!("Hello, world! {num} plus one is {}!", add_one::add_one(num)); }
Установка бинарников с crate.io
cargo install ripgrep
Толкование понятий в RUST
Отдельные статьи и личные проработки для понимания концепции RUST
- Трейт-объекты
- Ключевое слово
dynи трейт -объекты join- Трейты замыканий
FnOneFnMutFn - Итераторы
- Ассоциированный тип
whereдля ограничения трейтов
План статей с понятиями
Трейт-объекты в Rust: концепция и применение
Что такое трейт-объекты и зачем они нужны?
Трейт-объекты (trait objects) в Rust - это механизм для реализации динамического полиморфизма, позволяющий работать с разными типами через общий интерфейс во время выполнения программы.
Проблема, которую решают трейт-объекты
Представьте, что у вас есть несколько структур с разной реализацией, но общим поведением:
#![allow(unused)] fn main() { struct Circle { radius: f64, } struct Square { side: f64, } trait Shape { fn area(&self) -> f64; fn perimeter(&self) -> f64; } impl Shape for Circle { fn area(&self) -> f64 { std::f64::consts::PI * self.radius * self.radius } fn perimeter(&self) -> f64 { 2.0 * std::f64::consts::PI * self.radius } } impl Shape for Square { fn area(&self) -> f64 { self.side * self.side } fn perimeter(&self) -> f64 { 4.0 * self.side } } }
Проблема: как создать коллекцию, содержащую разные типы, реализующие один и тот же трейт?
Синтаксис трейт-объектов
Ключевое слово dyn
Ключевое слово dyn указывает, что мы работаем с трейт-объектом - динамически диспетчеризуемым типом:
#![allow(unused)] fn main() { // Трейт-объект, реализующий трейт Shape let shape: &dyn Shape = &Circle { radius: 5.0 }; }
Box<dyn Trait> для хранения в куче
Поскольку размер трейт-объектов неизвестен на этапе компиляции, мы часто используем Box для хранения их в куче:
#![allow(unused)] fn main() { fn create_shapes() -> Vec<Box<dyn Shape>> { vec![ Box::new(Circle { radius: 5.0 }), Box::new(Square { side: 4.0 }), ] } }
Как работают трейт-объекты под капотом
Таблица виртуальных методов (vtable)
Когда создается трейт-объект, Rust создает структуру, содержащую два указателя:
- Указатель на данные - ссылка на конкретный объект
- Указатель на vtable - таблицу виртуальных методов
#![allow(unused)] fn main() { // Примерное представление в памяти struct TraitObject { data: *mut (), vtable: *mut (), } }
Динамическая диспетчеризация
В отличие от статической диспетчеризации (мономорфизации), где компилятор генерирует отдельные функции для каждого типа, трейт-объекты используют динамическую диспетчеризацию:
#![allow(unused)] fn main() { // Статическая диспетчеризация (раннее связывание) fn print_area_static<T: Shape>(shape: &T) { println!("Area: {}", shape.area()); // Вызов определяется на этапе компиляции } // Динамическая диспетчеризация (позднее связывание) fn print_area_dynamic(shape: &dyn Shape) { println!("Area: {}", shape.area()); // Вызов определяется во время выполнения } }
Практическое применение
Коллекции гетерогенных объектов
fn process_shapes(shapes: &[&dyn Shape]) { for shape in shapes { println!("Area: {:.2}, Perimeter: {:.2}", shape.area(), shape.perimeter()); } } fn main() { let circle = Circle { radius: 3.0 }; let square = Square { side: 2.0 }; let shapes: Vec<&dyn Shape> = vec![&circle, &square]; process_shapes(&shapes); }
Возвращение трейт-объектов из функций
#![allow(unused)] fn main() { fn create_shape(shape_type: &str) -> Option<Box<dyn Shape>> { match shape_type { "circle" => Some(Box::new(Circle { radius: 1.0 })), "square" => Some(Box::new(Square { side: 1.0 })), _ => None, } } }
Ограничения и требования
Трейты должны быть "object-safe"
Не все трейты могут быть использованы как трейт-объекты. Трейт должен быть object-safe:
#![allow(unused)] fn main() { // Object-safe трейт trait Draw { fn draw(&self); } // НЕ object-safe - имеет generic метод trait Cloneable { fn clone<T>(&self) -> T; // Ошибка! Generic методы запрещены } // НЕ object-safe - возвращает Self trait Factory { fn create() -> Self; // Ошибка! Возврат Self запрещен } }
Основные правила object-safety:
- Не может иметь generic методов
- Не может возвращать
Self - Не может иметь статических методов
- Все методы должны принимать
selfв какой-либо форме
Сравнение с альтернативами
Трейт-объекты vs Generics
#![allow(unused)] fn main() { // Использование generics (статическая диспетчеризация) fn process_generic<T: Shape>(shape: &T) { shape.area(); } // Использование трейт-объектов (динамическая диспетчеризация) fn process_dynamic(shape: &dyn Shape) { shape.area(); } }
Преимущества трейт-объектов:
- Меньше дублирования кода
- Возможность работать с разными типами в одной коллекции
- Более гибкая архитектура
Недостатки:
- Небольшое снижение производительности (виртуальные вызовы)
- Невозможность использовать некоторые возможности (generic методы)
Продвинутые примеры
Трейт-объекты с временами жизни
#![allow(unused)] fn main() { trait Render<'a> { fn render(&self) -> &'a str; } struct Text<'a> { content: &'a str, } impl<'a> Render<'a> for Text<'a> { fn render(&self) -> &'a str { self.content } } fn render_objects<'a>(objects: Vec<Box<dyn Render<'a> + 'a>>) { for obj in objects { println!("{}", obj.render()); } } }
Комбинация трейт-объектов
#![allow(unused)] fn main() { trait Draw { fn draw(&self); } trait Serialize { fn serialize(&self) -> String; } // Трейт-объект, реализующий несколько трейтов fn process_object(obj: &(dyn Draw + Serialize)) { obj.draw(); println!("Serialized: {}", obj.serialize()); } }
Заключение
Трейт-объекты в Rust предоставляют мощный механизм для:
- Динамического полиморфизма - работы с разными типами через общий интерфейс
- Создания гетерогенных коллекций - хранения объектов разных типов в одной структуре данных
- Гибкой архитектуры - построения систем, где типы определяются во время выполнения
Ключевые концепции:
dyn Trait- указание на трейт-объектBox<dyn Trait>- хранение трейт-объектов в куче- Object-safety - требование к трейтам для использования в качестве трейт-объектов
- Vtable - механизм динамической диспетчеризации методов
Трейт-объекты особенно полезны в случаях, когда нужно работать с типами, неизвестными на этапе компиляции, или когда требуется высокая степень гибкости в архитектуре приложения.
dyn всегда указывает на трейт-объект в Rust
dynвсегда указывает на трейт-объект. Безdynвы работаете с статической диспетчеризацией через generics или конкретные типы.
Сравнение: с dyn vs без dyn
Без dyn - статическая диспетчеризация
trait Animal { fn speak(&self); } struct Dog; struct Cat; impl Animal for Dog { fn speak(&self) { println!("Woof!"); } } impl Animal for Cat { fn speak(&self) { println!("Meow!"); } } // Без dyn - generic функция (мономорфизация) fn make_speak_static<T: Animal>(animal: &T) { animal.speak(); // Компилятор генерирует специализированные версии } fn main() { let dog = Dog; let cat = Cat; make_speak_static(&dog); // Вызов Dog::speak make_speak_static(&cat); // Вызов Cat::speak }
С dyn - динамическая диспетчеризация
// С dyn - трейт-объект fn make_speak_dynamic(animal: &dyn Animal) { animal.speak(); // Диспетчеризация через vtable } fn main() { let dog = Dog; let cat = Cat; make_speak_dynamic(&dog as &dyn Animal); make_speak_dynamic(&cat); // Автоматическое приведение к &dyn Animal // Коллекция разных типов через трейт-объекты let animals: Vec<&dyn Animal> = vec![&dog, &cat]; for animal in animals { animal.speak(); // Динамический вызов } }
Ключевые различия
1. Время диспетчеризации
#![allow(unused)] fn main() { // БЕЗ dyn - статическая (compile-time) fn process<T: Animal>(animal: &T) { animal.speak(); // Компилятор знает точный тип T } // С dyn - динамическая (runtime) fn process(animal: &dyn Animal) { animal.speak(); // Тип определяется во время выполнения } }
2. Размер типа
#![allow(unused)] fn main() { // БЕЗ dyn - известный размер fn size_static<T: Animal>() { println!("Size: {}", std::mem::size_of::<T>()); // Известно при компиляции } // С dyn - неизвестный размер (dynamically sized type - DST) fn use_dynamic(animal: &dyn Animal) { // &dyn Animal - это fat pointer (2 указателя) println!("Size of fat pointer: {}", std::mem::size_of::<&dyn Animal>()); } }
3. Использование в коллекциях
#![allow(unused)] fn main() { // НЕВОЗМОЖНО без dyn - разные конкретные типы // let animals: Vec<???> = vec![Dog, Cat]; // Ошибка! // ВОЗМОЖНО с dyn - общий трейт-объект let animals: Vec<Box<dyn Animal>> = vec![ Box::new(Dog), Box::new(Cat), ]; }
Когда dyn обязателен, а когда опционален
Обязателен для трейт-объектов
#![allow(unused)] fn main() { trait MyTrait {} // Эти объявления ТРЕБУЮТ dyn: let obj: &dyn MyTrait; let boxed: Box<dyn MyTrait>; let rc: Rc<dyn MyTrait>; // Функции, принимающие трейт-объекты: fn take_trait_obj(obj: &dyn MyTrait) {} fn return_trait_obj() -> Box<dyn MyTrait> {} }
Не требуется для generics
#![allow(unused)] fn main() { // Без dyn - bounds через generics fn generic_func<T: MyTrait>(item: &T) {} // Или с impl Trait (тоже без dyn) fn impl_func(item: &impl MyTrait) {} fn return_impl() -> impl MyTrait {} }
Практические примеры различий
Пример 1: Производительность
#![allow(unused)] fn main() { use std::time::Instant; trait Calculator { fn compute(&self, x: i32) -> i32; } struct FastCalc; struct SlowCalc; impl Calculator for FastCalc { fn compute(&self, x: i32) -> i32 { x * 2 } } impl Calculator for SlowCalc { fn compute(&self, x: i32) -> i32 { // Имитация тяжелой операции std::thread::sleep(std::time::Duration::from_millis(1)); x * 2 } } // Статическая диспетчеризация (без dyn) fn benchmark_static<T: Calculator>(calc: &T, data: &[i32]) -> Vec<i32> { data.iter().map(|&x| calc.compute(x)).collect() } // Динамическая диспетчеризация (с dyn) fn benchmark_dynamic(calc: &dyn Calculator, data: &[i32]) -> Vec<i32> { data.iter().map(|&x| calc.compute(x)).collect() } }
Пример 2: Гибкость архитектуры
#![allow(unused)] fn main() { trait Plugin { fn execute(&self); } struct PluginA; struct PluginB; impl Plugin for PluginA { fn execute(&self) { println!("Plugin A") } } impl Plugin for PluginB { fn execute(&self) { println!("Plugin B") } } // Без dyn - нужно знать типы на этапе компиляции struct StaticPluginManager<T: Plugin> { plugin: T, } // С dyn - можно загружать плагины динамически struct DynamicPluginManager { plugins: Vec<Box<dyn Plugin>>, } impl DynamicPluginManager { fn add_plugin(&mut self, plugin: Box<dyn Plugin>) { self.plugins.push(plugin); } fn load_from_config(&mut self, config: &str) { // Динамическое создание плагинов на основе конфигурации if config.contains("plugin_a") { self.add_plugin(Box::new(PluginA)); } if config.contains("plugin_b") { self.add_plugin(Box::new(PluginB)); } } } }
Важные нюансы
Автоматическое приведение к dyn
#![allow(unused)] fn main() { let dog = Dog; // Явное указание let animal1: &dyn Animal = &dog; // Автоматическое приведение let animal2: &dyn Animal = &dog; // В функциях тоже работает автоматическое приведение make_speak_dynamic(&dog); // &Dog автоматически приводится к &dyn Animal }
dyn с временами жизни
#![allow(unused)] fn main() { trait Processor<'a> { fn process(&self, data: &'a str) -> &'a str; } // dyn с явным временем жизни fn use_processor<'a>(processor: &dyn Processor<'a>, data: &'a str) -> &'a str { processor.process(data) } }
Заключение
dynВСЕГДА указывает на трейт-объект с динамической диспетчеризацией- Без
dyn- вы используете статическую диспетчеризацию через generics dynобязателен когда вы явно работаете с трейт-объектамиdynне требуется при использовании generics bounds илиimpl Trait
Выбор между dyn и generics зависит от требований к производительности, гибкости архитектуры и необходимости работать с гетерогенными коллекциями.
Метод join() у потока в Rust делает следующее:
Что делает join()?
Блокирует выполнение текущего потока до тех пор, пока целевой поток не завершит свою работу.
В нашем примере:
#![allow(unused)] fn main() { thread::spawn(move || println!("From thread: {list:?}")) .join() // ← ОСНОВНАЯ ТОЧКА .unwrap(); }
Без join():
#![allow(unused)] fn main() { thread::spawn(move || println!("From thread: {list:?}")); // основной поток продолжает выполнение немедленно // порожденный поток может не успеть выполниться // программа может завершиться до выполнения потока }
С join():
#![allow(unused)] fn main() { thread::spawn(move || println!("From thread: {list:?}")) .join() // основной поток ЖДЕТ здесь .unwrap(); // основной поток продолжит ТОЛЬКО после завершения порожденного потока }
Возвращаемое значение:
join()возвращаетResult<T, Box<dyn Any + Send + 'static>>T- тип значения, возвращаемого из замыкания потокаunwrap()извлекает это значение или паникует при ошибке
Пример с возвращаемым значением:
#![allow(unused)] fn main() { let handle = thread::spawn(|| { println!("Поток выполняется"); 42 // возвращаем значение }); let result = handle.join().unwrap(); println!("Поток вернул: {}", result); // Напечатает: "Поток вернул: 42" }
Практический результат в вашем коде:
Гарантирует, что сообщение "From thread: [1, 2, 3]" будет напечатано до того, как основная функция main() завершится и программа закроется.
Характеристики трейтов замыканий в Rust
FnOnce
- Гарантии: Можно вызвать хотя бы один раз
- Захват значений: Может перемещать захваченные значения из своего тела
- Модификация: Может потреблять захваченные значения
- Использование: Только однократный вызов
- Пример:
#![allow(unused)] fn main() { let s = String::from("hello"); let closure = move || { println!("{}", s); // s перемещается в замыкание drop(s); // значение потребляется }; closure(); // можно вызвать только один раз // closure(); // ошибка! второй вызов невозможен }
FnMut
- Гарантии: Можно вызвать многократно
- Захват значений: Не перемещает значения, но может изменять захваченные значения
- Модификация: Требует
&mut selfдля вызова - Использование: Многократный вызов с возможностью мутации
- Пример:
#![allow(unused)] fn main() { let mut count = 0; let mut closure = || { count += 1; // изменяет захваченное значение println!("Count: {}", count); }; closure(); // Count: 1 closure(); // Count: 2 - можно вызывать многократно }
Fn
- Гарантии: Можно вызвать многократно без побочных эффектов
- Захват значений: Не перемещает и не изменяет захваченные значения (или ничего не захватывает)
- Модификация: Требует
&selfдля вызова - Использование: Многократный вызов, безопасность для многопоточности
- Пример:
#![allow(unused)] fn main() { let x = 10; let closure = || { println!("x = {}", x); // только чтение, без изменений }; closure(); // x = 10 closure(); // x = 10 - можно вызывать многократно }
Иерархия реализации:
FnOnce (базовый)
↑
FnMut
↑
Fn (наиболее ограничивающий)
Правило: Если замыкание реализует Fn, оно автоматически реализует FnMut и FnOnce. Если реализует FnMut, то автоматически реализует FnOnce.
Определение по использованию:
- Перемещает значения? → Только
FnOnce - Изменяет значения? →
FnMut(иFnOnce) - Только читает? →
Fn(иFnMut, иFnOnce)
Итераторы
Что такое итератор в Rust?
Итератор в Rust — это трейт (
std::iter::Iterator).
Трейт Iterator:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // ... множество предоставляемых методов по умолчанию } }
Создание итераторов:
1. Из коллекций (реализуют трейт IntoIterator):
#![allow(unused)] fn main() { let vec = vec![1, 2, 3]; let iter = vec.iter(); // Итератор по &T let iter_mut = vec.iter_mut(); // Итератор по &mut T let into_iter = vec.into_iter(); // Итератор, потребляющий коллекцию (T) }
2. Диапазоны:
#![allow(unused)] fn main() { let range = 1..10; // 1 до 9 let range_inclusive = 1..=10; // 1 до 10 }
3. Адаптеры итераторов:
#![allow(unused)] fn main() { let mapped = vec.iter().map(|x| x * 2); let filtered = vec.iter().filter(|x| *x % 2 == 0); }
4. Создание кастомных итераторов:
#![allow(unused)] fn main() { struct Counter { count: u32, } impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { if self.count < 5 { self.count += 1; Some(self.count) } else { None } } } }
Организация в памяти:
Размер на стеке:
- Итераторы обычно имеют фиксированный размер во время компиляции
- Не требуют heap-аллокации (если не содержат
Boxи т.д.) - Пример:
#![allow(unused)] fn main() { let iter = vec![1, 2, 3].into_iter(); // Размер известен компилятору, хранится на стеке }
Типы итераторов:
- By-reference:
iter()→std::slice::Iter<'a, T> - By-mutable-reference:
iter_mut()→std::slice::IterMut<'a, T> - By-value:
into_iter()→std::vec::IntoIter<T>
Потребители итераторов:
1. Явное использование next():
#![allow(unused)] fn main() { let mut iter = vec![1, 2, 3].iter(); while let Some(item) = iter.next() { println!("{}", item); } }
2. Цикл for (синтаксический сахар):
#![allow(unused)] fn main() { for item in vec.iter() { println!("{}", item); // Автоматически вызывает next() } }
3. Методы-потребители:
#![allow(unused)] fn main() { let sum: i32 = vec.iter().sum(); // Потребляет итератор let collected: Vec<_> = iter.collect(); // Потребляет итератор let count = iter.count(); // Потребляет итератор }
4. Адаптеры (ленивые, не потребляют сразу):
#![allow(unused)] fn main() { let result: Vec<_> = vec![1, 2, 3] .iter() .map(|x| x * 2) // Ленивый - не выполняется до потребления .filter(|x| x > &2) // Ленивый .collect(); // Потребляет, форсирует вычисления }
Ключевые особенности:
Ленивость:
#![allow(unused)] fn main() { let iter = vec![1, 2, 3].iter().map(|x| { println!("Processing: {}", x); x * 2 }); // Ничего не напечатано - вычисления не начались let result: Vec<_> = iter.collect(); // Теперь вычисления выполнены }
Zero-cost abstractions:
- Итераторы компилируются в эффективный код
- Часто сопоставим с ручным циклом по производительности
Типовая система:
#![allow(unused)] fn main() { fn process<I: Iterator<Item = i32>>(iter: I) { for item in iter { println!("{}", item); } } }
Итератор в Rust — это трейт, который предоставляет поток элементов, с ленивыми вычислениями и эффективной компиляцией в оптимальный машинный код.
Ассоциированный тип
Подробное объяснение на пальцах ассоциированного типа в Rust
Создадим свой трейт с ассоциированным типом:
Пример 1: Трейт Container
#![allow(unused)] fn main() { // Определяем трейт с ассоциированным типом trait Container { type Item; // Ассоциированный тип - "какой-то тип элемента" fn get(&self) -> &Self::Item; fn put(&mut self, value: Self::Item); } // Реализация для структуры, хранящей i32 struct NumberBox { value: i32, } impl Container for NumberBox { type Item = i32; // Конкретизируем: здесь элементы - i32 fn get(&self) -> &Self::Item { &self.value } fn put(&mut self, value: Self::Item) { self.value = value; } } // Реализация для структуры, хранящей String struct StringBox { value: String, } impl Container for StringBox { type Item = String; // Конкретизируем: здесь элементы - String fn get(&self) -> &Self::Item { &self.value } fn put(&mut self, value: Self::Item) { self.value = value; } } }
Пример 2: Трейт Producer
#![allow(unused)] fn main() { trait Producer { type Output; // "Я производлю значения какого-то типа" fn produce(&self) -> Self::Output; } // Реализация для генератора чисел struct NumberGenerator { start: i32, } impl Producer for NumberGenerator { type Output = i32; // Производит i32 fn produce(&self) -> Self::Output { self.start + 42 } } // Реализация для генератора строк struct GreetingGenerator; impl Producer for GreetingGenerator { type Output = String; // Производит String fn produce(&self) -> Self::Output { "Hello!".to_string() } } }
Пример 3: Трейт Converter
#![allow(unused)] fn main() { trait Converter { type Input; type Output; // Два ассоциированных типа! fn convert(value: Self::Input) -> Self::Output; } // Конвертер i32 -> String struct StringConverter; impl Converter for StringConverter { type Input = i32; type Output = String; fn convert(value: Self::Input) -> Self::Output { value.to_string() } } // Конвертер String -> usize struct LengthConverter; impl Converter for LengthConverter { type Input = String; type Output = usize; fn convert(value: Self::Input) -> Self::Output { value.len() } } }
Как это использовать:
fn use_container<C: Container>(container: &C) { let item = container.get(); println!("Item: {:?}", item); } fn use_producer<P: Producer>(producer: &P) where P::Output: std::fmt::Display, // Ограничение на ассоциированный тип { let output = producer.produce(); println!("Produced: {}", output); } fn main() { let num_box = NumberBox { value: 10 }; let str_box = StringBox { value: "hello".to_string() }; use_container(&num_box); // Item: 10 use_container(&str_box); // Item: "hello" let num_gen = NumberGenerator { start: 5 }; let greet_gen = GreetingGenerator; use_producer(&num_gen); // Produced: 47 use_producer(&greet_gen); // Produced: Hello! }
Ключевая идея:
Ассоциированный тип — это "дырка для типа", которую заполняют при реализации трейта:
- В трейте:
type Item— "будет какой-то тип" - В impl:
type Item = КонкретныйТип— "вот именно этот тип"
Чем отличается от дженериков:
#![allow(unused)] fn main() { // С дженериком - можно много реализаций для одного типа trait GenericContainer<T> { fn get(&self) -> &T; } impl GenericContainer<i32> for NumberBox { /* ... */ } impl GenericContainer<String> for NumberBox { /* ... */ } // Две реализации! // С ассоциированным типом - только одна реализация impl Container for NumberBox { type Item = i32; // Только один тип может быть Item! // ... } }
Ассоциированный тип связывает тип элемента с самой реализацией трейта, а не с каждым вызовом метода.
where для ограничения трейтов
where— это ключевое слово в Rust для указания ограничений трейтов (trait bounds) в более читаемом и гибком формате.
Синтаксис where:
Без where (обычный синтаксис):
#![allow(unused)] fn main() { fn process<T: Display + Clone, U: Debug>(a: T, b: U) -> String { format!("{} {:?}", a, b) } }
С where (более чистый синтаксис):
#![allow(unused)] fn main() { fn process<T, U>(a: T, b: U) -> String where T: Display + Clone, U: Debug, { format!("{} {:?}", a, b) } }
Преимущества where:
1. Лучшая читаемость для сложных случаев:
#![allow(unused)] fn main() { // Без where - очень длинная строка fn complicated<A: Copy + Debug, B: Clone + Debug, C: Iterator<Item = i32>>(a: A, b: B, c: C) {} // С where - намного чище fn complicated<A, B, C>(a: A, b: B, c: C) where A: Copy + Debug, B: Clone + Debug, C: Iterator<Item = i32>, {} }
2. Работа с ассоциированными типами:
#![allow(unused)] fn main() { // Ограничения на ассоциированные типы fn process_iterator<I>(iter: I) where I: Iterator, I::Item: Display + Clone, // Ограничение на ассоциированный тип! { for item in iter { println!("{}", item); } } }
Примеры с трейтами и where:
Пример 1: Сложные ограничения
use std::fmt::{Display, Debug}; fn compare_and_print<T, U>(left: T, right: U) where T: Display + PartialEq<U>, U: Display + Debug, { if left == right { println!("{} equals {}", left, right); } else { println!("{} not equals {:?}", left, right); } } fn main() { compare_and_print(10, 10); // 10 equals 10 compare_and_print("hello", 42); // hello not equals 42 }
Пример 2: Ограничения на ассоциированные типы
#![allow(unused)] fn main() { trait Storage { type Key; type Value; fn get(&self, key: &Self::Key) -> Option<&Self::Value>; } // Используем where для сложных ограничений fn find_and_print<S>(storage: &S, key: &S::Key) where S: Storage, S::Key: Debug, // Ключ должен реализовывать Debug S::Value: Display, // Значение должно реализовывать Display { match storage.get(key) { Some(value) => println!("Found: {} for key: {:?}", value, key), None => println!("Not found for key: {:?}", key), } } }
Пример 3: Множественные типы и трейты
use std::ops::Add; fn sum_with_label<T, U>(a: T, b: T, label: U) -> String where T: Add<Output = T> + Copy + Display, U: Display, { let result = a + b; format!("{}: {}", label, result) } fn main() { let result = sum_with_label(5, 10, "Sum"); println!("{}", result); // Sum: 15 }
Особые случаи с where:
1. Ограничения для ссылок:
#![allow(unused)] fn main() { fn process_ref<T>(value: &T) where &T: Display, // Ограничение на ссылочный тип! { println!("{}", value); } }
2. Условные реализации с where:
#![allow(unused)] fn main() { struct Wrapper<T>(T); // Реализуем трейт только когда T удовлетворяет условиям impl<T> Display for Wrapper<T> where T: Display, { fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result { write!(f, "Wrapper({})", self.0) } } }
3. Сложные комбинации трейтов:
#![allow(unused)] fn main() { fn complex_function<A, B, C>(a: A, b: B, c: C) where A: Clone + IntoIterator<Item = B>, B: PartialEq<C> + Debug, C: Display, { for item in a.clone() { if item == b { println!("Match: {} == {:?}", c, item); } } } }
Практическое применение:
Работа с итераторами и where:
fn filter_and_collect<I, F>(iter: I, predicate: F) -> Vec<I::Item> where I: IntoIterator, I::Item: Clone, F: Fn(&I::Item) -> bool, { iter.into_iter() .filter(predicate) .collect() } fn main() { let numbers = vec![1, 2, 3, 4, 5]; let even = filter_and_collect(numbers, |x| x % 2 == 0); println!("{:?}", even); // [2, 4] }
Итог:
where делает код:
- ✅ Более читаемым для сложных ограничений трейтов
- ✅ Более гибким для работы с ассоциированными типами
- ✅ Более структурированным для множественных ограничений
Используйте where когда ограничения трейтов становятся слишком длинными или сложными для обычного синтаксиса!
Синтаксис &impl Trait
implв этом контексте создает синтаксическое сокращение для ограничения типажа (trait bound).
1. Без impl — что было бы?
Если бы не было impl, синтаксис стал бы неоднозначным:
#![allow(unused)] fn main() { // Так НЕ работает в Rust! pub fn notify(item: &Summary) { // ❌ Не компилируется! println!("Breaking news! {}", item.summarize()); } }
Почему это проблема? Потому что Summary — это типаж (trait), а не тип. В Rust нельзя иметь переменные или параметры типа "просто типаж" — это намеренное дизайнерское решение.
2. Альтернатива — явные ограничения типажей
Без impl синтаксис был бы более многословным:
#![allow(unused)] fn main() { // Явное ограничение типажа (trait bound) pub fn notify<T: Summary>(item: &T) { println!("Breaking news! {}", item.summarize()); } }
3. Преимущества impl синтаксиса
✅ Лаконичность для простых случаев
#![allow(unused)] fn main() { // Коротко и понятно pub fn notify(item: &impl Summary) { ... } // Против более многословного pub fn notify<T: Summary>(item: &T) { ... } }
✅ Удобство для нескольких параметров
#![allow(unused)] fn main() { // С impl - могут быть разные типы, реализующие Summary pub fn notify(item1: &impl Summary, item2: &impl Summary) { ... } // С generic - тот же тип T для обоих параметров pub fn notify<T: Summary>(item1: &T, item2: &T) { ... } // Если нужны разные типы с generic - многословно pub fn notify<T: Summary, U: Summary>(item1: &T, item2: &U) { ... } }
4. Когда использовать impl, а когда явные generic
Используйте impl:
#![allow(unused)] fn main() { // Простые случаи с одним параметром pub fn display(item: &impl Display) { ... } // Когда параметры могут быть разных типов pub fn compare(a: &impl Display, b: &impl Display) { ... } }
Используйте явные generic:
#![allow(unused)] fn main() { // Когда нужна связь между параметрами pub fn same_type(a: &T, b: &T) -> bool { ... } // Когда тип появляется в возвращаемом значении pub fn factory<T: Default>() -> T { ... } // Для сложных ограничений типажей pub fn complex<T: Summary + Display + Clone>(item: &T) { ... } // Для where clauses pub fn advanced<T>(item: &T) where T: Summary + Serialize { ... } }
5. Что на самом деле происходит
Оба варианта эквивалентны с точки зрения компилятора:
#![allow(unused)] fn main() { // Эти две функции мономорфизируются одинаково pub fn notify_impl(item: &impl Summary) { ... } pub fn notify_generic<T: Summary>(item: &T) { ... } }
Компилятор создает специализированные версии функций для каждого конкретного типа, который передается в функцию.
Итог
impl в параметрах функций — это синтаксический сахар, который:
- Делает код более читаемым для простых случаев
- Избегает введения лишних generic-параметров
- Сохраняет гибкость типизации
- Остается полностью типобезопасным
Union в Rust: объяснение с примерами
Что такое Union?
Union (объединение) в Rust - это специальный тип данных, который позволяет хранить разные типы данных в одной области памяти. В отличие от enum, union не имеет тега для отслеживания активного варианта, что делает его небезопасным для использования.
Основные характеристики:
- Размер памяти равен размеру самого большого поля
- Одновременно активно только одно поле
- Небезопасный доступ - компилятор не проверяет, какое поле активно
- Требует unsafe для чтения и записи
Синтаксис объявления
#![allow(unused)] fn main() { union MyUnion { field1: u32, field2: f32, field3: [u8; 4], } }
Пример 1: Базовое использование
union IntOrFloat { integer: u32, float: f32, } fn main() { // Создание union let mut value = IntOrFloat { integer: 42 }; // Небезопасное чтение - мы должны знать, какое поле активно! unsafe { println!("Integer value: {}", value.integer); } // Запись другого поля value.float = 3.14; // Чтение как float (теперь это активное поле) unsafe { println!("Float value: {}", value.float); // ОПАСНО: чтение неактивного поля! // println!("Integer value: {}", value.integer); // Неопределенное поведение! } }
Пример 2: Преобразование байтов
union BytesConverter { value: u32, bytes: [u8; 4], } fn main() { let converter = BytesConverter { value: 0x12345678 }; unsafe { println!("Value: 0x{:x}", converter.value); println!("Bytes: {:02x} {:02x} {:02x} {:02x}", converter.bytes[0], converter.bytes[1], converter.bytes[2], converter.bytes[3]); } // Порядок байтов зависит от архитектуры! // На little-endian: [0x78, 0x56, 0x34, 0x12] // На big-endian: [0x12, 0x34, 0x56, 0x78] }
Пример 3: Работа с разными типами данных
union MultiType { number: i32, character: char, boolean: bool, pointer: *const i32, } fn main() { let data = [10, 20, 30]; let mut multi = MultiType { number: 100 }; unsafe { println!("Number: {}", multi.number); } // Меняем активное поле multi.character = 'A'; unsafe { println!("Character: {}", multi.character); } multi.boolean = true; unsafe { println!("Boolean: {}", multi.boolean); } multi.pointer = data.as_ptr(); unsafe { println!("Pointer: {:?}", multi.pointer); println!("Dereferenced: {}", *multi.pointer); } }
Пример 4: Безопасная обертка вокруг union
use std::mem; #[derive(Debug)] enum ActiveField { Integer, Float, Bytes, } struct SafeUnion { data: IntOrFloatOrBytes, active: ActiveField, } union IntOrFloatOrBytes { integer: i32, float: f32, bytes: [u8; 4], } impl SafeUnion { fn new_integer(value: i32) -> Self { SafeUnion { data: IntOrFloatOrBytes { integer: value }, active: ActiveField::Integer, } } fn new_float(value: f32) -> Self { SafeUnion { data: IntOrFloatOrBytes { float: value }, active: ActiveField::Float, } } fn get_integer(&self) -> Option<i32> { if let ActiveField::Integer = self.active { unsafe { Some(self.data.integer) } } else { None } } fn get_float(&self) -> Option<f32> { if let ActiveField::Float = self.active { unsafe { Some(self.data.float) } } else { None } } fn set_integer(&mut self, value: i32) { self.data.integer = value; self.active = ActiveField::Integer; } fn set_float(&mut self, value: f32) { self.data.float = value; self.active = ActiveField::Float; } } fn main() { let mut safe_union = SafeUnion::new_integer(42); println!("As integer: {:?}", safe_union.get_integer()); println!("As float: {:?}", safe_union.get_float()); safe_union.set_float(3.14); println!("As integer: {:?}", safe_union.get_integer()); println!("As float: {:?}", safe_union.get_float()); }
Пример 5: Совместимость с C
// Для взаимодействия с C кодом #[repr(C)] union CCompatible { long_value: i64, double_value: f64, struct_value: [u32; 2], } // Использование в FFI extern "C" { fn some_c_function(param: *const CCompatible); } fn main() { let data = CCompatible { long_value: 12345 }; unsafe { some_c_function(&data); } }
Пример 6: ManuallyDrop для автоматического управления памятью
#![allow(unused)] fn main() { use std::mem::ManuallyDrop; union StringOrInt { string: ManuallyDrop<String>, number: i32, } impl StringOrInt { fn new_string(s: String) -> Self { StringOrInt { string: ManuallyDrop::new(s), } } fn new_number(n: i32) -> Self { StringOrInt { number: n } } // Опасный метод - нужно вручную управлять временем жизни unsafe fn take_string(&mut self) -> String { if let ActiveField::String = self.active { ManuallyDrop::take(&mut self.string) } else { panic!("Active field is not string!"); } } } impl Drop for StringOrInt { fn drop(&mut self) { // Нужно вручную вызывать деструктор для String unsafe { if let ActiveField::String = self.active { ManuallyDrop::drop(&mut self.string); } } } } }
Ключевые моменты для запоминания:
- ⚠️ Все операции с union требуют unsafe - компилятор не может гарантировать безопасность
- Вы сами отвечаете за отслеживание активного поля
- Чтение неактивного поля - неопределенное поведение
- Размер union = размер самого большого поля + выравнивание
- Инициализировать нужно только одно поле при создании
Когда использовать union:
- Взаимодействие с C кодом
- Экономия памяти в критических местах
- Низкоуровневые операции с памятью
- Альтернативные представления данных
Альтернативы:
- Enum - безопасный вариант, когда нужны разные типы
- Struct - когда все поля должны быть доступны одновременно
- Transmute - для простых преобразований типов
Warning
Union в Rust - это мощный, но опасный инструмент. Используйте его только когда действительно необходимо, и всегда обеспечивайте безопасную обертку вокруг него!
Ключевое слово as в Rust: основные способы применения
1. Приведение числовых типов
fn main() { // Целочисленные преобразования let x: i32 = 42; let y: u64 = x as u64; println!("i32 {} -> u64 {}", x, y); // С плавающей точкой let float_num: f64 = 3.14; let int_num: i32 = float_num as i32; // Дробная часть отбрасывается println!("f64 {} -> i32 {}", float_num, int_num); // Беззнаковые в знаковые let unsigned: u8 = 200; let signed: i8 = unsigned as i8; // Может привести к переполнению println!("u8 {} -> i8 {}", unsigned, signed); // Между целыми разного размера let large: i128 = 1000; let small: i8 = large as i8; // Обрезание битов println!("i128 {} -> i8 {}", large, small); }
2. Преобразования с плавающей точкой
fn main() { // Float <-> Integer let pi: f32 = 3.14159; let pi_int = pi as i32; println!("f32 {} -> i32 {}", pi, pi_int); // 3 // Обратное преобразование let count: i32 = 42; let count_float = count as f64; println!("i32 {} -> f64 {}", count, count_float); // Между float типами let float32: f32 = 2.5; let float64: f64 = float32 as f64; println!("f32 {} -> f64 {}", float32, float64); }
3. Работа с указателями
fn main() { let x = 42; // Создание сырых указателей let raw_ptr: *const i32 = &x as *const i32; println!("Raw pointer: {:?}", raw_ptr); // Преобразование между типами указателей let mut y = 100; let const_ptr: *const i32 = &y as *const i32; let mut_ptr: *mut i32 = &mut y as *mut i32; // Преобразование указателей разных типов let byte_ptr = const_ptr as *const u8; println!("i32 pointer: {:?} -> u8 pointer: {:?}", const_ptr, byte_ptr); // Приведение к usize для арифметики указателей let addr = const_ptr as usize; println!("Pointer as usize: 0x{:x}", addr); }
4. Преобразования с enum
fn main() { // Enum без данных -> целые числа enum Color { Red = 0xff0000, Green = 0x00ff00, Blue = 0x0000ff, } let color_value = Color::Red as i32; println!("Color Red as i32: 0x{:x}", color_value); // C-like enums #[repr(u8)] enum Status { Ok = 0, Error = 1, Loading = 2, } let status_code = Status::Error as u8; println!("Status code: {}", status_code); // Bool -> integer let true_as_int = true as i32; // 1 let false_as_int = false as i32; // 0 println!("true as i32: {}, false as i32: {}", true_as_int, false_as_int); }
5. Работа с массивами и срезами
fn main() { // Приведение ссылок на массивы let arr: [i32; 4] = [1, 2, 3, 4]; let slice: &[i32] = &arr as &[i32]; println!("Array as slice: {:?}", slice); // Байтовые представления let value: u32 = 0x12345678; let bytes: &[u8] = unsafe { std::slice::from_raw_parts( &value as *const u32 as *const u8, std::mem::size_of::<u32>() ) }; println!("u32 0x{:x} as bytes: {:?}", value, bytes); // Приведение размеров срезов (осторожно!) let int_slice: &[i32] = &[1, 2, 3, 4]; let byte_slice: &[u8] = unsafe { std::slice::from_raw_parts( int_slice.as_ptr() as *const u8, int_slice.len() * std::mem::size_of::<i32>() ) }; println!("i32 slice as u8 slice: {:?}", byte_slice); }
6. Преобразования в трейт-объекты
trait Animal { fn speak(&self); } struct Dog; struct Cat; impl Animal for Dog { fn speak(&self) { println!("Woof!"); } } impl Animal for Cat { fn speak(&self) { println!("Meow!"); } } fn main() { let dog = Dog; let cat = Cat; // Создание трейт-объектов let animal1: &dyn Animal = &dog as &dyn Animal; let animal2: &dyn Animal = &cat as &dyn Animal; animal1.speak(); animal2.speak(); // Boxed trait objects let boxed_animal: Box<dyn Animal> = Box::new(Dog) as Box<dyn Animal>; boxed_animal.speak(); }
7. Явное приведение типов в выражениях
fn main() { // Для разрешения неоднозначности let result1 = 10 as f64 / 3.0; let result2 = 10 / 3 as f64; println!("10 as f64 / 3.0 = {}", result1); // 3.333... println!("10 / 3 as f64 = {}", result2); // 3.0 // В арифметических операциях let a: u8 = 100; let b: u8 = 200; let sum = a as u16 + b as u16; // Предотвращаем переполнение println!("{} + {} = {} (as u16)", a, b, sum); // При работе с индексами let arr = [10, 20, 30, 40]; let index: i32 = 2; let element = arr[index as usize]; // Приведение для индексации println!("arr[{}] = {}", index, element); }
8. Преобразования с char
fn main() { // Char <-> числовые типы let letter = 'A'; let letter_code = letter as u8; println!("'{}' as u8: {}", letter, letter_code); let number = 66u8; let character = number as char; println!("{} as char: '{}'", number, character); // Unicode символы let heart = '💖'; let heart_code = heart as u32; println!("'{}' as u32: 0x{:x}", heart, heart_code); // Осторожно: не все числовые значения - валидные char let invalid_char = 0xD800 as char; // Это surrogate pair, не валидный char! println!("Invalid char: {:?}", invalid_char); // Может привести к неопределенному поведению }
9. Приведение в замыканиях и функциях
fn main() { // Приведение типов функций fn normal_function(x: i32) -> i32 { x * 2 } let function_ptr: fn(i32) -> i32 = normal_function as fn(i32) -> i32; println!("Function result: {}", function_ptr(21)); // Замыкания (требуют осторожности) let closure = |x: i32| x + 1; let closure_ptr: fn(i32) -> i32 = closure as fn(i32) -> i32; println!("Closure result: {}", closure_ptr(10)); // Приведение к указателям на функции type MathFn = fn(i32, i32) -> i32; fn add(a: i32, b: i32) -> i32 { a + b } fn multiply(a: i32, b: i32) -> i32 { a * b } let operations: [MathFn; 2] = [ add as MathFn, multiply as MathFn, ]; for op in operations.iter() { println!("Operation result: {}", op(5, 3)); } }
10. Ограничения и безопасность
fn main() { // НЕЛЬЗЯ приводить между произвольными типами struct Point { x: i32, y: i32 } // let p = Point { x: 1, y: 2 }; // let invalid = p as String; // Ошибка компиляции! // Осторожно с потерями точности let large: u64 = u64::MAX; let small: u32 = large as u32; // Потеря данных! println!("u64::MAX {} -> u32 {}", large, small); // Приведение с насыщением (альтернатива) let saturated = large.min(u32::MAX as u64) as u32; println!("Saturated conversion: {}", saturated); }
Важные замечания:
asне выполняет проверки - это простое битовое преобразование- Может терять данные при числовых преобразованиях
- Небезопасно для некоторых преобразований указателей
- Альтернативы:
.try_into(),.into()для безопасных преобразований - Для сложных преобразований используйте
std::convert
Используйте as осторожно и только когда понимаете последствия преобразования!
Привязка образца @
В языке Rust оператор
@называется "bind operator" (оператор привязки) и используется для создания привязки значения к переменной внутри паттерн-матчинга.
Основная концепция
Оператор @ позволяет:
- Проверить, соответствует ли значение паттерну
- Одновременно привязать это значение к переменной
Синтаксис
#![allow(unused)] fn main() { переменная @ паттерн }
Примеры использования
1. Привязка в диапазонах
fn check_number(n: u32) { match n { x @ 0..=9 => println!("Одна цифра: {}", x), x @ 10..=99 => println!("Две цифры: {}", x), x @ 100..=999 => println!("Три цифры: {}", x), _ => println!("Большое число"), } } fn main() { check_number(5); // Одна цифра: 5 check_number(42); // Две цифры: 42 check_number(123); // Три цифры: 123 }
2. Работа с перечислениями (enum)
#![allow(unused)] fn main() { enum Message { Text(String), Number(i32), Coordinate { x: i32, y: i32 }, } fn process_message(msg: Message) { match msg { Message::Text(text) @ Message::Text(_) => { println!("Текстовое сообщение: {}", text) }, Message::Number(n @ 0..=100) => { println!("Число в диапазоне 0-100: {}", n) }, Message::Coordinate { x, y } @ Message::Coordinate { x: 0..=10, y: 0..=10 } => { println!("Координата в квадрате 10x10: ({}, {})", x, y) }, _ => println!("Другое сообщение"), } } }
3. Сложные паттерны с условиями
#![allow(unused)] fn main() { fn process_value(val: Option<i32>) { match val { Some(x @ 1..=10) if x % 2 == 0 => { println!("Четное число от 1 до 10: {}", x) }, Some(x @ 1..=10) => { println!("Нечетное число от 1 до 10: {}", x) }, Some(x) => { println!("Другое число: {}", x) }, None => println!("Нет значения"), } } }
4. Работа со структурами
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } fn check_point(p: Point) { match p { point @ Point { x: 0..=5, y: 0..=5 } => { println!("Точка в квадрате 5x5: ({}, {})", point.x, point.y) }, Point { x, y } => { println!("Точка вне квадрата: ({}, {})", x, y) }, } } }
5. Вложенные паттерны
#![allow(unused)] fn main() { fn process_nested(value: Option<Option<i32>>) { match value { Some(inner @ Some(1..=10)) => { println!("Внутреннее значение: {:?}", inner) }, Some(Some(x)) => { println!("Другое значение: {}", x) }, Some(None) => println!("Внутренний None"), None => println!("Внешний None"), } } }
Преимущества использования @
- Избегание повторного вычисления - значение вычисляется только один раз
- Улучшенная читаемость - ясное указание на то, что значение используется в нескольких местах
- Более выразительный код - явно показывает связь между паттерном и привязкой
Когда использовать
Оператор @ особенно полезен когда:
- Нужно проверить сложный паттерн и использовать значение внутри блока
- Требуется избежать повторного вычисления или доступа к значению
- Паттерн сложный, но нужно сохранить доступ к оригинальному значению
Этот оператор делает код более выразительным и эффективным в ситуациях сложного паттерн-матчинга.
Traits
Сводная таблица методов и адаптеров Iterator в Rust
Базовые методы потребления
| Метод | Формат | Назначение |
|---|---|---|
next | fn next(&mut self) -> Option<Self::Item> | Возвращает следующий элемент |
size_hint | fn size_hint(&self) -> (usize, Option<usize>) | Оценка оставшегося количества элементов |
count | fn count(self) -> usize | Потребляет итератор, возвращая количество элементов |
last | fn last(self) -> Option<Self::Item> | Возвращает последний элемент |
advance_by | fn advance_by(&mut self, n: usize) -> Result<(), usize> | Пропускает n элементов |
nth | fn nth(&mut self, n: usize) -> Option<Self::Item> | Возвращает n-й элемент |
Методы потребления с преобразованием
| Метод | Формат | Назначение |
|---|---|---|
collect | fn collect<B>(self) -> B where B: FromIterator<Self::Item> | Преобразует в коллекцию |
partition | fn partition<B, F>(self, f: F) -> (B, B) | Разделяет на две коллекции по предикату |
try_fold | fn try_fold<B, F, R>(&mut self, init: B, f: F) -> R | Аккумулятор с возможностью ошибки |
fold | fn fold<B, F>(self, init: B, f: F) -> B | Аккумулятор (редукция) |
reduce | fn reduce<F>(self, f: F) -> Option<Self::Item> | Аккумулятор без начального значения |
try_reduce | fn try_reduce<F, R>(self, f: F) -> R | Reduce с возможностью ошибки |
all | fn all<F>(&mut self, f: F) -> bool | Проверяет, что все элементы удовлетворяют условию |
any | fn any<F>(&mut self, f: F) -> bool | Проверяет, что хотя бы один элемент удовлетворяет условию |
find | fn find<P>(&mut self, predicate: P) -> Option<Self::Item> | Находит первый элемент по предикату |
find_map | fn find_map<B, F>(&mut self, f: F) -> Option<B> | Находит и преобразует первый подходящий элемент |
try_find | fn try_find<F, R>(&mut self, f: F) -> R | Find с возможностью ошибки |
position | fn position<P>(&mut self, predicate: P) -> Option<usize> | Находит позицию элемента |
rposition | fn rposition<P>(&mut self, predicate: P) -> Option<usize> | Находит позицию с конца (только для ExactSizeIterator) |
max | fn max(self) -> Option<Self::Item> | Максимальный элемент |
min | fn min(self) -> Option<Self::Item> | Минимальный элемент |
max_by | fn max_by<F>(self, compare: F) -> Option<Self::Item> | Максимум по функции сравнения |
min_by | fn min_by<F>(self, compare: F) -> Option<Self::Item> | Минимум по функции сравнения |
max_by_key | fn max_by_key<B, F>(self, f: F) -> Option<Self::Item> | Максимум по ключу |
min_by_key | fn min_by_key<B, F>(self, f: F) -> Option<Self::Item> | Минимум по ключу |
sum | fn sum<S>(self) -> S | Сумма элементов |
product | fn product<P>(self) -> P | Произведение элементов |
Адаптеры, преобразующие элементы
| Метод | Формат | Назначение |
|---|---|---|
map | fn map<B, F>(self, f: F) -> Map<Self, F> | Преобразует каждый элемент |
for_each | fn for_each<F>(self, f: F) | Выполняет действие для каждого элемента |
filter_map | fn filter_map<B, F>(self, f: F) -> FilterMap<Self, F> | Фильтрация с преобразованием |
flat_map | fn flat_map<U, F>(self, f: F) -> FlatMap<Self, U, F> | Преобразует в итератор и сглаживает |
flatten | fn flatten(self) -> Flatten<Self> | Сглаживает вложенные итераторы |
inspect | fn inspect<F>(self, f: F) -> Inspect<Self, F> | Побочный эффект для каждого элемента |
Адаптеры фильтрации
| Метод | Формат | Назначение |
|---|---|---|
filter | fn filter<P>(self, predicate: P) -> Filter<Self, P> | Фильтрует элементы по условию |
take_while | fn take_while<P>(self, predicate: P) -> TakeWhile<Self, P> | Берет элементы, пока условие истинно |
skip_while | fn skip_while<P>(self, predicate: P) -> SkipWhile<Self, P> | Пропускает элементы, пока условие истинно |
map_while | fn map_while<B, P>(self, predicate: P) -> MapWhile<Self, P> | Map, который может остановить итерацию |
Адаптеры изменения размера
| Метод | Формат | Назначение |
|---|---|---|
take | fn take(self, n: usize) -> Take<Self> | Ограничивает количество элементов |
skip | fn skip(self, n: usize) -> Skip<Self> | Пропускает n элементов |
step_by | fn step_by(self, step: usize) -> StepBy<Self> | Берет каждый n-й элемент |
Адаптеры комбинирования итераторов
| Метод | Формат | Назначение |
|---|---|---|
chain | fn chain<U>(self, other: U) -> Chain<Self, U> | Объединяет два итератора |
zip | fn zip<U>(self, other: U) -> Zip<Self, U> | Объединяет попарно |
intersperse | fn intersperse(self, separator: Self::Item) -> Intersperse<Self> | Вставляет разделитель между элементами |
intersperse_with | fn intersperse_with<G>(self, separator: G) -> IntersperseWith<Self, G> | Вставляет разделитель через функцию |
Адаптеры копирования и клонирования
| Метод | Формат | Назначение |
|---|---|---|
copied | fn copied<'a, T>(self) -> Copied<Self> | Копирует элементы (для &T) |
cloned | fn cloned<'a, T>(self) -> Cloned<Self> | Клонирует элементы (для &T) |
Адаптеры циклов и повторений
| Метод | Формат | Назначение |
|---|---|---|
cycle | fn cycle(self) -> Cycle<Self> | Бесконечно повторяет итератор |
repeat | fn repeat(self) -> Repeat<Self> | Бесконечно повторяет элемент |
Адаптеры для работы с ошибками
| Метод | Формат | Назначение |
|---|---|---|
try_collect | fn try_collect<T>(&mut self) -> T | Collect с возможностью ошибки |
Специализированные адаптеры
| Метод | Формат | Назначение |
|---|---|---|
unzip | fn unzip<A, B, FromA, FromB>(self) -> (FromA, FromB) | Разделяет пары на две коллекции |
enumerate | fn enumerate(self) -> Enumerate<Self> | Добавляет индексы |
peekable | fn peekable(self) -> Peekable<Self> | Позволяет посмотреть на следующий элемент |
scan | fn scan<St, B, F>(self, initial_state: St, f: F) -> Scan<Self, St, F> | Итератор с состоянием |
fuse | fn fuse(self) -> Fuse<Self> | Превращает None после первого None |
Методы для двойных итераторов
| Метод | Формат | Назначение |
|---|---|---|
eq | fn eq<I>(self, other: I) -> bool | Проверяет равенство |
ne | fn ne<I>(self, other: I) -> bool | Проверяет неравенство |
lt | fn lt<I>(self, other: I) -> bool | Проверяет "меньше" |
le | fn le<I>(self, other: I) -> bool | Проверяет "меньше или равно" |
gt | fn gt<I>(self, other: I) -> bool | Проверяет "больше" |
ge | fn ge<I>(self, other: I) -> bool | Проверяет "больше или равно" |
cmp | fn cmp<I>(self, other: I) -> Ordering | Сравнивает лексикографически |
partial_cmp | fn partial_cmp<I>(self, other: I) -> Option<Ordering> | Частичное сравнение |
cmp_by | fn cmp_by<I, F>(self, other: I, cmp: F) -> Ordering | Сравнение по функции |
eq_by | fn eq_by<I, F>(self, other: I, eq: F) -> bool | Равенство по функции |
Утилиты
| Метод | Формат | Назначение |
|---|---|---|
rev | fn rev(self) -> Rev<Self> | Обратный порядок (только для DoubleEndedIterator) |
by_ref | fn by_ref(&mut self) -> &mut Self | Заимствует итератор |
Примечание: Большинство адаптеров ленивы - они выполняются только при потреблении.
Трейт Display в Rust
Сводная таблица встроенных типов с реализацией Display
| Тип | Пример вывода | Примечания |
|---|---|---|
i8, i16, i32, i64, i128, isize | -42, 123 | Целочисленные со знаком |
u8, u16, u32, u64, u128, usize | 42, 255 | Целочисленные без знака |
f32, f64 | 3.14, -0.001 | Числа с плавающей точкой |
bool | true, false | Логические значения |
char | 'a', '🦀' | Символы Unicode |
&str, String | "hello", "world" | Строки |
Option<T> | Some(42), None | Если T реализует Display |
Result<T, E> | Ok(42), Err("error") | Если T и E реализуют Display |
() | () | Пустой кортеж |
&T | То же, что T | Ссылки |
Box<T> | То же, что T | Умный указатель |
Rc<T>, Arc<T> | То же, что T | Счетчики ссылок |
Vec<T> | [1, 2, 3] | Если T реализует Display |
[T; N] | [1, 2, 3] | Массивы |
Cell<T>, RefCell<T> | То же, что T | Внутренняя изменяемость |
Mutex<T>, RwLock<T> | То же, что T | Синхронизация |
Path, PathBuf | /home/user/file.txt | Пути файловой системы |
IpAddr, SocketAddr | 192.168.1.1:8080 | Сетевые адреса |
Duration | 2.5s, 500ms | Промежутки времени |
SystemTime, Instant | Временные метки | Время системы |
Способы реализации Display для пользовательских типов
1. Ручная реализация через fmt
use std::fmt; struct Point { x: i32, y: i32, } impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 10, y: 20 }; println!("Точка: {}", p); // Точка: (10, 20) }
2. Использование макроса write! для сложных форматов
use std::fmt; struct Color { red: u8, green: u8, blue: u8, } impl fmt::Display for Color { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "RGB({}, {}, {}) 0x{:02X}{:02X}{:02X}", self.red, self.green, self.blue, self.red, self.green, self.blue) } } fn main() { let color = Color { red: 255, green: 128, blue: 0 }; println!("{}", color); // RGB(255, 128, 0) 0xFF8000 }
3. Для перечислений (enum)
use std::fmt; enum HttpStatus { Ok, NotFound, InternalServerError, } impl fmt::Display for HttpStatus { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match self { HttpStatus::Ok => write!(f, "200 OK"), HttpStatus::NotFound => write!(f, "404 Not Found"), HttpStatus::InternalServerError => write!(f, "500 Internal Server Error"), } } } fn main() { let status = HttpStatus::NotFound; println!("Статус: {}", status); // Статус: 404 Not Found }
4. Для обобщенных типов
use std::fmt; struct Pair<T> { first: T, second: T, } impl<T: fmt::Display> fmt::Display for Pair<T> { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.first, self.second) } } fn main() { let int_pair = Pair { first: 1, second: 2 }; let str_pair = Pair { first: "hello", second: "world" }; println!("{}", int_pair); // (1, 2) println!("{}", str_pair); // (hello, world) }
5. Использование derive макроса (через сторонние крейты)
// В Cargo.toml: // [dependencies] // derive_more = "1.0" use derive_more::Display; #[derive(Display)] #[display(fmt = "Пользователь: {} ({} лет)", name, age)] struct User { name: String, age: u32, } fn main() { let user = User { name: "Анна".to_string(), age: 25 }; println!("{}", user); // Пользователь: Анна (25 лет) }
6. С обработкой форматирования
use std::fmt; struct Temperature { celsius: f64, } impl fmt::Display for Temperature { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { let precision = f.precision().unwrap_or(1); write!(f, "{:.precision$}°C", self.celsius, precision = precision) } } fn main() { let temp = Temperature { celsius: 23.456 }; println!("{}", temp); // 23.5°C println!("{:.2}", temp); // 23.46°C println!("{:.0}", temp); // 23°C }
7. Для типов с владением и заимствованием
use std::fmt; // Для owned типа struct Person { name: String, age: u8, } impl fmt::Display for Person { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{} - {} лет", self.name, self.age) } } // Для типа с ссылками struct Name<'a> { first: &'a str, last: &'a str, } impl<'a> fmt::Display for Name<'a> { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{} {}", self.first, self.last) } } fn main() { let person = Person { name: "Иван".to_string(), age: 30 }; let name = Name { first: "Мария", last: "Петрова" }; println!("{}", person); // Иван - 30 лет println!("{}", name); // Мария Петрова }
Практический пример с комплексной структурой
use std::fmt; struct BlogPost { title: String, author: String, content: String, likes: u32, } impl fmt::Display for BlogPost { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { writeln!(f, "📝 {}", self.title)?; writeln!(f, "✍️ Автор: {}", self.author)?; writeln!(f)?; // Обрезаем контент для краткости let preview = if self.content.len() > 100 { &self.content[..100] } else { &self.content }; write!(f, "{}{}", preview, if self.content.len() > 100 { "..." } else { "" })?; writeln!(f)?; write!(f, "❤️ {} лайков", self.likes) } } fn main() { let post = BlogPost { title: "Мой первый пост в Rust".to_string(), author: "Алексей".to_string(), content: "Сегодня я изучал трейт Display в Rust. Это очень полезный трейт для форматирования вывода...".to_string(), likes: 42, }; println!("{}", post); }
Вывод:
📝 Мой первый пост в Rust
✍️ Автор: Алексей
Сегодня я изучал трейт Display в Rust. Это очень полезный трейт для форматирования вывода...
❤️ 42 лайков
Ключевые особенности реализации Display:
- Требуется только один метод -
fmt - Возвращает
fmt::Result- специализированный Result для форматирования - Использует
Formatterдля гибкого форматирования - Может использовать все возможности форматирования (ширина, точность, выравнивание)
- Должен быть всегда успешным (в отличие от Debug, который может паниковать)
fmt::Result
Особенности:
#![allow(unused)] fn main() { pub type Result = result::Result<(), Error>; }
| Характеристика | Описание |
|---|---|
| Тип | Псевдоним для Result<(), std::fmt::Error> |
| Успех | Ok(()) - форматирование выполнено |
| Ошибка | Err(Error) - ошибка форматирования |
| Error тип | std::fmt::Error - нумератор без вариантов |
| Использование | Всегда через ? оператор |
Примеры:
#![allow(unused)] fn main() { use std::fmt; impl fmt::Display for MyType { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // При ошибке автоматически возвращается Err(Error) write!(f, "Значение: {}", self.value)?; Ok(()) // Явный возврат успеха } } }
Formatter
Основные возможности:
| Метод | Назначение | Пример |
|---|---|---|
write_str(&mut self, s: &str) | Запись строки | f.write_str("hello")? |
write_fmt(&mut self, args: Arguments) | Запись форматирования | f.write_fmt(format_args!("{}", x))? |
Методы для получения параметров форматирования:
| Метод | Возвращает | Описание |
|---|---|---|
width() | Option<usize> | Запрошенная ширина поля |
precision() | Option<usize> | Запрошенная точность |
align() | Option<Alignment> | Выравнивание |
fill() | char | Символ-заполнитель |
sign_plus() | bool | Показывать ли + для положительных |
sign_minus() | bool | Всегда true |
alternate() | bool | Альтернативный формат # |
sign_aware_zero_pad() | bool | Заполнение нулями с учетом знака |
Alignment (выравнивание):
#![allow(unused)] fn main() { pub enum Alignment { Left, // < Center, // ^ Right, // > } }
Практические примеры
1. Простая реализация с обработкой ошибок
#![allow(unused)] fn main() { use std::fmt; struct SafeDisplay(String); impl fmt::Display for SafeDisplay { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Каждый write! возвращает fmt::Result write!(f, "Safe: ")?; // Если ошибка - сразу возврат write!(f, "{}", self.0)?; // Если ошибка - сразу возврат Ok(()) // Все успешно } } }
2. Использование параметров форматирования
use std::fmt; struct FlexibleNumber(i32); impl fmt::Display for FlexibleNumber { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match (f.width(), f.precision()) { (Some(w), Some(p)) => write!(f, "{:0>width$.prec$}", self.0, width = w, prec = p), (Some(w), None) => write!(f, "{:>width$}", self.0, width = w), (None, Some(p)) => write!(f, "{:.prec$}", self.0, prec = p), (None, None) => write!(f, "{}", self.0), } } } fn main() { let num = FlexibleNumber(42); println!("{}", num); // 42 println!("{:5}", num); // 42 println!("{:05}", num); // 00042 println!("{:.2}", num); // 42.00 }
3. Обработка выравнивания и заполнения
#![allow(unused)] fn main() { use std::fmt; struct DecoratedText(&'static str); impl fmt::Display for DecoratedText { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { let width = f.width().unwrap_or(10); let fill = f.fill(); match f.align() { Some(fmt::Alignment::Left) => { write!(f, "{:<width$}", self.0, width = width) }, Some(fmt::Alignment::Center) => { write!(f, "{:^width$}", self.0, width = width) }, Some(fmt::Alignment::Right) => { write!(f, "{:>width$}", self.0, width = width) }, None => write!(f, "{}", self.0), } } } }
4. Комплексный пример с форматированием
use std::fmt; struct SmartFloat(f64); impl fmt::Display for SmartFloat { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { let precision = f.precision().unwrap_or(2); if f.alternate() { // Альтернативный формат с # write!(f, "≈{:.prec$}", self.0, prec = precision) } else if f.sign_plus() { // Всегда показывать знак write!(f, "{:+.prec$}", self.0, prec = precision) } else { // Стандартный формат write!(f, "{:.prec$}", self.0, prec = precision) } } } fn main() { let num = SmartFloat(3.14159); println!("{}", num); // 3.14 println!("{:#}", num); // ≈3.14 println!("{:+}", num); // +3.14 println!("{:.4}", num); // 3.1416 }
Ключевые особенности
Formatter:
- "Писатель" с информацией о форматировании
- Небуферизованный - пишет напрямую в выходной поток
- Предоставляет контекст форматирования (ширина, точность, выравнивание)
- Безопасный - гарантирует корректное UTF-8
fmt::Result:
- Специализированный Result только для форматирования
- Ошибка всегда одна -
fmt::Error(пустой enum) - Идиоматическое использование - распространение через
? - Не требует обработки ошибок - обычно просто пробрасывается
Идиоматический шаблон:
#![allow(unused)] fn main() { impl fmt::Display for MyType { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{}", self.field1)?; // ? для распространения ошибок write!(f, " - ")?; write!(f, "{}", self.field2)?; Ok(()) // Явный возврат успеха в конце } } }
Глава 2
Обобщенные типы
Что такое обобщенные типы
обобщённые типы данных - generics. Это абстрактные подставные типы на место которых возможно поставить какой-либо конкретный тип или другое свойство.
#![allow(unused)] fn main() { fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } }
собственно суть обобщения - как из нескольких функций сделать одну, которая понимает какого типа ей передали данные
Для параметризации типов данных в новой объявляемой функции нам нужно дать имя обобщённому типу — так же, как мы это делаем для аргументов функций. Можно использовать любой идентификатор для имени параметра типа, но мы будем использовать
T, потому что по соглашению имена параметров в Rust должны быть короткими (обычно длиной в один символ), а именование типов в Rust делается в нотации UpperCamelCase.
#![allow(unused)] fn main() { fn largest<T>(list: &[T]) -> &T { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } }
- функция largest является обобщённой по типу
T - имеет один параметр с именем list, который является срезом значений с типом данных
T - возвращает значение этого же типа
T
Для того чтобы сравнивать символы нужно добавить типаж: std::cmp::PartialOrd
#![allow(unused)] fn main() { fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T { }
и вот теперь будет работать со всеми типами, которые можно сравнить
Обобщение типов в структурах
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
а это структура с разными типами
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Обобщение в определении перечислений
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
или
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
В определении методов
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
мы должны объявить
Tсразу послеimpl
может быть все сложнее
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
Типажи
Типаж сообщает компилятору Rust о функциональности, которой обладает определённый тип и которой он может поделиться с другими типами. Можно использовать типажи, чтобы определять общее поведение абстрактным способом. Мы можем использовать ограничение типажа (trait bounds) чтобы указать, что общим типом может быть любой тип, который имеет определённое поведение.
Определение типажа
Определение типажей - это способ сгруппировать сигнатуры методов вместе для того, чтобы описать общее поведение, необходимое для достижения определённой цели.
#![allow(unused)] fn main() { pub trait Summary { fn summarize(&self) -> String; } }
- бъявляем типаж с использованием ключевого слова trait
- название
- pub позволяет крейтам, зависящим от нашего крейта, тоже использовать наш крейт
- Внутри фигурных скобок объявляются сигнатуры методов
Каждый тип, реализующий данный типаж, должен предоставить своё собственное поведение для данного метода
Реализация типажа
#![allow(unused)] fn main() { pub struct NewsArticle { pub headline: String, pub location: String, pub author: String, pub content: String, } impl Summary for NewsArticle { fn summarize(&self) -> String { format!("{}, by {} ({})", self.headline, self.author, self.location) } } pub struct SocialPost { pub username: String, pub content: String, pub reply: bool, pub repost: bool, } impl Summary for SocialPost { fn summarize(&self) -> String { format!("{}: {}", self.username, self.content) } } }
Использование типажа в бинарном крейте
use aggregator::{SocialPost, Summary}; fn main() { let post = SocialPost { username: String::from("horse_ebooks"), content: String::from( "of course, as you probably already know, people", ), reply: false, repost: false, }; println!("1 new post: {}", post.summarize()); }
Поведение по умолчанию
чтобы не требовать реализации всех методов в каждом типе, реализующим данный типаж, можно объявить по умолчанию.
#![allow(unused)] fn main() { pub trait Summary { fn summarize(&self) -> String { String::from("(Read more...)") } } }
а в экземпляре типа объявить impl Summary for NewsArticle {} пустышку, но этого достаточно, чтобы к типу подтянулись все методы типажа имеющие по умолчанию определение
Если у типажа несколько методов, то в impl типа достаточно объявить хотя бы один, чтобы пользоваться всеми остальными, имеющими определение по умолчанию
Типажи как параметры
Тестирование приложений
Синтаксис тестов
Создание модуля тестирования
#![allow(unused)] fn main() { #[cfg(test)] // обязательный атрибут если пишем тест в этом же крейте, который тестируем mod tests {//это такой же модуль как и все другие use super::*; //обязательно для получения доступа к головным функциям #[test]//обязательно перед функцией тестирования fn it_works() { let result = add(2, 2); assert_eq!(result, 4); } } }
Запуск тестирования
cargo test #полный тест
cargo test it_works #перечисление функций теста
cargo test it #тест по контексту, запустит все функции которые имеют в названии it
cargo test -- --ignored #тест функций с пометкой ignore
Функциии проверки
assert!
assert! Возвращает true если выражение вернет true
#![allow(unused)] fn main() { assert!(larger.can_hold(&smaller)); }
assert_eq! и assert_ne!
assert_eq! Возвращает true если условие выполняется, assert_eq! возвращает true если не выполняется
#![allow(unused)] fn main() { assert_eq!(result, 4); }
Сообщение об ошибках в тесте
Второй параметр в макросе assert!
#![allow(unused)] fn main() { #[test] fn greeting_contains_name() { let result = greeting("Carol"); assert!( result.contains("Carol"), "Greeting did not contain name, value was `{result}`" //это сообщение будет выведено в случае ошибки ); } }
При ошибке в протоколе будут выведены все сообщения println!
В теле основной функции все println! будут выведены в протокол
Макрос should_panic
#![allow(unused)] fn main() { #[test] #[should_panic] fn greater_than_100() { Guess::new(200); } }
Перехватывает все panic! в программе. Если panic случился,то тест прошел. Не проверяет какой был panic.
expected
Будет искать по контексту, что написал panic, если значения совпадают,то тест прошел.
#![allow(unused)] fn main() { #[test] #[should_panic(expected = "less than or equal to 100")] fn greater_than_100() { Guess::new(200); } }
Использование Result<T, E> в тестах
#![allow(unused)] fn main() { #[test] fn it_works() -> Result<(), String> { let result = add(2, 2); if result == 4 { Ok(()) } else { Err(String::from("two plus two does not equal four")) } } }
Управление тестами
Не будет выполнять параллельно
cargo test -- --test-threads=1
Выполнит только в обном потоке. Не будет параллельности.
Напечатает все успешные тесты
cargo test -- --show-output
Игнорирование тестов
#![allow(unused)] fn main() { #[test] #[ignore] fn expensive_test() { // code that takes an hour to run } }
для вызова только проигнорированных тестов
cargo test -- --ignored
Организация тестов
Внутри тестируемого крейта
Перед модулем обязательный атрибут
#[cfg(test)]
#![allow(unused)] fn main() { pub fn add(left: u64, right: u64) -> u64 { left + right } #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { let result = add(2, 2); assert_eq!(result, 4); } } }
Интеграционные тесты
В Rust интеграционные тесты являются полностью внешними по отношению к вашей библиотеке. Они используют вашу библиотеку так же, как любой другой код, что означает, что они могут вызывать только функции, которые являются частью публичного API библиотеки.
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
- Внутри проекта создать директорию
tests - Создать несколько файлов с тестами
- В заголовке каждого крейта теста указать
use adder::add_two;— ссылку на тестируемый модуль как внешний - Модуль test создавать не нужно
#![allow(unused)] fn main() { use adder::add_two; #[test] fn it_adds_two() { let result = add_two(2); assert_eq!(result, 4); } }
Создание общих функций для тестов
Файл: tests/common.rs - должен быть в структуре tests. Чтобы модуль common больше не появлялся в результатах выполнения тестов, вместо файла tests/common.rs мы создадим файл tests/common/mod.rs.
#![allow(unused)] fn main() { pub fn setup() { // setup code specific to your library's tests would go here } }
Файлы в подкаталогах каталога tests не компилируются как отдельные крейты или не появляются в результатах выполнения тестов.
Пример вызова в тесте общей функции
#![allow(unused)] fn main() { use adder::add_two; mod common; #[test] fn it_adds_two() { common::setup(); let result = add_two(2); assert_eq!(result, 4); } }
Только библиотечные крейты могут предоставлять функции, которые можно использовать в других крейтах; бинарные крейты предназначены только для самостоятельного запуска.
Структура блочного тестового модуля
tests
├── helpers
│ ├── mod.rs
│ ├── test_module1.rs
│ ├── test_module2.rs
│ └── utils.rs
├── integration_test.rs
└── mod.rs
tests/mod.rs
#![allow(unused)] fn main() { // Объявляем модули (он один, если несколько папок, то перечисляем) mod helpers; //mod integration_test; // Реэкспортируем функции из библиотеки если нужно pub use test_learn::library_function; }
tests/helpers/mod.rs
#![allow(unused)] fn main() { // Объявляем подмодули в папке helpers mod test_module1; mod test_module2; //mod utils; }
Тестовые модули
#![allow(unused)] fn main() { use test_learn::module1; #[cfg(test)] mod tests { use super::*; #[test] fn test_add() { assert_eq!(module1::add(2, 3), 5); assert_eq!(module1::add(-1, 1), 0); assert_eq!(module1::add(0, 0), 0); } #[test] fn test_multiply() { assert_eq!(module1::multiply(2, 3), 6); assert_eq!(module1::multiply(5, 0), 0); assert_eq!(module1::multiply(-2, 3), -6); } #[test] fn test_edge_cases() { assert_eq!(module1::add(i32::MAX, 0), i32::MAX); } } }
Вывод тестов
cargo test
Compiling test_learn v0.1.0 (/home/edge/data/rs/test_learn)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.05s
Running unittests src/lib.rs (target/debug/deps/test_learn-f7d50bd57ebc5cb3)
running 2 tests
test module1::tests::test_add ... ok
test module2::tests::test_calculator_new ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-a9701079e41f5aba)
running 2 tests
test test_integration ... ok
test test_library_function ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/mod.rs (target/debug/deps/mod-26cc964da696d58a)
running 6 tests
test helpers::test_module1::tests::test_add ... ok
test helpers::test_module1::tests::test_edge_cases ... ok
test helpers::test_module2::tests::test_calculator_sequence ... ok
test helpers::test_module2::tests::test_calculator_add ... ok
test helpers::test_module1::tests::test_multiply ... ok
test helpers::test_module2::tests::test_calculator_new ... ok
test result: ok. 6 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests test_learn
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
cargo-test finished at Mon Nov 3 15:02:08, duration 0.10 s
Глава 3
Консольное приложение
Первая задача - заставить minigrep принимать два аргумента командной строки: путь к файлу и строку для поиска.
cargo run -- searchstring example-filename.txt
итераторы генерируют серию значений, и мы можем вызвать метод collect у итератора, чтобы создать из него коллекцию, например вектор, который будет содержать все элементы, произведённые итератором.
Первый шаг программы
- Подключили библиотеку для работы с окружением и аргументами Описание библиотеки ENV
- Подключили библиотеку для работы с файлами Описание библиотеки FS
use std::env; use std::fs; fn main() { let args: Vec<String> = env::args().collect(); // dbg!(args); let query = &args[1]; let file_path = &args[2]; println!("Поисковый запрос {query}"); println!("В файле {file_path}"); let contents = fs::read_to_string(file_path) .expect("Файл должен быть доступен для чтения"); println!("Файл содержит текст:\n{contents}"); }
Рефакторинг программы
- Разделите код программы на два файла main.rs и lib.rs. Перенесите всю логику работы программы в файл lib.rs.
- Функциональные обязанности, которые остаются в функции main:
- Вызов логики разбора командной строки со значениями аргументов
- Настройка любой другой конфигурации
- Вызов функции run в lib.rs
- Обработка ошибки, если run возвращает ошибку
Выделение структуры
#![allow(unused)] fn main() { struct Config { query: String, file_path: String, } }
Создание конструктора new
#![allow(unused)] fn main() { impl Config { fn new(args: &[String]) -> Config { let query = args[1].clone(); let file_path = args[2].clone(); Config { query, file_path } } } }
Изменение вызова
#![allow(unused)] fn main() { let config = Config::new(&args); }
Обработка ошибок
Поставить проверку и panic
#![allow(unused)] fn main() { impl Config { fn new(args: &[String]) -> Config { if args.len() < 3 { panic!("Не достаточно аргументов: -- 1:строка поиска 2:имя файла"); } }
Обработать через Result
#![allow(unused)] fn main() { impl Config { fn new(args: &[String]) -> Result<Config, &'static str> { if args.len() < 3 { return Err("Не достаточно аргументов: -- 1:строка поиска 2:имя файла"); } let query = args[1].clone(); let file_path = args[2].clone(); Ok(Config { query, file_path }) } } }
в main вызываем:
#![allow(unused)] fn main() { let config = Config::build(&args).unwrap_or_else(|err| { println!("Problem parsing arguments: {err}"); process::exit(1); }); }
Разделение на lib.rs и main.rs
src/main.rs
use std::env; //для чтения переменных окружения use std::process; //для завершения приложения use minigrep::Config; // подключаем lib fn main() { let args: Vec<String> = env::args().collect();//считываем аргументы из командной строки let config = Config::new(&args).unwrap_or_else(|err| { //инициализируем открытие файла с проверкой на ошибки eprintln!("Проблема распознавания аргументов: {err}");//выводим ошибки в поток ошибок process::exit(1); //закрываем программу если ошибка }); // dbg!(args); println!("Поисковый запрос: [{}]", config.query); println!("В файле: [{}]", config.file_path); let key = "PATH"; //это вывод содержимого переменной окружения match env::var(key) { Ok(val) => println!("Значение переменной {key}: {val:?}"), Err(e) => println!("couldn't interpret {key}: {e}"), } if let Err(e) = minigrep::run(config) { //выполняем поиск и проверяем возможные ошибки eprintln!("Приложение содержит ошибку {e}"); //если ошибка, то выводим информацию в поток ошибок process::exit(1); } }
src/lib.rs
#![allow(unused)] fn main() { use std::error::Error; use std::fs; use std::env; pub struct Config { //структура для работы с ключами pub query: String, //структура и все ее компоненты pub pub file_path: String, pub ignore_case: bool, } impl Config { //инициализация структуры по Config::new pub fn new(args: &[String]) -> Result<Config, &'static str> {//метод инициализации pub if args.len() < 3 { return Err("Не достаточно аргументов: -- 1:строка поиска 2:имя файла"); } let query = args[1].clone();//создаю копии элементов для владения let file_path = args[2].clone(); let ignore_case = env::var("IGNORE_CASE").is_ok(); Ok(Config { query, file_path, ignore_case, }) } } pub fn run(config: Config) -> Result<(), Box<dyn Error>> {//запуск run с параметрами Config let contents = fs::read_to_string(config.file_path)?;// если ошибка передаем в main let results = if config.ignore_case {//проверяем наличие переменной среды search_case_insensitive(&config.query, &contents) } else { search(&config.query, &contents) }; for line in results { println!("{line}"); } Ok(()) } fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {//поиск чувствительный к регистру let mut result = Vec::new(); for line in contents.lines() { if line.contains(query) { result.push(line); } } result } fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {//поиск нечувствительный к регистру let mut result = Vec::new(); let query = query.to_lowercase(); for line in contents.lines() { if line.to_lowercase().contains(&query) { result.push(line); } } result } //тесты библиотеки #[cfg(test)] mod tests { use super::*; #[test] fn one_result() { let query = "duct"; let contents = "\ Rust: safe, fast, productive. Pick three. uduct mabuct"; assert_eq!( vec!["safe, fast, productive.", "uduct mabuct"], search(query, contents) ); } } #[test] fn case_sensitive() { let query = "duct"; let contents = "\ Rust: safe, fast, productive. Pick three. Duct tape."; assert_eq!(vec!["safe, fast, productive."], search(query, contents)); } #[test] fn case_insensitive() { let query = "rUsT"; let contents = "\ Rust: safe, fast, productive. Pick three. Duct tape. Trust me."; assert_eq!( vec!["Rust:", "Trust me."], search_case_insensitive(query, contents) ); } }
Библиотека std::env в Rust предоставляет функции для работы с окружением процесса, в основном:
Основное назначение:
- Аргументы командной строки - чтение аргументов, переданных программе
- Переменные окружения - получение и установка env-переменных
- Информация о процессе - рабочий каталог, информация о ОС
Основные функции:
#![allow(unused)] fn main() { use std::env; // 1. Аргументы командной строки let args: Vec<String> = env::args().collect(); // ["program_name", "arg1", "arg2"] // 2. Переменные окружения let path = env::var("PATH").unwrap(); // Получить переменную env::set_var("MY_VAR", "value"); // Установить переменную // 3. Рабочий каталог let current_dir = env::current_dir().unwrap(); // Текущая директория env::set_current_dir("/path"); // Сменить директорию // 4. Информация о ОС let os = env::consts::OS; // "linux", "windows", "macos" }
Типичные use-cases:
- Конфигурация приложения через env-переменные
- Парсинг аргументов CLI
- Определение ОС для условной компиляции
- Получение метаинформации о среде выполнения
Это одна из самых часто используемых библиотек в Rust для взаимодействия со средой выполнения.
Note
Полезное замечание: если программе в качестве параметров нужно принимать Юникод, то нужно использовать библиотеку
std::env::args_os
std::fs в Rust — это модуль для работы с файловой системой.
Обеспечивает операции для работы с файлами и директориями.
Основные возможности:
1. Работа с файлами
#![allow(unused)] fn main() { use std::fs; // Чтение файлов let content = fs::read_to_string("file.txt")?; let bytes = fs::read("file.bin")?; // Запись файлов fs::write("file.txt", "content")?; // Открытие файлов с опциями let file = fs::File::open("file.txt")?; let file = fs::File::create("new_file.txt")?; }
2. Работа с директориями
#![allow(unused)] fn main() { // Создание директории fs::create_dir("path")?; fs::create_dir_all("nested/path")?; // Чтение содержимого директории for entry in fs::read_dir(".")? { let entry = entry?; println!("{}", entry.file_name()); } // Удаление fs::remove_dir("path")?; fs::remove_file("file.txt")?; }
3. Метаданные и информация
#![allow(unused)] fn main() { let metadata = fs::metadata("file.txt")?; println!("Size: {}", metadata.len()); println!("Is dir: {}", metadata.is_dir()); // Проверка существования if fs::try_exists("file.txt")?.is_ok() { println!("File exists!"); } }
4. Операции с путями
#![allow(unused)] fn main() { // Переименование/перемещение fs::rename("old.txt", "new.txt")?; // Символические ссылки (Unix) #[cfg(unix)] fs::soft_link("original", "link")?; // Жесткие ссылки fs::hard_link("original", "link")?; }
Типичные use-cases:
- Чтение конфигурационных файлов
- Логирование в файлы
- Загрузка/сохранение данных
- Работа с временными файлами
- Управление кэшем приложения
- Инициализация структуры директорий
Пример полного использования:
use std::fs; use std::io; fn main() -> io::Result<()> { // Создать структуру директорий fs::create_dir_all("data/cache")?; // Записать данные fs::write("data/config.json", r#"{"key": "value"}"#)?; // Прочитать данные let config = fs::read_to_string("data/config.json")?; // Получить список файлов for entry in fs::read_dir("data")? { println!("File: {:?}", entry?.file_name()); } Ok(()) }
std::fs — это основной инструмент для любого взаимодействия с файловой системой в Rust-приложениях.
Глава 5
Указатель — это общая концепция для переменной, которая содержит адрес участка памяти.
Умные указатели, с другой стороны, являются структурами данных, которые не только действуют как указатель, но также имеют дополнительные метаданные и возможности. Концепция умных указателей не уникальна для Rust: умные указатели возникли в C++ и существуют в других языках. В Rust есть разные умные указатели, определённые в стандартной библиотеке, которые обеспечивают функциональность, выходящую за рамки ссылок. Одним из примеров, который мы рассмотрим в этой главе, является тип умного указателя reference counting (подсчёт ссылок). Этот указатель позволяет иметь несколько владельцев с помощью отслеживания количества владельцев и, когда владельцев не остаётся, очищает данные.
Box
Умный указатель
Box<T>в Rust используется для хранения данных в куче (heap) вместо стека (stack). Вот основные аспекты:
Тип
Box<T>является умным указателем, поскольку он реализует трейтDeref, который позволяет обрабатывать значенияBox<T>как ссылки. Когда значениеBox<T>выходит из области видимости, данные кучи, на которые указываетbox, также очищаются благодаря реализации типажаDrop.
Основное назначение Box:
- Хранение данных в куче - когда данные слишком велики для стека
- Рекурсивные структуры данных - когда размер типа неизвестен на этапе компиляции
- Трейт-объекты - для динамической диспетчеризации
Примеры использования:
1. Базовое использование (как в вашем примере)
fn main() { let b = Box::new(5); // i32 хранится в куче println!("b = {}", b); // Автоматическое разыменование println!("*b = {}", *b); // Явное разыменование }
2. Рекурсивные структуры данных
#[derive(Debug)] enum List { Cons(i32, Box<List>), Nil, } fn main() { let list = List::Cons(1, Box::new(List::Cons(2, Box::new(List::Nil)))); println!("{:?}", list); }
3. Большие структуры данных
struct BigData { data: [u8; 1000000], // 1MB данных - слишком много для стека } fn main() { let big_box = Box::new(BigData { data: [0; 1000000] }); // Данные хранятся в куче, избегая переполнения стека }
4. Трейт-объекты
trait Animal { fn speak(&self); } struct Dog; struct Cat; impl Animal for Dog { fn speak(&self) { println!("Woof!"); } } impl Animal for Cat { fn speak(&self) { println!("Meow!"); } } fn main() { let animals: Vec<Box<dyn Animal>> = vec![ Box::new(Dog), Box::new(Cat), ]; for animal in animals { animal.speak(); } }
Ключевые особенности:
- Владение -
Boxвладеет данными в куче - Автоматическое освобождение - память освобождается при выходе из области видимости
- Нулевая стоимость - в runtime
Boxведет себя как обычная ссылка - Безопасность - гарантии владения и заимствования Rust
Deref
Трейт
Deref, позволяет изменить поведение оператора разыменования*
Реализовав
Derefтаким образом, что умный указатель может рассматриваться как обычная ссылка, вы можете писать код, оперирующий ссылками, а также использовать этот код с умными указателями.
Разыменование типа
let y = &x;— создали ссылкуassert_eq!(5, *y);— разыменовали ссылкуlet y = Box::new(x);это идентичноlet y = &x;и там и там ссылка
Повторим Box<T>
- Создадим структуру
- Напишем конструктор new
#![allow(unused)] fn main() { struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } }
- Определим метод
defer
#![allow(unused)] fn main() { use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } }
Все! Теперь assert_eq!(5, *y) разыменовывает аналогично.
Неявные разыменованные приведения с функциями и методами
Например,
derefcoercion может преобразовать&Stringв&str, потому чтоStringреализует признакDeref, который возвращает&str.
Типаж DerefMut для переопределения оператора * у изменяемых ссылок.
Rust выполняет разыменованное приведение, когда находит типы и реализации типажей в трёх случаях:
- Из типа
&Tв тип&Uкогда верноT: Deref<Target=U> - Из типа
&mut Tв тип&mut Uкогда верноT: DerefMut<Target=U> - Из типа
&mut Tв тип&Uкогда верноT: Deref<Target=U>
Struct-кортежи (tuple structs) - это гибрид между обычными структурами и кортежами.
Основные особенности:
1. Синтаксис объявления
#![allow(unused)] fn main() { // Обычная структура struct Point { x: i32, y: i32, } // Struct-кортеж struct PointTuple(i32, i32); // Struct-кортеж с одним полем (новый тип) struct Meters(f64); }
2. Создание экземпляров
fn main() { // Обычная структура let p1 = Point { x: 10, y: 20 }; // Struct-кортеж let p2 = PointTuple(10, 20); let distance = Meters(5.5); }
3. Доступ к полям
fn main() { let point = PointTuple(10, 20); let meters = Meters(5.5); // Доступ по индексу (как у кортежей) println!("x = {}", point.0); println!("y = {}", point.1); println!("meters = {}", meters.0); }
Отличия от других структур:
От обычных структур (struct):
struct Regular { x: i32, y: i32 } struct TupleStruct(i32, i32); fn main() { let regular = Regular { x: 1, y: 2 }; let tuple_struct = TupleStruct(1, 2); // Обычная структура - доступ по имени println!("{}", regular.x); // Struct-кортеж - доступ по индексу println!("{}", tuple_struct.0); }
От кортежей (tuple):
fn main() { // Обычный кортеж let tuple: (i32, i32) = (10, 20); // Struct-кортеж struct Point(i32, i32); let point = Point(10, 20); // Кортеж - анонимный тип // Struct-кортеж - именованный тип }
Практические примеры:
1. Создание новых типов (Newtype pattern)
struct UserId(u64); struct Email(String); fn create_user(id: UserId, email: Email) { println!("User {}: {}", id.0, email.0); } fn main() { let id = UserId(12345); let email = Email("user@example.com".to_string()); create_user(id, email); }
2. Группировка связанных данных
struct Color(u8, u8, u8); struct Bounds(usize, usize); fn main() { let red = Color(255, 0, 0); let screen = Bounds(1920, 1080); println!("RGB: {}, {}, {}", red.0, red.1, red.2); println!("Resolution: {}x{}", screen.0, screen.1); }
3. Pattern matching
struct Point(i32, i32); fn check_point(point: Point) { match point { Point(0, 0) => println!("Origin"), Point(x, 0) => println!("On x-axis at {}", x), Point(0, y) => println!("On y-axis at {}", y), Point(x, y) => println!("At ({}, {})", x, y), } } fn main() { check_point(Point(0, 0)); check_point(Point(5, 0)); check_point(Point(3, 4)); }
Преимущества struct-кортежей:
- Лёгкость написания - меньше boilerplate кода
- Newtype pattern - создание семантически новых типов
- Удобство для простых агрегатов - когда имена полей не важны
- Совместимость с кортежами - можно использовать в pattern matching
Когда использовать:
- Для создания новых типов (newtype)
- Когда данные логически связаны, но именованные поля избыточны
- Для простых контейнеров с небольшим количеством полей
- Когда нужен именованный тип, но синтаксис кортежа удобнее
Drop
Drop, позволяет регулировать, что происходит, когда значение вот-вот выйдет из области видимости. Вы можете реализовать типаж Drop для любого типа, а также использовать этот код для высвобождения ресурсов, таких как файлы или сетевые соединения.
Типаж
Dropтребует от вас реализации одного метода drop, который принимает изменяемую ссылку наself.
#![allow(unused)] fn main() { struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } }
Раннее удаление значения с помощью std::mem::drop
Rustне позволяет вызвать метод типажа Drop вручную; вместо этого вы должны вызвать функциюstd::mem::dropпредоставляемую стандартной библиотекой, если хотите принудительно удалить значение до конца области видимости.
use std::mem::drop fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created"); drop(c); println!("CustomSmartPointer dropped before the end of main"); }
Rc<T>, умный указатель с подсчётом ссылок
бывают случаи, когда у одного значения может быть несколько владельцев. Например, в Графовых структурах может быть несколько рёбер, указывающих на один и тот же узел.
Warning
тип Rust
Rc<T>— позволяет явно включить множественное владение. ТипRc<T>отслеживает количество ссылок на значение, чтобы определить, используется ли оно ещё. Если ссылок на значение нет, значение может быть очищено и при этом ни одна ссылка не станет недействительной.
Note
Тип
Rc<T>используется, когда мы хотим разместить в куче некоторые данные для чтения несколькими частями нашей программы и не можем определить во время компиляции, какая из частей завершит использование данных последней.
Warning
Rc<T>используется только в однопоточных сценариях.
Не рабочий пример
RUST это просто не допустит

b и c совместно владеют хвостом a = 5 и 10
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let a = Cons(5, Box::new(Cons(10, Box::new(Nil)))); let b = Cons(3, Box::new(a)); let c = Cons(4, Box::new(a)); }
Решение через Rc
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
- a, b, c объявляются как Rc
- в
bклонируетсяaRc::clone - в
cклонируетсяaRc::CLOSE
Вызов Rc::clone только увеличивает счётчик ссылок,
Rc::strong_count — подсчитывает количество ссылок
#![allow(unused)] fn main() { println!("count after creating b = {}", Rc::strong_count(&a)); }
С помощью неизменяемых ссылок, тип Rc
позволяет обмениваться данными между несколькими частями вашей программы только для чтения данных.
Refcell
Warning
Внутренняя изменяемость - это паттерн проектирования Rust, который позволяет вам изменять данные даже при наличии неизменяемых ссылок на эти данные;
Для изменения данных паттерн использует
unsafeкод внутри структуры данных, чтобы обойти обычные правила Rust
Применение правил заимствования во время выполнения с помощью RefCell<T>
В отличие от
Rc<T>типRefCell<T>предоставляет единоличное владение данными, которые он содержит.
Правила заимствования
- В любой момент времени вы можете иметь либо одну изменяемую ссылку либо сколько угодно неизменяемых ссылок (но не оба типа ссылок одновременно).
- Ссылки всегда должны быть действительными.
типа
Box<T>— применяются на этапе компиляции
RefCell<T>применяется во время работы программы
Note
Тип
RefCell<T>полезен, когда вы уверены, что ваш код соответствует правилам заимствования, но компилятор не может понять и гарантировать этого.
Подобно типу
Rc<T>, типRefCell<T>предназначен только для использования в однопоточных сценариях
Список причин выбора типов Box<T>, Rc<T> или RefCell<T>:
- Тип
Rc<T>разрешает множественное владение одними и теми же данными; типыBox<T>иRefCell<T>разрешают иметь единственных владельцев. - Тип
Box<T>разрешает неизменяемые или изменяемые владения, проверенные при компиляции; - тип
Rc<T>разрешает только неизменяемые владения, проверенные при компиляции; - тип
RefCell<T>разрешает неизменяемые или изменяемые владения, проверенные во время выполнения. - Поскольку
RefCell<T>разрешает изменяемые заимствования, проверенные во время выполнения, можно изменять значение внутриRefCell<T>даже еслиRefCell<T>является неизменным.
мок объекты
Инсценировочные (mock) объекты — это особый тип тестовых дублёров, которые сохраняют данные происходящих во время теста действий тем самым позволяя вам убедиться впоследствии, что все действия были выполнены правильно.
У типа RefCell<T>, мы используем методы borrow и borrow_mut, которые являются частью безопасного API, который принадлежит RefCell<T> вместо & и &mut
Week
Когда вы вызываете
Rc::downgrade, вы получаете умный указатель типаWeak<T>. Вместо того чтобы увеличитьstrong_countв экземпляреRc<T>на 1, вызовRc::downgradeувеличиваетweak_countна 1.
Глава 6
Многопоточность
Многопоточное программирование, когда разные части программы выполняются независимо,
Note
Используя владение и проверку типов, многие ошибки многопоточности являются ошибками времени компиляции в Rust, а не ошибками времени выполнения.
Rust использует модель реализации потоков 1:1, при которой одному потоку операционной системы соответствует ровно один "языковой" поток.
Создание нового потока с помощью spawn
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { //создание потока for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
thread::spawn(|| {— создание потокаthread::sleep(— задержка потокаjoin— дождаться завершения всех потоковhandle.join().unwrap();
join отстанавливает выполнение потока до завершения потока с указателем
handle.join().unwrap();
Использование move-замыканий в потоках
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {v:?}"); }); handle.join().unwrap(); }
нужно передать во владение переменную в поток
Каналы
Канал считается закрытым , если либо передающая, либо принимающая его половина уничтожена.
Библиотека use std::sync::mpsc;
use std::sync::mpsc; fn main() { let (tx, rx) = mpsc::channel(); }
mpscозначает несколько производителей, один потребитель (multiple producer, single consumer).
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); //создали канал с приемником и передатчиком thread::spawn(move || { //создали поток и передали в него tx let val = String::from("hi"); tx.send(val).unwrap(); //отправили сообщение в канал }); let received = rx.recv().unwrap(); //получили сообщение из канала println!("Got: {received}"); }
try_recv— ждет поступления в канал и не блокирует потокrecv— блокирует поток до получения сообщения
Получение через итератор
#![allow(unused)] fn main() { for received in rx { println!("Got: {received}"); } }
Будет получать пока не закроется канал
передатчики можно клонировать
let tx1 = tx.clone();
создавать новые потоки и запускать отправку в канал
Общие данные
Мьютексы предоставляют доступ к данным из одного потока (за раз)
Mutex - это сокращение от взаимное исключение (mutual exclusion), так как мьютекс позволяет только одному потоку получать доступ к некоторым данным в любой момент времени.
два правила мьютекс:
- Перед тем как попытаться получить доступ к данным необходимо получить блокировку.
- Когда вы закончили работу с данными, которые защищает мьютекс, вы должны разблокировать данные, чтобы другие потоки могли получить блокировку.
Mutex<T> API
use std::sync::Mutex; — библиотека
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {m:?}"); }
получим m = Mutex { data: 6, poisoned: false, .. }
Разделение Mutex<T> между множеством потоков
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex}; //поможет при многопоточности }
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Warning
Используя эту стратегию, вы можете разделить вычисления на независимые части, разделить эти части на потоки, а затем использовать
Mutex<T>, чтобы каждый поток обновлял конечный результат своей частью кода.
Типажи Sync и Send
в язык встроены две концепции многопоточности:
std::markerтипажиSyncиSend
Разрешение передачи во владение между потоками с помощью Send
Маркерный типаж Send указывает, что владение типом реализующим Send, может передаваться между потоками.
Любой тип полностью состоящий из типов Send автоматически помечается как Send. Почти все примитивные типы являются Send, кроме сырых указателей.
Разрешение доступа из нескольких потоков с Sync
Маркерный типаж Sync указывает, что на тип реализующий Sync можно безопасно ссылаться из нескольких потоков.
Подобно Send, примитивные типы являются типом Sync, а типы полностью скомбинированные из типов Sync, также являются Sync типом.
Глава 4
Замыкания
Замыкания в Rust - это анонимные функции, которые можно сохранять в переменных или передавать в качестве аргументов другим функциям. Вы можете создать замыкание в одном месте, а затем вызвать его в каком-нибудь другом, чтобы выполнить обработку в ином контексте. В отличие от функций, замыкания могут использовать значения из области видимости в которой они были определены.
Хорошая функция unwrap_or_else(|| self.most_stocked())
Очень любит замыкания!
Если значение на входе не содержит Some, то выполнит замыкание в скобках.
|| self.most_stocked():
||— между этими полосами передаем параметры в замыканиеself.most_stocked()— собственно сама функция замыкания
Замыкания обычно не требуют аннотирования типов входных параметров или возвращаемого значения, как это делается в функциях fn
Если нужно добавить аннотацию, то выглядит так:
#![allow(unused)] fn main() { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; }
или так
#![allow(unused)] fn main() { fn add_one_v1 (x: u32) -> u32 { x + 1 } let add_one_v2 = |x: u32| -> u32 { x + 1 }; let add_one_v3 = |x| { x + 1 }; let add_one_v4 = |x| x + 1 ; }
это замыкание
#![allow(unused)] fn main() { let clos1 = |x,y| for _ in 1..=y {print!("{x}")}; clos1("=",20); }
Замыкание самостоятельно определяет, какой из этих способов владения использовать, исходя из того, что тело функции делает с полученными значениями.
Ссылка на входе (не изменяемое)
#![allow(unused)] fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let only_borrows = || println!("From closure: {list:?}"); println!("Before calling closure: {list:?}"); only_borrows(); println!("After calling closure: {list:?}"); }
Изменение значения
#![allow(unused)] fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let mut only_borrows = || list.push(7); only_borrows(); println!("After calling closure: {list:?}"); }
Порождение нового потока (move)
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); thread::spawn(move || println!("From thread: {list:?}")) .join() .unwrap(); }
Перемещение захваченных значений из замыканий
Тело замыкания может делать любое из следующих действий: перемещать захваченное значение из замыкания, изменять захваченное значение, не перемещать и не изменять значение или вообще ничего не захватывать из среды.
Трейты замыканий
FnOnceприменяется к замыканиям, которые могут быть вызваны один раз.
Замыкание, которое перемещает захваченные значения из своего тела, реализует только
FnOnce
#![allow(unused)] fn main() { impl<T> Option<T> { pub fn unwrap_or_else<F>(self, f: F) -> T where F: FnOnce() -> T //будет вызвано только один раз { match self { Some(x) => x, None => f(), } } } }
FnMutприменяется к замыканиям, которые не перемещают захваченные значения из своего тела, но могут изменять захваченные значения.
#![allow(unused)] fn main() { list2.sort_by_key(|r| r.width); println!("{list2:#?}"); }
Fnприменяется к замыканиям, которые не перемещают захваченные значения из своего тела и не модифицируют захваченные значения, а также к замыканиям, которые ничего не захватывают из своего окружения.
Итераторы
Итератор отвечает за логику перебора элементов и определение момента завершения последовательности.
В Rust итераторы ленивые (lazy), то есть они не делают ничего, пока вы не вызовете специальные методы, потребляющие итератор, чтобы задействовать его.
Итератор это просто счетчик со ссылкой на объект со значениями
#![allow(unused)] fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {val}"); } }
Типаж Iterator и метод next
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // methods with default implementations elided } }
Если мы хотим создать итератор, который становится владельцем
v1и возвращает принадлежащие ему значения, мы можем вызватьinto_iterвместоiter. Точно так же, если мы хотим перебирать изменяемые ссылки, мы можем вызватьiter_mutвместоiter.
#![allow(unused)] fn main() { let v2_iter = v1.iter(); let total: i32 = v2_iter.sum(); println!("{}",total); }
это тоже работает
Методы, которые создают другие итераторы
Адаптеры итераторов - это методы, определённые для трейта Iterator, которые не потребляют итератор. Вместо этого они создают различные итераторы, изменяя некоторые аспекты исходного итератора.
Итератор нужно обязательно потребить или будут ошибка
Создает новый итератор:
#![allow(unused)] fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
filter
#![allow(unused)] fn main() { #[derive(PartialEq, Debug)] struct Shoe { size: u32, style: String, } fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> { //получает на вход вектор и захватывает его -> возвращает вектор удовлетворяющий условию shoes.into_iter().filter(|s| s.size == shoe_size).collect() //собирает коллекцию с помощью фильтра } }
Коррекция листинга приложения
#![allow(unused)] fn main() { let config = Config::build(env::args()).unwrap_or_else(|err| { eprintln!("Problem parsing arguments: {err}"); process::exit(1); }); //env::args() — возвращает итератор И не нужно создавать вектор }
и поменяем вызов функции
#![allow(unused)] fn main() { impl Config { fn build( mut args: impl Iterator<Item = String>, ) -> Result<Config, &'static str> { // --snip-- }